







对AI应用感兴趣的小伙伴可关注微信公众号:Mario量化
1、引言
在这期内容中,我们探索人工智能技术如何应用于另一个有趣的领域:预测数字生成。
3、数据收集与处理
首先,下载2005年至今的所有数据。
预处理之后形成以下数据集,前面6个数是红球而第7个数是蓝球
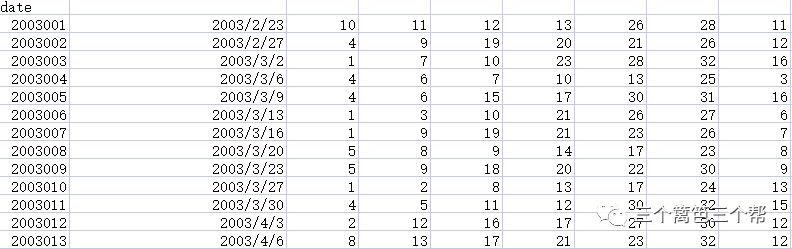
4、预测模型
我们采用神经网络算法中最先进的Transformer作为模型,但是在输入模型之前,我们需要进行一些预处理,具体如下:
1、数字表示转化为独热编码:我们需要将数字表示转换为独热编码,以便让AI能够更好地学习。我们采用以下方式进行独热编码:

这样,原本每期7个数字的数据将被转换成每期49个独热编码。
2、数据和制作标签:我们的模型应该被设计成:输入过去29天的历史数据,形成的独热编码,来预测未来下一次的独热编码。为实现这个理念,我们对数据进行了滑窗提取,每次滑窗提取过去29天的历史数据,并对应需要预测的未来一天的真实值。具体代码如下:
df = pd.read_csv('./basedata.csv').dropna()
train_df = np.array(df)
samples = []
label = []
for j in range(len(train_df)):
if j > 27:
feat = train_df[j - 28:j + 1][:, 2:]
l = train_df[j - 27:j + 2][-1:, 2:]
samples.append(feat)
label.append(l)
DATA = np.array(samples).astype(int)
LABEL = np.array(label).astype(int)
LABEL = np.squeeze(LABEL, axis=(1,))独热编码处理:
num_classes_first_six = 33
num_classes_last_one = 16
encoded_data = np.zeros((DATA.shape[0], DATA.shape[1], num_classes_first_six + num_classes_last_one), dtype=int)
for i in range(DATA.shape[0]):
for j in range(DATA.shape[1]):
for k in range(DATA.shape[2]):
num = int(DATA[i, j, k])
if k < 6:
encoded_data[i, j, num - 1] = 1
else:
encoded_data[i, j, num_classes_first_six + num - 1] = 1
train_D = torch.tensor(encoded_data, dtype=torch.float32)
num_classes_first_six = 33
num_classes_last_one = 16
encoded_data = np.zeros((LABEL.shape[0], num_classes_first_six + num_classes_last_one), dtype=int)
for i in range(LABEL.shape[0]):
for j in range(LABEL.shape[1]):
num = int(LABEL[i, j])
if j < 6:
encoded_data[i, num - 1] = 1
else:
encoded_data[i, num_classes_first_six + num - 1] = 1
train_L = torch.tensor(encoded_data, dtype=torch.float32)3、基于PyTorch框架,由于我们的输入维度是49,我们选择了以下参数:
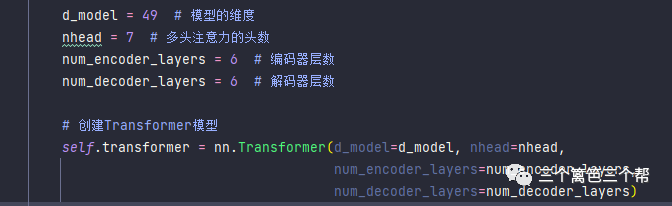
进入Transformer解码之后,我们会对高阶特征进行降维,将特征区间映射到标签区间。我们的标签区间同样是一个49的独热编码。
具体步骤如下:

5、AI学习情况
我们采用前3000期彩票数据进行训练,而将后续的彩票期数用于测试。
测试结果如下所示:
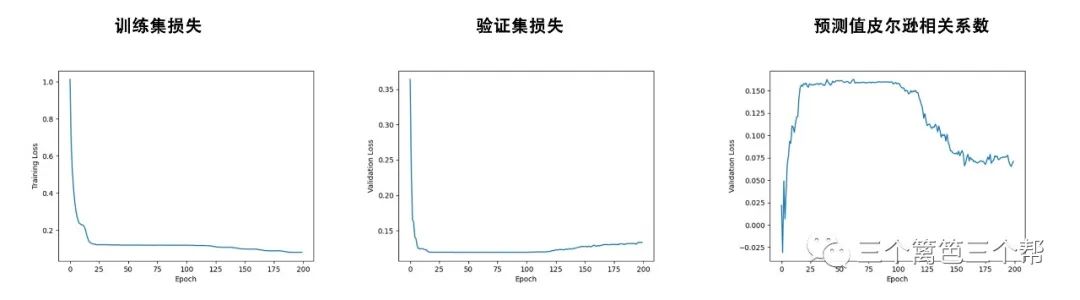
总结:在经过大约100个epoch的训练后,模型达到了约0.15的相关性水平。随后的训练导致了过拟合现象的出现,因此我们建议考虑提前停止训练,以避免过拟合的问题。
6、应用
由于预测值是一个49的独热矩阵,我们要将其转化成数字表示
数据在这里下载:百度网盘 请输入提取码
提取码:1234
完整训练代码:
# from transformers import EsmModel, EsmTokenizer, EsmConfig
# from sklearn.model_selection import train_test_split
# from sklearn import metrics
# from sklearn.metrics import mean_squared_error, r2_score
# import seaborn as sns
# from sklearn.metrics import accuracy_score
# from sklearn.preprocessing import OneHotEncoder
import numpy as np
import pandas as pd
import torch
from sklearn import metrics
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Dataset
from torchvision.transforms import Normalize
from sklearn.model_selection import KFold
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset, Dataset
from torch.optim import lr_scheduler
from tqdm import tqdm
from sklearn.metrics import precision_recall_curve, auc
from torch.utils.data import TensorDataset, DataLoader, WeightedRandomSampler
import time
from tqdm import tqdm
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
df = pd.read_csv('./basedata.csv').dropna()
train_df = np.array(df.iloc[:-300])
samples = []
label = []
for j in range(len(train_df)):
if j > 28:
feat = train_df[j - 29:j + 1][:, 2:]
l = train_df[j - 28:j + 2][-1:, 2:]
samples.append(feat)
label.append(l)
DATA = np.array(samples).astype(int)
LABEL = np.array(label).astype(int)
LABEL = np.squeeze(LABEL, axis=(1,))
num_classes_first_six = 33
num_classes_last_one = 16
encoded_data = np.zeros((DATA.shape[0], DATA.shape[1], num_classes_first_six + num_classes_last_one), dtype=int)
for i in range(DATA.shape[0]):
for j in range(DATA.shape[1]):
for k in range(DATA.shape[2]):
num = int(DATA[i, j, k])
if k < 6:
encoded_data[i, j, num - 1] = 1
else:
encoded_data[i, j, num_classes_first_six + num - 1] = 1
train_D = torch.tensor(encoded_data, dtype=torch.float32)
num_classes_first_six = 33
num_classes_last_one = 16
encoded_data = np.zeros((LABEL.shape[0], num_classes_first_six + num_classes_last_one), dtype=int)
for i in range(LABEL.shape[0]):
for j in range(LABEL.shape[1]):
num = int(LABEL[i, j])
if j < 6:
encoded_data[i, num - 1] = 1
else:
encoded_data[i, num_classes_first_six + num - 1] = 1
train_L = torch.tensor(encoded_data, dtype=torch.float32)
test_df = np.array(df.iloc[-300:])
samples = []
label = []
for j in range(len(test_df)):
if j > 28:
feat = test_df[j - 29:j + 1][:, 2:]
samples.append(feat)
label.append(test_df[j - 28:j + 2][-1:, 2:])
DATA = np.array(samples).astype(int)
LABEL = np.array(label).astype(int)
LABEL = np.squeeze(LABEL, axis=(1,))
num_classes_first_six = 33
num_classes_last_one = 16
encoded_data = np.zeros((DATA.shape[0], DATA.shape[1], num_classes_first_six + num_classes_last_one), dtype=int)
for i in range(DATA.shape[0]):
for j in range(DATA.shape[1]):
for k in range(DATA.shape[2]):
num = int(DATA[i, j, k])
if k < 6:
encoded_data[i, j, num - 1] = 1
else:
encoded_data[i, j, num_classes_first_six + num - 1] = 1
test_D = torch.tensor(encoded_data, dtype=torch.float32)
num_classes_first_six = 33
num_classes_last_one = 16
encoded_data = np.zeros((LABEL.shape[0], num_classes_first_six + num_classes_last_one), dtype=int)
for i in range(LABEL.shape[0]):
for j in range(LABEL.shape[1]):
num = int(LABEL[i, j])
if j < 6:
encoded_data[i, num - 1] = 1
else:
encoded_data[i, num_classes_first_six + num - 1] = 1
test_L = torch.tensor(encoded_data, dtype=torch.float32)
batch_size = 100
learning_rate = 0.001
num_epochs = 200
MODEL = 'transformer'
dataset_train = TensorDataset(train_D, train_L)
dataset_val = TensorDataset(test_D, test_L)
# dataset_val = TensorDataset(train_D, train_L)
train_loader = DataLoader(dataset_train, shuffle=True, batch_size=batch_size)
val_loader = DataLoader(dataset_val, shuffle=True, batch_size=batch_size)
class model(nn.Module):
def __init__(self,
fc1_size=400,
fc2_size=200,
fc3_size=100,
fc1_dropout=0.2,
fc2_dropout=0.2,
fc3_dropout=0.2,
num_of_classes=50):
super(model, self).__init__()
self.f_model = nn.Sequential(
nn.Linear(1470, fc1_size), # 887
nn.BatchNorm1d(fc1_size),
nn.ReLU(),
nn.Dropout(fc1_dropout),
nn.Linear(fc1_size, fc2_size),
nn.BatchNorm1d(fc2_size),
nn.ReLU(),
nn.Dropout(fc2_dropout),
nn.Linear(fc2_size, fc3_size),
nn.BatchNorm1d(fc3_size),
nn.ReLU(),
nn.Dropout(fc3_dropout),
nn.Linear(fc3_size, 49),
)
d_model = 49 # 模型的维度
nhead = 7 # 多头注意力的头数
num_encoder_layers = 6 # 编码器层数
num_decoder_layers = 6 # 解码器层数
# 创建Transformer模型
self.transformer = nn.Transformer(d_model=d_model, nhead=nhead,
num_encoder_layers=num_encoder_layers,
num_decoder_layers=num_decoder_layers)
for name, module in self.named_modules():
if isinstance(module, nn.Linear):
nn.init.kaiming_normal_(module.weight, mode='fan_in', nonlinearity='relu')
if isinstance(module, nn.Conv2d):
nn.init.kaiming_normal_(module.weight, mode='fan_in', nonlinearity='relu')
if isinstance(module, nn.Conv1d):
nn.init.kaiming_normal_(module.weight, mode='fan_in', nonlinearity='relu')
def forward(self, x):
input_tensor = x.permute(1, 0, 2) # 转换为(seq_len, batch_size, features)
target_tensor = input_tensor.clone()
output = self.transformer(input_tensor, target_tensor)
output = output.permute(1, 0, 2)
output= torch.reshape(output, (output.shape[0], output.shape[1] * output.shape[2]))
out = self.f_model(output)
return out
model = model()
model.to(device)
criterion = nn.MSELoss()
# optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, betas=(0.9, 0.98), weight_decay=1e-5)
scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max=10)
L_train = []
L_val = []
AUC = []
PRAUC = []
min_validation_loss = 9999
for epoch in range(num_epochs):
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
train_running_loss = 0.0
counter = 0
model.train()
for seq, y in tqdm(train_loader):
counter += 1
output = model(seq.to(device))
loss = criterion(output, y.to(device))
train_running_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step()
TL = train_running_loss / counter
L_train.append(TL)
model.eval()
PREDICT = []
TRUE = []
counter = 0
with torch.no_grad():
current_test_loss = 0.0
for SEQ, Z in tqdm(val_loader):
counter += 1
output = model(SEQ.to(device))
loss = criterion(output, Z.to(device))
current_test_loss += loss.item()
PREDICT.extend(output.cpu().numpy())
TRUE.extend(Z.cpu().numpy())
T_loss = current_test_loss / counter
L_val.append(T_loss)
PP = np.array(PREDICT)
TT = np.array(TRUE)
flattened_array1 = PP.flatten()
flattened_array2 = TT.flatten()
correlation_matrix = np.corrcoef(flattened_array1, flattened_array2)
pr_auc = correlation_matrix[0, 1]
print("Train loss: ", TL, "Val loss: ", T_loss, 'correlation_value', pr_auc)
AUC.append(pr_auc)
if min_validation_loss > T_loss:
min_validation_loss = T_loss
best_epoch = epoch
print('Max pr_auc ' + str(min_validation_loss) + ' in epoch ' + str(best_epoch))
torch.save(model.state_dict(), fr"./model_{MODEL}.pt")
fig1, ax1 = plt.subplots()
ax1.plot(L_train)
ax1.set_xlabel('Epoch')
ax1.set_ylabel('Training Loss')
fig2, ax2 = plt.subplots()
ax2.plot(L_val)
ax2.set_xlabel('Epoch')
ax2.set_ylabel('Validation Loss')
fig3, ax3 = plt.subplots()
ax3.plot(AUC)
ax3.set_xlabel('Epoch')
ax3.set_ylabel('Validation Loss')
fig1.savefig(f"./{MODEL}_1.png")
fig2.savefig(f"./{MODEL}_2.png")
fig3.savefig(f"./{MODEL}_3.png")
应用(爬取最新的30天)
import requests
import csv
import socket
import urllib.request as req
import urllib
from bs4 import BeautifulSoup
import gzip
import ssl
import httplib2
# https://datachart.500.com/ssq/history/history.shtml
# https://datachart.500.com/ssq/history/newinc/history.php?limit=30&sort=0
def get_content(url):
try:
context = ssl._create_unverified_context()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
resp = requests.get(url, headers=headers, timeout=10, verify=False) # verify 参数必传,falst不校验SSL证书
contents = resp.content
if contents:
return contents.decode()
else:
print("can't get data from url:" + url)
except req.HTTPError as e:
print('HTTPError:', e)
except req.URLError as e:
print('URLError:', e)
except socket.timeout as e:
print('socket.timeout:', e)
except BaseException as e:
print('BaseException:', e)
def get_data(html):
if html is None:
return
final = []
bs = BeautifulSoup(html, "html.parser")
print(bs)
datas = bs.find("tbody", {'id': 'tdata'})
trs = datas.find_all('tr')
for tr in trs:
temp = []
tds = tr.find_all('td')
temp.append(tds[0].string)
temp.append(tds[1].string)
temp.append(tds[2].string)
temp.append(tds[3].string)
temp.append(tds[4].string)
temp.append(tds[5].string)
temp.append(tds[6].string)
temp.append(tds[7].string)
final.append(temp)
print(final)
return final
def write_data(data, name):
with open(name, 'w', errors='ignore', newline='') as f:
csvFile = csv.writer(f)
csvFile.writerows(data)
if __name__ == '__main__':
url = 'https://datachart.500.com/ssq/history/newinc/history.php?limit=30&sort=0'
html = get_content(url)
data = get_data(html)
write_data(data, 'TwoColorBallData30.csv')应用(预测下一期)
# from transformers import EsmModel, EsmTokenizer, EsmConfig
# from sklearn.model_selection import train_test_split
# from sklearn import metrics
# from sklearn.metrics import mean_squared_error, r2_score
# import seaborn as sns
# from sklearn.metrics import accuracy_score
# from sklearn.preprocessing import OneHotEncoder
import sys
import akshare as ak
from sklearn.metrics import average_precision_score, accuracy_score, f1_score
import numpy as np
import pandas as pd
import torch
from sklearn import metrics
import matplotlib.pyplot as plt
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Dataset
from torchvision.transforms import Normalize
from sklearn.model_selection import KFold
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset, Dataset
from torch.optim import lr_scheduler
from tqdm import tqdm
from sklearn.metrics import precision_recall_curve, auc
import os
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
DATA = pd.read_csv(r'./TwoColorBallData30_1.csv',header=None)
DATA.columns = ['0', '1', '2', '3', '4', '5', '6', '7']
DATA = DATA.sort_values(by='0', ascending=True)
DATA = np.array(DATA.drop(columns=['0'])).reshape(1, 30, 7)
num_classes_first_six = 33
num_classes_last_one = 16
encoded_data = np.zeros((DATA.shape[0], DATA.shape[1], num_classes_first_six + num_classes_last_one), dtype=int)
for i in range(DATA.shape[0]):
for j in range(DATA.shape[1]):
for k in range(DATA.shape[2]):
num = int(DATA[i, j, k])
if k < 6:
encoded_data[i, j, num - 1] = 1
else:
encoded_data[i, j, num_classes_first_six + num - 1] = 1
train_D = torch.tensor(encoded_data, dtype=torch.float32)
batch_size = 100
MODEL = 'transformer'
dataset_train = TensorDataset(train_D)
train_loader = DataLoader(dataset_train, shuffle=False, batch_size=batch_size)
class model(nn.Module):
def __init__(self,
fc1_size=400,
fc2_size=200,
fc3_size=100,
fc1_dropout=0.2,
fc2_dropout=0.2,
fc3_dropout=0.2,
num_of_classes=50):
super(model, self).__init__()
self.f_model = nn.Sequential(
nn.Linear(1470, fc1_size), # 887
nn.BatchNorm1d(fc1_size),
nn.ReLU(),
nn.Dropout(fc1_dropout),
nn.Linear(fc1_size, fc2_size),
nn.BatchNorm1d(fc2_size),
nn.ReLU(),
nn.Dropout(fc2_dropout),
nn.Linear(fc2_size, fc3_size),
nn.BatchNorm1d(fc3_size),
nn.ReLU(),
nn.Dropout(fc3_dropout),
nn.Linear(fc3_size, 49),
)
d_model = 49 # 模型的维度
nhead = 7 # 多头注意力的头数
num_encoder_layers = 6 # 编码器层数
num_decoder_layers = 6 # 解码器层数
# 创建Transformer模型
self.transformer = nn.Transformer(d_model=d_model, nhead=nhead,
num_encoder_layers=num_encoder_layers,
num_decoder_layers=num_decoder_layers)
for name, module in self.named_modules():
if isinstance(module, nn.Linear):
nn.init.kaiming_normal_(module.weight, mode='fan_in', nonlinearity='relu')
if isinstance(module, nn.Conv2d):
nn.init.kaiming_normal_(module.weight, mode='fan_in', nonlinearity='relu')
if isinstance(module, nn.Conv1d):
nn.init.kaiming_normal_(module.weight, mode='fan_in', nonlinearity='relu')
def forward(self, x):
input_tensor = x.permute(1, 0, 2) # 转换为(seq_len, batch_size, features)
target_tensor = input_tensor.clone()
output = self.transformer(input_tensor, target_tensor)
output = output.permute(1, 0, 2)
output= torch.reshape(output, (output.shape[0], output.shape[1] * output.shape[2]))
out = self.f_model(output)
return out
model_path = fr'./model_{MODEL}.pt'
model = model()
model.load_state_dict(torch.load(model_path, map_location=device))
model.to(device)
model.eval() # 0.54
with torch.no_grad():
test_order = tqdm(train_loader)
for SEQ in test_order:
SEQ = SEQ[0]
output = model(SEQ.to(device))
data = np.array(output.cpu())
num_classes_first_six = 33
top_k_first_six = 7
# 找到前33个数字中最大的7个的索引
top_indices_first_six = np.argsort(-data[0, :num_classes_first_six])[:top_k_first_six]
# 创建一个用于存储结果的数组
encoded_data_first_six = np.zeros((1, num_classes_first_six), dtype=int)
# 设置最大的7个为1,其他为0
encoded_data_first_six[0, top_indices_first_six] = 1
# 将剩下的16个数字中最大的一个设置为1,其他为0
num_classes_last_one = 16
# 找到剩下的16个数字中最大的一个的索引
max_index_last_one = np.argmax(data[0, num_classes_first_six:])
# 创建一个用于存储结果的数组
encoded_data_last_one = np.zeros((1, num_classes_last_one), dtype=int)
# 设置最大的一个为1,其他为0
encoded_data_last_one[0, max_index_last_one] = 1
# 将两部分结果合并
encoded_data = np.concatenate((encoded_data_first_six, encoded_data_last_one), axis=1)
# 将结果重新调整为(1,49)
encoded_data = np.concatenate((encoded_data, np.zeros((1, 49 - encoded_data.shape[1]), dtype=int)), axis=1)
num_classes_first_six = 33
num_classes_last_one = 16
onehot_length_first_six = 6
onehot_length_last_one = 16
# 找到前6个数字中最大的7个的索引
top_indices_first_six = np.argsort(-encoded_data[0, :num_classes_first_six])[:onehot_length_first_six]
# 找到最后一个数字中最大的一个的索引
max_index_last_one = num_classes_first_six + np.argmax(encoded_data[0, num_classes_first_six:])
# 将索引还原为数字
restored_data_first_six = top_indices_first_six + 1
restored_data_last_one = max_index_last_one - num_classes_first_six + 1
# 将结果合并为7个数字
restored_data = np.concatenate((restored_data_first_six, np.array([restored_data_last_one])))
# 打印还原后的数字
print(restored_data)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











