







之前博文中有提到,KnowFlow(基于 RAGFlow 二次开发的商业化产品) 计划要开发以下三个核心功能:
-
重构 RAGFlow 前端页面以及交互
-
进一步增强 RAGFlow 文档解析能力
-
完善 RAGFlow 结构化输出能力,支持图片、表格、图标等输出形式
今天我们带来的是上述 RAGFlow 支持图片回答,我们先来看下效果图:
原理分析
我们回到解决问题的原点来看,当 RAG 系统生成回答时,如果回答文本中包含指向静态目录的图片 Markdown 链接(比如 ),此时通过脚本自动渲染为 HTML 图片元素,当浏览器通过 Http 请求获取时将会显示图片。
总结几个关键点:
-
获取文档中的图片:从文件中通过 OCR 获取到图片并追加到文件内容
-
本地文件系统到 HTTP 的转化:将回答内容中的本地文件路径转化为 HTTP URL
-
Markdown 渲染:前端组件能够解析和渲染 Markdown 图片引用
-
浏览器请求机制:浏览器通过 HTTP URL 请求获取到图片
RAGFlow 现状分析以及解决方案
如何提取图片:同时如何获取一个文件内的所有图片,RAGFlow 的 DeepDoc 模块虽然已经具备了布局分析、图片提取的能力,如果直接在源码内修改,会直接导致后续维护成本巨大。KnowFlow 产品设计初衷是能够持续兼容 RAGFlow 版本更新。
我们最终选择通过专业的 OCR 引擎来解决问题,我们在 KnowFlow 内置了 MinerU 和 PyMuPDF 两种引擎。其中 MinerU 实测效果更好,当然也更加消耗资源,如果有 GPU 硬件配置,速度可以明显提升;PyMuPDF 是轻量级选择,实测简单文本可以正常识别出图片,复杂的识别不出来。当然在架构设计层面,我们后续可扩展其他优秀的 OCR 引擎。
如何访问图片:RAGFlow 包括 Dify 这样的框架设计在容器化 Docker 环境运行,出于安全考虑限制了对宿主主机文件系统直接访问。容器与主机文件系统是隔离的,这个特性导致如何访问这些静态图片成为一个需要考虑的问题。
-
阿里云 OSS 存储:我们考虑了阿里云 OSS 存储方案,但由于将图片暴露到公网,对于 KnowFlow 来说这是不可接受的,数据隐私是第一要考虑的。
-
Base64 嵌入:Base64 会带来明显的性能问题,不仅会增加数据体积,还会导致 tokens 急剧上升。
-
开发插件和工作流:RAGFlow Agent 不支持自定义 Python 组件,Dify 支持。但为了支持该功能,接入 Dify 框架太重了,同时考虑到 Dify 商用的限制,该方案不可行。
-
图片服务器容器化:这也是目前采用的方案。创建独立的 Http 服务器,用于提供图片,同时容器化,保持和 RAGFlow 在同一网络运行。该方案可扩展,不需要改 RAGFlow 本身。
实施步骤
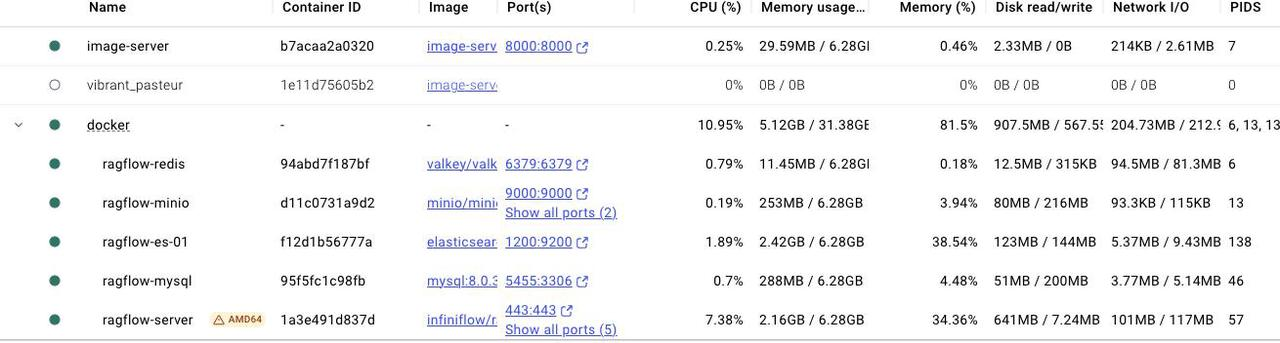
一:新建 image-server 容器
系统层面新增图片服务器容器,部署在 Docker 内,提供图片资源的 Http 访问。并通过自定义网络,使得 RAGFlow 可以通过容器名直接访问 image-server 容器内的图片。
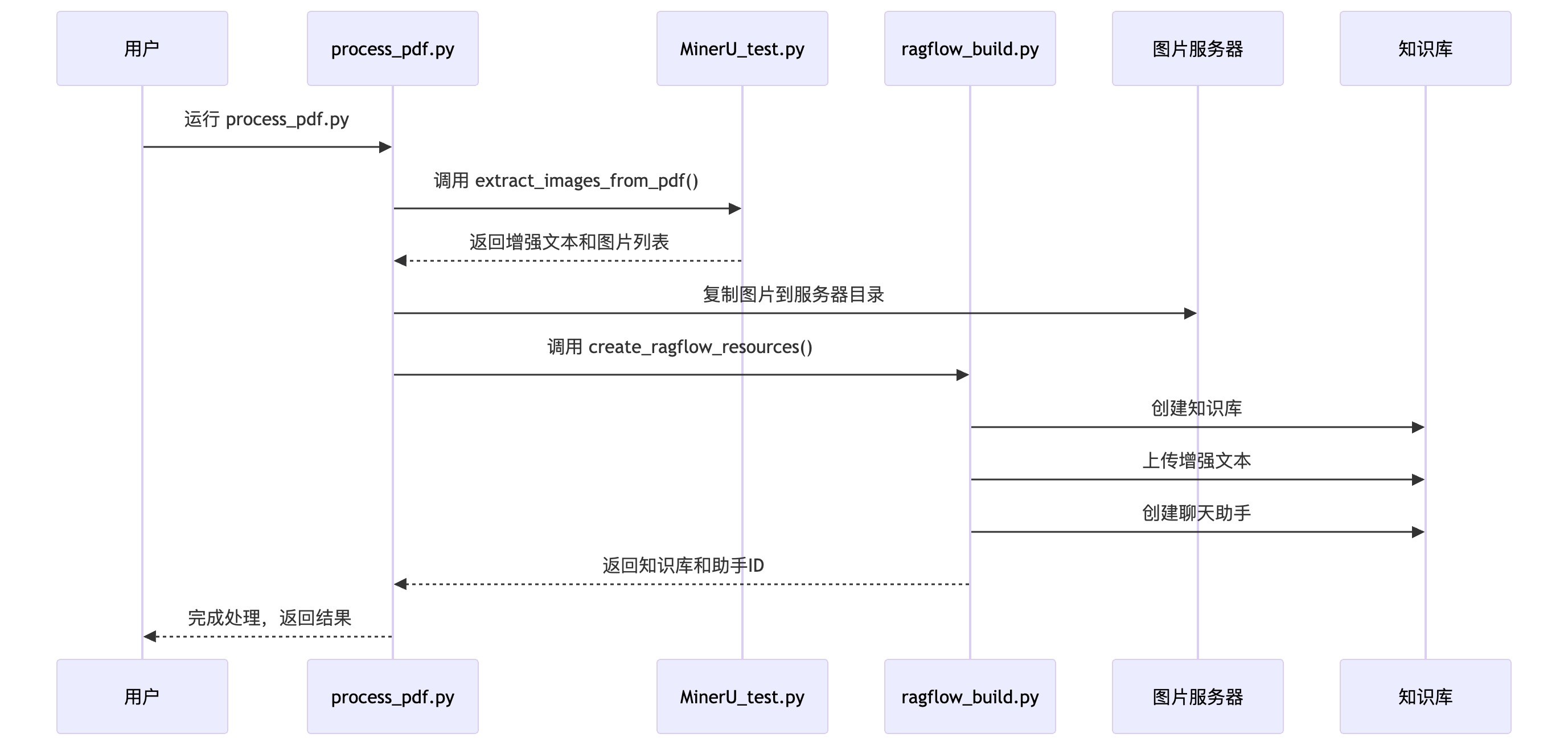
二:从文档中提取图片
集成 MinerU ,通过 MinerU 提供的的 API 能力获取文档内所有静态图片,并将抓取到的本地图片发送到 image-server 容器,同时将 Markdown 本地图片转成 Http Url 链接。
提取图片
三:创建 RAGFlow 知识库,上传文档并创建会话
通过 RAGFlow 提供的 Python API 能力,自动化创建知识库、上传文档、创建助手。
未来展望
现阶段仅仅是解决了图片展示的问题,但仍然存在很多问题,比如问题块附近有多个图片,LLM 怎么判断选择哪一张图片?后续的开发方向有:
-
可视化界面:可以在前端选择文件以及OCR 模型,实现一键部署。将抓取上报图片、Url Http 化、自动化创建 RAGFlow 知识库等细节隐藏在后台服务,技术上实现前后端分离。
-
图片调优:让大模型更加清楚知道应该选择哪一张图片
-
UI 样式优化:图片和文本混排优化
源码
本项目已经开源,未来将会持续开源,赋能给更多的开发者。
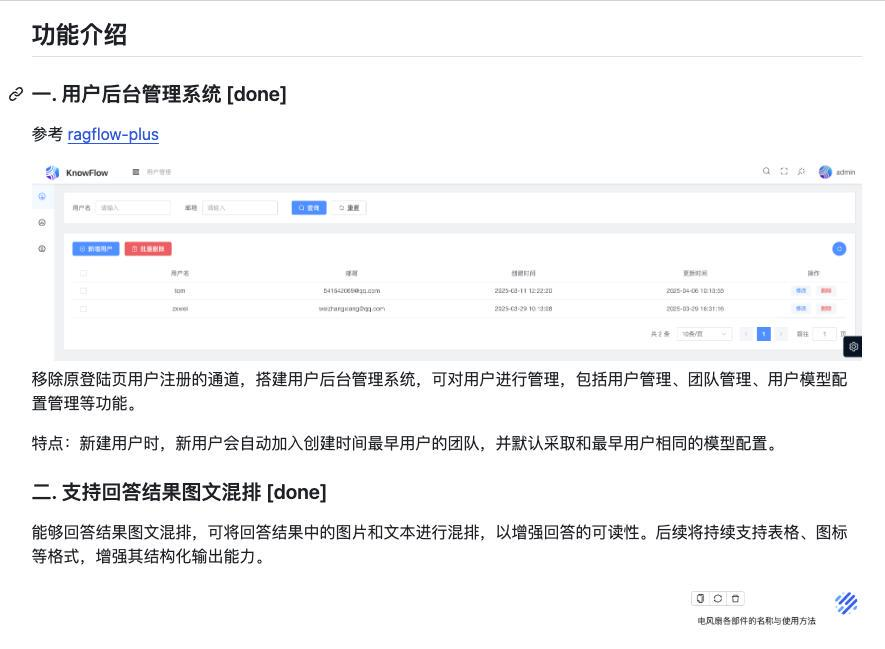
KnowFlow 是基于 RAGFlow 二次开发的产品,专注于私有化部署和可信回答。已支持用户后台管理以及图片回答,后续将会围绕以下几个功能点进行优化:
-
文档预处理:虽然 DeepDoc 很出色,但经过实践经验,文档经过预处理之后,对识别准确率有很大提升,我们将会持续支持文档预处理能力。
-
RAGFlow UI 重构:重构 RAGFlow UI,提供更友好的交互体验。
期望与各位同学更加深入的交流,如有源码需求,可以关注「KnowFlow 企业知识库」公众号,回复「源码」,便可以获取开源项目地址。

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









