








 超级会员免费看
超级会员免费看

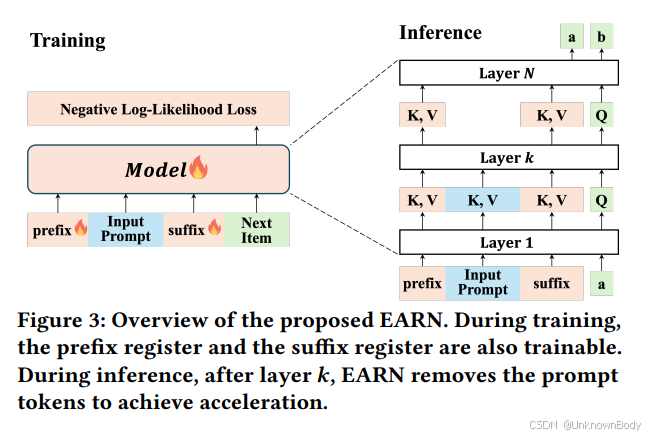
文章主要内容总结
- 研究背景:基于大型语言模型(LLM)的生成式推荐(LLMRec)虽性能优异,但因KV缓存的巨大计算开销和内存压力,推理延迟高,限制了实际应用(如需要毫秒级响应的工业场景)。
- 现有方法局限:
- 缓存压缩:通过移除次要KV对减少缓存,但推荐任务解码步骤少(生成1-5个token),加速效果有限。
- 提示压缩:通过缩短输入序列减少初始KV缓存,但难以区分推荐任务中用户交互的重要性,易丢失关键信息导致准确性下降。
- 核心发现:通过分析LLMRec的注意力分数分布,发现两个关键特征:
- 层间注意力稀疏度反转:早期层注意力分布密集(含丰富信息),后期层稀疏(冗余度高)。
- 双重注意力 sink 现象:注意力分数集中在输入序列的头部和尾部token。
- 提出方法(EARN):
- 引入前缀寄存器(prefix register)和后缀寄存器(suffix register),均为可学习的虚拟token,分别置于输入序列的首尾。
- 早期层(

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1450
1450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











