





 本文详述了PSMNet论文,一种基于深度学习的双目立体匹配方法。PSMNet利用空间金字塔池化模块和3D卷积,增强全局上下文信息,解决了不适定区域的匹配问题。在KITTI数据集上,PSMNet展现出优秀性能。
本文详述了PSMNet论文,一种基于深度学习的双目立体匹配方法。PSMNet利用空间金字塔池化模块和3D卷积,增强全局上下文信息,解决了不适定区域的匹配问题。在KITTI数据集上,PSMNet展现出优秀性能。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
本文整理了[CVPR2018] PSMNet论文的主要内容,仅作为学习记录。
翻译部分参考:论文阅读笔记《Pyramid Stereo Matching Network》
一、研究背景
基于卷积神经网络在立体匹配算法方面的可行性,之前的架构主要依赖于基于补丁的暹罗网络(Siamese Network,是一种特殊类型的神经网络,是最简单、最常用的one-shot学习算法之一,包含两个或多个相同的子网络,能够从较少的数据中学习输入之间的相似性),缺乏利用上下文信息在不适定区域寻找对应关系的方法。由此,本文提出了PSMNet(金字塔立体匹配网络),主要由两部分构成:金字塔池化模块和3D卷积模块。其中金字塔池化模块主要结合不同尺度不同位置的信息构建匹配代价卷(cost volume),3D卷积使用堆叠的沙漏模型与中间监督相结合去调整匹配代价卷。该方法截至目前在KITTI2012上排名75位,在KITTI2015上排名132位。
二、论文精读
1. 介绍
从立体图像中估计深度信息在车辆自动驾驶、物体三维重建、物体检测识别等方面的应用至关重要。立体匹配的过程就是从校正好的两幅左右图像之中,通过搜索最优匹配点来得到较为准确的视差图的过程。典型的立体匹配方法主要包含4个步骤:匹配代价计算、匹配代价聚合、视差计算、视差优化。神经网络的作用便是学习如何匹配准确的对应点的过程。MC-CNN作为神经网络在立体匹配方面应用的开山之作,将对应的视差估计问题转换为相似度函数计算,与传统方法相比在速度和准确度方面都取得了重要突破,但它依旧很难在不适定区域(例如遮挡区域,重复纹理区域,弱纹理区域和反光表面等)找到精确的匹配点。
在此之前,也有一些学者针对该问题对基于CNN的立体匹配算法进行改进:Displets方法利用车辆的3D模型信息去解决匹配中有歧义的点;ResMatchNet学习去计算视差图的反射置信度来改善不适定区域的性能表现;GC-Net采用编码器-解码器体系结构来合并多尺度特征,以实现成本体积正则化。
在本文研究中,我们提出了一种新的金字塔立体匹配网络(PSMNet)来利用立体匹配中的全局上下文信息。空间金字塔池化(SPP)和空洞卷积用于扩大感受野。通过这种方式,PSMNet将像素级特征扩展到具有不同尺度感受野的区域级特征,由此得到的全局和局部特征信息被用来形成可靠的视差估计的匹配代价卷。此外,我们设计了一个堆叠沙漏3D-CNN结合中间监督,以调整匹配代价,类似于传统方法中的匹配代价聚合。3D-CNN以自上而下/自下而上的方式重复处理匹配代价,以进一步提高对全局上下文信息的利用率。
2. 相关工作
当前的一些研究聚焦于如何利用CNN准确的计算匹配代价和如何利用半全局匹配(SGM)去优化视差图。本文整理了前人在匹配代价计算、视差后处理和端到端的神经网络预测视差图等方面的研究,并结合语义分割领域的研究思想(结合环境上下文信息对物体分类的影响),针对编码器解码器结构和空间金字塔池化这两种利用环境信息的方法,本文采用多尺度环境信息聚合,通过一个金字塔立体匹配网络完成深度估算。
3. 金字塔立体匹配网络
本文提出的网络包含一个空间金字塔池化模块(spp)用于聚合环境信息和一个编码解码模块用于匹配代价聚合。
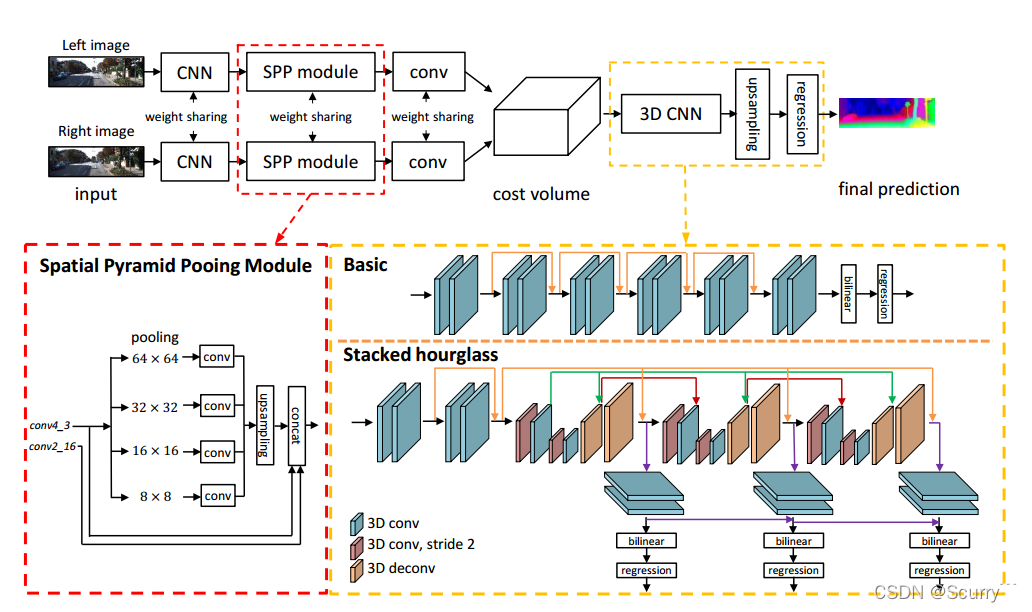
图1 PSMNet的网络结构;包括两个共享权重的通道,其中CNN用于特征图计算,SPP模块用于连接获取来自不同大小子区域的特征,以及卷积层用于特征融合。然后利用左右图像生成的4D匹配代价(高、宽、视差、特征大小),将其送入3DCNN中用于代价聚合和视差回归。
3.1 网络结构
参数详情如表所示:
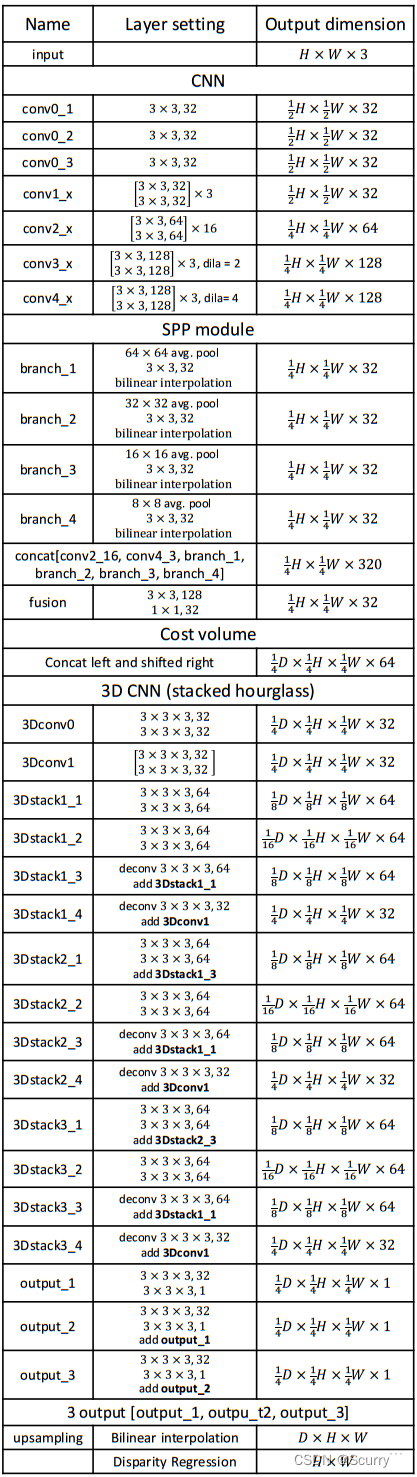
与其他研究中第一个卷积层应用大卷积核(7×7)相比,三个小卷积(3×3)被级联以构建具有相同感受野的更深的网络。conv1x、conv2x、conv3x和conv4x是学习一元特征提取的基本残差块。对于conv3x和conv4x,采用空洞卷积来进一步扩大感受野。输出特征图大小为输入图像大小的四分之一,如表1所示。我们将左右特征映射连接到一个匹配代价中,并送入一个三维CNN进行代价聚合。最后,应用回归方法计算输出视差图。
3.2 空间金字塔池化模块
仅从像素强度(灰度值或RGB值)来说很难确定上下文关系。本文通过SPP模块将多层环境信息聚合(例如汽车和轮胎、车窗之间的关系)。在PSPNet中,SPP模块使用自适应平均池化把特征压缩到四个尺度上,并紧跟一个1*1的卷积层来减少特征维度,之后低维度的特征图通过双线性插值的方法进行上采样以恢复到原始图片的尺寸。在本文中,我们为SPP设计了4个固定大小的平均池化块:64×64、32×32、16×16和8×8,并且包含1×1的卷积和上采样,与PSPNet中的操作相同。我们进行了广泛的实验来显示不同的特征图在不同层次上的影响。
3.3 匹配代价卷
参考MC-CNN和GC-Net中的方法没有采用距离度量,而是将左右特征图连接起来,以学习使用深度网络计算匹配代价。在GC-Net的基础上,我们采用SPP特征,通过在不同视差级别上将左侧特征图与其对应的右侧特征图连接起来,形成匹配代价卷。
3.4 3D CNN
SPP模块通过结合不同尺寸的特征来进行立体匹配。为了沿着视差维度和空间维度聚合特征信息,我们提出了两种用于匹配代价聚合的三维CNN结构:基本结构和堆叠沙漏结构。在基本的体系结构中,如图1所示,网络只是简单地使用残差块来构建的。基本架构包含12个3×3×3的卷积层。然后,我们通过双线性插值将匹配代价上采样到H×W×D的大小。最后,我们应用回归计算大小为H×W的视差图。
为了了解更多的上下文信息,我们使用堆叠沙漏(编码器-解码器)架构结合中间监督进行重复的由精到粗再由粗到精的处理,如图1所示。堆叠的沙漏架构有三个主要的沙漏网络,每个网络都生成一个视差图。也就是说,堆叠的沙漏体系结构有三个输出和损失(损失1、损失2和损失3)。训练过程中,总的损失是由三个损失值的加权求和得到的。在测试过程中,最终的视差图是由三个输出中的最后一个得到的。在我们的简化模型研究中,我们使用了基本结构来评估SPP模块的性能,因为基本结构不会通过编码/解码过程学习额外的上下文信息。
3.5 视差回归
我们使用视差回归来估计连续的视差图。每个视差d的概率是通过softmax操作从预测的代价cd中计算出来的。
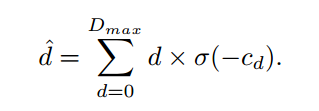
视差回归比基于分类的立体匹配方法更具有鲁棒性。
3.6 损失函数
因为采用视差回归,我们采用平滑的L1损失函数来训练所提出的PSMNet。与L2损失函数相比,平滑的L1损失由于其鲁棒性和对异常值的敏感性低,被广泛用于目标检测的边界盒回归。PSMNet的损失函数定义为
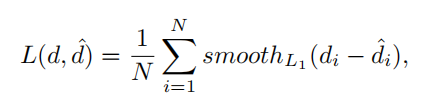
式中
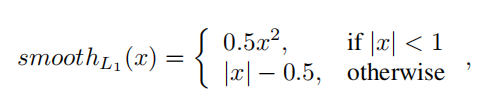
其中,N是标记的像素的数量,d是真实视差值,d’是预测的视差值。
4. 实验
我们在三个立体匹配数据集上评估了我们的方法:SceneFlow、KITTI2012和KITTI2015。我们还使用KITTI2015对我们的架构设置进行了消融研究,以评估空洞卷积、不同尺度的金字塔池和堆叠沙漏3DCNN对性能的影响。
所提出的PSMNet的完整架构如表1所示,包括卷积核的数量。批处理归一化和ReLU的使用与ResNet中的相同,只是PSMNet在求和后不应用ReLU。
PSMNet架构是使用PyTorch实现的。所有模型均采用Adam(β1=0.9,β2=0.999)进行端到端训练。我们对整个数据集进行了颜色归一化,以进行数据预处理。在训练过程中,图像被随机裁剪到H=256和W=512的大小。最大视差(D)被设置为192。我们使用SceneFlow数据集从零开始训练我们的模型,以恒定学习率0.001训练了10个epoch。对于SceneFlow来说,训练后的模型直接用于测试。对于KITTI,我们在对KITTI训练集进行了300个epoch的微调后,使用了SceneFlow数据预训练的模型。这种微调的学习率在前200个epoch为0.001,在剩下的100个epoch为0.0001。对于对4个nNvidiaTitan-Xpgpu(每个3个)的训练,batchsize设置为12。SceneFlow数据集的训练过程约为13小时,KITTI数据集的训练过程约为5小时。此外,我们将训练过程延长到1000个epoch,以获得最终模型和KITTI提交的测试结果。
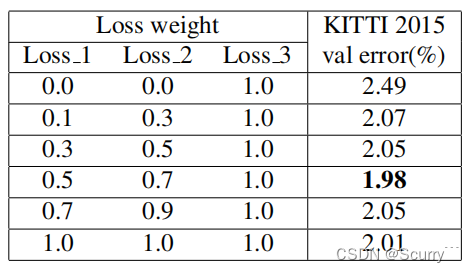
结果显示,损失1的权重设置为0.5,损失2的权重设置为0.7,损失3的权重设置为1.0,性能最好,在KITTI2015验证集上的错误率为1.98%。
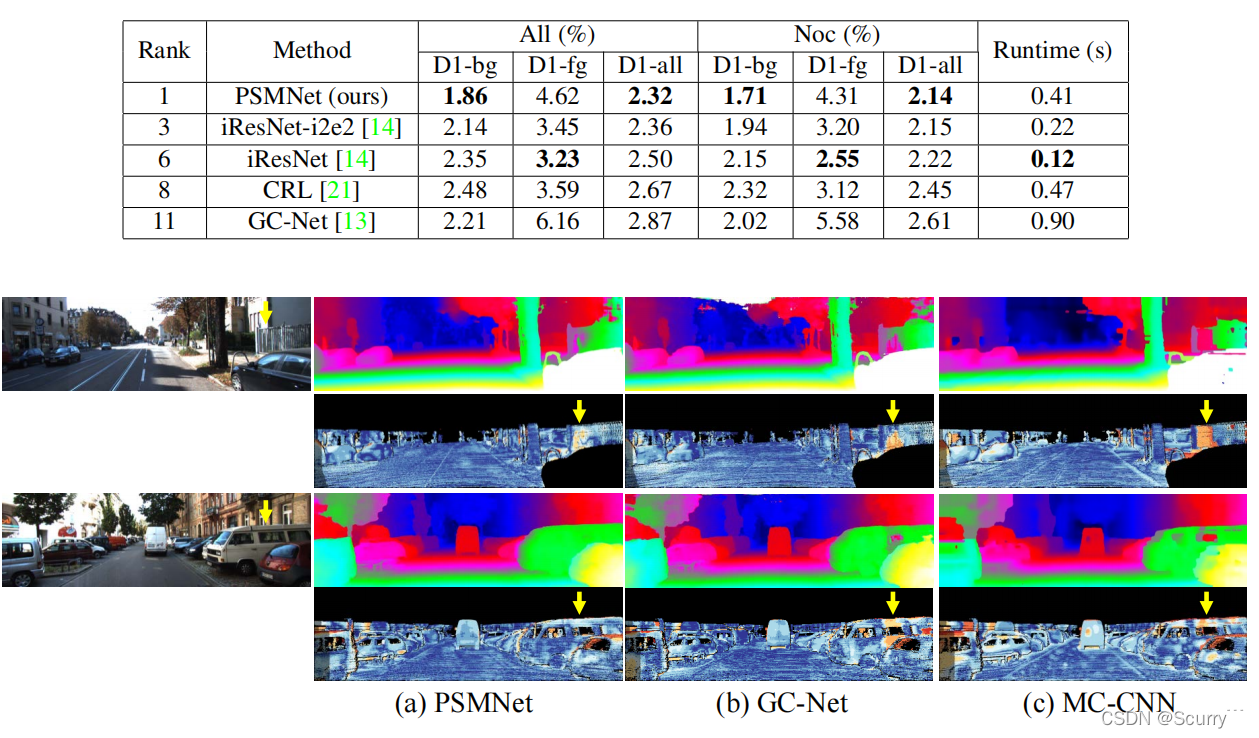
最后对比了其他算法在kitti2012和kitti2015上的效果。如图所示为KITTI2015测试图像的视差估计结果。左侧面板显示了立体图像对的左侧输入图像。
总结
本文主要提出了一个端到端的学习框架来进行立体匹配,不用任何的后处理过程,结合金字塔池化模块将全局环境信息整合到图像特征中,使用堆叠沙漏3D CNN来加强对全局信息的利用程度,并在KITTI数据集上取得了良好的精确度。

















 394
394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









