






神经影像学中的可重复性危机导致对标准化数据处理工作流的需求不断增加。在ENIGMA联盟内,我们开发了HALFpipe(功能性磁共振成像流程的统一分析),这是一个开源的、容器化的、用户友好的工具,通过统一应用预处理、质量评估、单主体特征提取和组水平统计,促进任务态和静息态fMRI数据的可重复分析。它使用fMRIPrep提供最先进的预处理,而无需输入数据采用脑影像数据结构(BIDS)格式。HALFpipe扩展了fMRIPrep的功能,增加了额外的预处理步骤,包括空间平滑、总体均值标度化、时间滤波和混淆回归。HALFpipe生成一个交互式质量评估(QA)网页,用于评估关键预处理输出和原始数据的总体质量。HALFpipe在个体水平上具有众多后处理功能,包括计算任务相关激活、基于种子点的连接、网络模板(或双重)回归、基于图谱的功能连接矩阵、局部一致性(ReHo)和低频振幅分数(fALFF),支持在一次运行中评估组合数量的特征或预处理设置。最后,可以为组水平的混合效应回归分析定义灵活的因子模型,包括多重比较校正。在此,我们介绍了HALFpipe开发的理论框架,并概述了该流程的主要功能。HALFpipe为科学界提供了一个重要进展,以解决神经影像学中的可重复性危机,提供了一个涵盖fMRI数据预处理、后处理和QA的工作流程,同时扩展了产生可重复结果的数据分析核心原则。说明和代码可在https://github.com/HALFpipe/HALFpipe 找到。本文发表在Human Brain Mapping杂志。
1 引言
神经影像学特别是功能性磁共振成像(fMRI)的应用,已经在人类行为、认知过程和情绪相关的大脑功能知识方面产生了爆炸性增长。这类研究受到计算密集型软件的快速发展推动,这些软件用于执行fMRI数据的复杂算法处理和统计建模。为满足各种分析功能而设计的软件工具的激增,产生了大量执行任何特定类型处理的选项。由于fMRI信号间接捕获感兴趣的神经过程,需要对fMRI数据进行一系列计算操作(称为分析流程)才能得到可解释的结果。在实践中,每个步骤都是灵活的,且受研究人员多个选择的影响,这称为分析灵活性(Poldrack等,2017)。分析流程中的步骤可以重新排序、使用不同参数运行,或在某些情况下完全省略。可以理解,用户期望执行相同功能的不同工具在给定输入数据时产生(接近)相同的结果。然而,工具的多样性产生了意想不到的后果:即使使用相同的数据作为起点,旨在回答相同研究问题的研究也会产生不一致的结果(Botvinik-Nezer等,2020)。因此,分析灵活性与分析步骤的数量以及运行每个分析步骤的可能参数相结合,导致了大量方法学变体和同等数量的可能结果。这种情况部分导致了现在普遍认为的可重复性危机,这种危机正困扰着神经影像学领域(Gorgolewski等,2016; Poldrack等,2017)。
改善可重复性的一个解决方案是通过将选择限制在基于经验得出的最佳实践的默认参数来约束参数空间(Grüning等,2018)。例如,已建立的流程如fMRIPrep(Esteban等,2019)和C-PAC(Craddock等,2013)已经自动化了许多这些选择。另一种方法是在相同输入数据上使用相同或不同的流程分别运行多个分析,但每个分析使用不同的参数选择,然后比较结果。这第二种方法称为多重分析(Steegen, Tuerlinckx, Gelman和Vanpaemel,2016),其优点是可以比较多个分析的结果,并在发表的报告中呈现替代方案以提高透明度。然而,多重分析的缺点是最终可能无法确定最优甚至正确的解决方案,因为非模拟fMRI数据中的真实效应通常是未知的。
可重复性危机导致对标准化工作流程的需求增加,以进行fMRI分析的预处理和后处理阶段。最近引入并广泛采用的fMRI数据预处理标准化流程为研究界提供了急需的高质量工具,提高了可重复性(Thompson等,2020)。数据分析和可重复结果的四个基本要素是:(a)数据和元数据的可用性,(b)代码使用和透明度,(c)软件可安装性,和(d)运行时环境的重建。相对于其他处理流程,fMRIPrep(Esteban等,2019)因其采用最佳实践、开源可用、良好的用户体验和透明度的玻璃盒原则而日益流行(Poldrack, Gorgolewski和Varoquaux,2019)。然而,fMRIPrep仅限于fMRI数据分析的最小预处理步骤,而进一步预处理(如数据清理)和后续后处理分析步骤(如特征提取、模型指定)的参数选择变异性可能会损害可重复性。
ENIGMA(通过元分析增强神经影像遗传学)联盟通过汇集结构和扩散成像(最近还包括脑电图和脑磁图)的观察性研究数据,并通过开发标准化流程、数据协调方法和质量控制协议来解决可重复性危机(Thompson等,2020)。这些工作流程成功分析了来自大量小型和中型队列的结构和扩散MRI数据,积累了足够的统计效能,在广泛的神经精神疾病方面产生了可靠的结果(如Hoogman等,2020; Schmaal等,2020; van den Heuvel等,2020)。然而,直到现在ENIGMA联盟还缺乏可靠进行全联盟范围fMRI数据分析的能力。最近,ENIGMA任务态(Veer, Waller, Lett, Erk和Walter,2019)和静息态fMRI(Adhikari等,2019)工作组推动了将ENIGMA框架扩展到功能领域的倡议。
为支持ENIGMA内的这些倡议,我们开发了一个标准化工作流程,该流程涵盖了从原始数据到组水平统计的任务态和静息态fMRI分析的基本要素,以fMRIPrep开发者的进展和贡献为基础,并将其功能扩展到预处理步骤之外,包括额外的预处理、后处理和交互式质量评估工具。这些扩展功能包括:自动可靠地将fMRI数据转换为BIDS格式、空间平滑、时间滤波、扩展的混淆回归、计算任务相关激活和静息态特征提取,包括基于种子点的功能连接、网络模板(双重)回归、基于图谱的功能连接矩阵、局部一质性(ReHo)分析和低频振幅分数(fALFF)。虽然这些后处理功能在其他软件包中都有提供,一些流程也整合了其中的部分功能,但HALFpipe将所有这些来自开源神经影像包的后处理工具与fMRIPrep执行的预处理步骤结合在一起(见表1)。此外,尽管HALFpipe为每个处理步骤提供了推荐设置(见表3),但它允许用户运行这些处理设置的任意组合数量,从而为进行多重分析提供了精简的基础设施。与其他处理流程类似,HALFpipe以容器化镜像形式提供,从而对计算环境提供完全控制。在本文中,我们详细描述了HALFpipe。首先,我们解释软件架构和实现,然后介绍运行软件的程序,最后讨论该流程的潜在应用。
表1. 与其他神经影像流程的比较
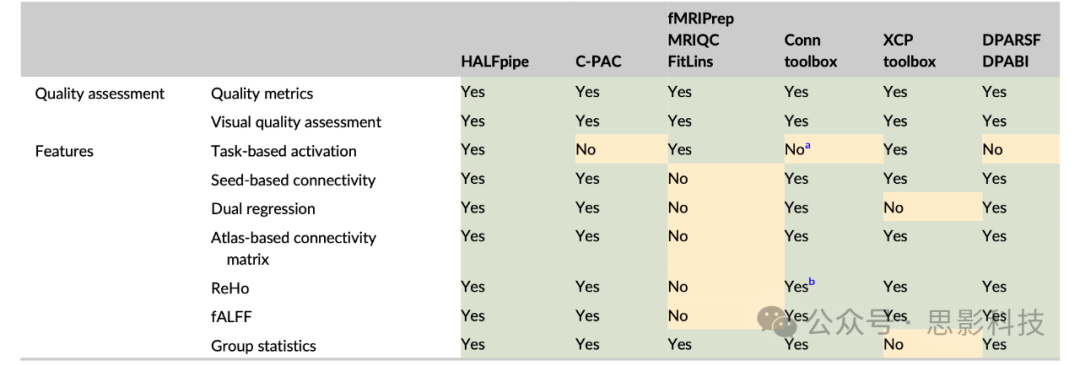
注意:HALFpipe支持许多在其他流程中也可用的不同功能,如用于连接组分析的可配置流程C-PAC(Craddock等,2013)、Conn工具箱(Whitfield-Gabrieli和Nieto-Castanon 2012)、可扩展连接流程XCP(Ciric等2018)和脑影像数据处理分析工具箱DPABI(Yan等2016)。fMRIPrep(Esteban, Markiewicz等2019)结合磁共振成像质量控制工具(MRIQC)(Esteban等,2017)和FitLins(Markiewicz等2016)允许用户在Nipype生态系统内完全构建分析流程(Esteban, Ciric等2020)。
a 支持基于任务的连接性分析。 b 以LCOR(局部相关)方式实现。
2 方法
HALFpipe软件是容器化的,类似于fMRIPrep或C-PAC。这意味着它与运行所需的所有其他软件打包在一起,如fMRIPrep(Esteban, Markiewicz等,2019)、MRIQC(Esteban等,2017)、FSL(Jenkinson, Beckmann, Behrens, Woolrich和Smith,2012)、ANTs(Avants等,2011)、FreeSurfer(Fischl和Dale,2000)和AFNI(Cox,1996; Cox和Hyde,1997)。因此,某一版本HALFpipe的所有用户将使用这些工具的相同版本,因为它们与容器一起打包。这样,HALFpipe软件的容器化有助于在不同研究人员和计算环境之间实现可重复性。
我们以Singularity容器和Docker容器的形式提供HALFpipe应用程序。在下载容器化HALFpipe应用程序之前,必须先安装Singularity或Docker(均为免费提供)。Docker和Singularity都执行所谓的操作系统级虚拟化,但比虚拟机更高效且资源需求更少。在Linux或macOS操作系统上运行Docker容器通常需要管理员权限。Singularity通常在Linux操作系统上运行,无需管理员权限即可使用。Docker可以在Windows操作系统上运行,但可能出现文件系统兼容性问题。
我们的HALFpipe开发团队采用了其他软件工程最佳实践,这促进了更快的开发,并减少了代码错误。这些已应用于研究领域的行业最佳实践(Das,2018)包括:编写易于阅读的代码(尽管通常更难编写)、将复杂系统分解为几个更简单的子系统、在实施前致力于周到的代码设计,以及通过单元测试进行持续集成(Beck,2000)。
2.1 生态系统
HALFpipe已作为开源项目开发,并接受提供新功能、增强功能或提高效率的贡献。所有更改都使用Git版本控制系统进行跟踪,这是开源社区的事实标准。此外,在纳入源代码树之前,更改将被审查,然后进行自动测试,包括单元测试以及对OpenNeuro数据集ds000108(Wager, Davidson, Hughes, Lindquist和Ochsner,2008)的一个受试者进行完整分析。通过这种方式,意外的副作用和错误将在给用户造成问题之前被发现和纠正。
HALFpipe的发布使用语义版本控制,并针对Python兼容性进行了调整(Coghlan和Stufft,2013)。这意味着将有添加新功能的功能版本和进行小调整以解决特定问题或错误的补丁版本。开发团队非常注意将fMRIPrep等依赖项的新补丁版本定期纳入HALFpipe,以便向用户提供错误修复。
HALFpipe目前依赖于fMRIPrep的长期支持版本20.2.x。对于包含新功能的未来版本,开发人员将批准对ENIGMA联盟项目有利的可能升级。我们还可能考虑基于这些考虑在未来版本中替换用于特定处理步骤的工具或升级标准脑模板,这将在每个版本的更改日志中说明。
2.2 数据库
要自动构建神经影像数据处理工作流程,程序需要能够完成诸如"检索受试者x的结构图像"之类的查询。许多程序使用数据库系统实现此类查询。这些查询还需要灵活地与神经影像和处理流程的逻辑接口,这在缺失扫描的情况下是相关的。
在缺失扫描的情况下,HALFpipe始终尝试基于可用数据执行最佳可能的处理流程。例如,在特定数据集中,可能在每次功能扫描之前常规获取场图。如果其中一个场图缺失,HALFpipe会灵活地分配另一个场图,例如属于前一个功能扫描的场图。但是,HALFpipe不会使用来自另一个扫描会话的场图,因为场不均匀性可能已经改变。最后,如果缺少场图,HALFpipe不会失败,而是简单地省略该受试者的失真校正步骤。其他例子包括HALFpipe匹配结构和功能图像的能力,以及将任务事件与功能扫描匹配的能力。这种策略贯穿于处理工作流程的构建过程。
2.3 元数据
处理神经影像数据需要访问相关元数据,如时间分辨率、空间分辨率等。某些元数据元素(如回波时间TE)的表示方式因扫描仪制造商和DICOM转换软件而异。HALFpipe使用以下三种方法协调了读取各种类型数据的方法。
首先,元数据可以存储为BIDS格式。这意味着每个图像文件都有一个JavaScript对象表示法(JSON)文件相伴,其中包含必要的元数据。BIDS将此文件称为sidecar,heudiconv(Halchenko等,2018)或dcm2niix(Li, Morgan, Ashburner, Smith和Rorden,2016)等常用工具会自动生成这些文件。如果这些文件存在,HALFpipe将检测并使用它们。其次,某些软件工具将图像元数据存储在NIfTI头部而不是sidecar文件中。NIfTI格式定义了可以容纳元数据的字段,但根据图像文件的创建方式,这些元数据可能缺失。一些转换程序还以自由文本格式将元数据放在描述字段中。这种描述也可以自动解析和读取。第三,由于用户错误、计量单位不兼容或陈旧的技术考虑,信息可能表示不正确。在这种情况下,HALFpipe提供了一种覆盖不正确值的机制。对于每个元数据字段,用户界面将提示用户确认元数据值是否已正确读取或推断。用户可以选择手动输入正确的值。
2.4 接口
HALFpipe由需要在彼此之间传递数据(如文件路径名和质量评估程序结果)的不同模块组成。开发像HALFpipe这样大型且复杂的应用程序需要建立可预测的接口,这些接口规定了应用程序内部通信的数据格式。这种方法的一个优点是,有经验的用户可以编写自己的代码与HALFpipe接口。
HALFpipe使用Python模块marshmallow来实现接口,在该模块的命名法中称为模式。所有模式都在halfpipe.schema模块中定义。当用户首次启动应用程序时,HALFpipe会显示用户界面。它向用户询问一系列关于数据集和分析计划的问题,并将输入存储在名为spec.json的配置文件中。配置文件具有可预测的语法,可以轻松编写脚本或修改,这使协作研究能够协调分析计划。
2.5 工作流引擎
为了获得可重复的结果,HALFpipe的一个核心要求是处理流程的可重复执行。由于ENIGMA联盟需要对包含数千个样本的大型数据集进行fMRI分析,HALFpipe被设计为在多台计算机或处理器核心上并行处理。这两个规范都通过在Nipype、NeuroImaging in Python:Pipelines和Interfaces(Gorgolewski等,2011)中实现而实现。Nipype是一个神经影像工作流引擎,它构建一个无环有向图,其中节点表示需要执行的处理命令(流程的步骤),而边表示在节点之间传递的输入和输出(图像或文本文件)。在这种将神经影像流程形式化为图的方法中,可以确定跨多个处理器核心执行的最快顺序。
工作流图是模块化和可扩展的,这意味着它们可以嵌套和扩展。HALFpipe使用fMRIPrep定义的工作流,然后将这些输出连接到额外的工作流。fMRIPrep本身是模块化的,分为多个工作流:sMRIPrep(Esteban, Markiewicz, Blair, Poldrack和Gorgolewski,2021)、SDCFlows(Esteban, Markiewicz, Blair, Poldrack和Gorgolewski,2020)、NiWorkflows(Esteban, Markiewicz, Esteban等,2021)和NiTransforms(Goncalves等,2021)。工作流图有助于保存和验证中间结果,并支持用户停止和稍后重新启动处理的能力。HALFpipe还使用图来通过使用跟踪垃圾收集算法(Dijkstra, Lamport, Martin, Scholten和Steffens,1978)确定后续命令不需要哪些中间结果文件。这样,中间文件就不会在存储设备上积累。此功能作为Nipype的插件实现。
Nipype构成了在神经影像社区广泛使用的fMRIPrep和C-PAC的基础。然而,它在HALFpipe的背景下有几个相关的限制。HALFpipe能够使用不同的预处理设置变体计算特征和统计图。为了有效地执行此操作,需要尽可能重用中间结果。目前正在开发Nipype的改进第二版本,称为Pydra(Jarecka等,2020),它将能够自动检测重复的处理命令,并自动重用输出。目前,在Pydra可用之前,HALFpipe计算一个唯一标识每个预处理步骤的四字母哈希代码。在构建新的预处理命令之前,HALFpipe检查其哈希是否已添加到图中。如果存在,则重用现有命令,在多重分析或流程比较的情况下显著减少处理时间。
为说明这种方法的好处,将面部匹配任务数据集(Wakeman和Henson,2015)的参与者01输入HALFpipe,并使用三个流程计算任务对比。对于第一个流程,我们使用了表3中的推荐设置。对于第二个和第三个流程,我们使用相同的设置但禁用了ICA-AROMA。对于第二个流程,我们还将运动参数作为混淆时间序列添加到任务模型中。第三个流程不包括任何去噪或混淆时间序列删除。朴素方法是运行HALFpipe三次,每个流程一次。这种方法不是最优的,因为执行了许多重复计算。默认情况下,HALFpipe使用上述哈希方法组合所有三个流程,使处理更快。处理在AMD Ryzen Threadripper 2950X 16核处理器上进行,每次运行HALFpipe都配置为使用所有核心。表2显示了在每个流程上花费的处理时间(挂钟时间)。对于朴素方法,我们还显示了总时间。
表2. 高效的流程构建加快了多重分析

HALFpipe的另一个关键要求是对缺失数据的稳健和灵活处理。例如,缺失的功能扫描或统计图不会导致HALFpipe失败。此外,HALFpipe定义了扫描的纳入和排除标准,如允许的最大运动(平均帧间位移)或提取脑区平均信号时的最小脑覆盖率。最后,根据数据集的不同,在运行组水平模型之前,可能需要在单个受试者内跨运行或会话聚合统计图。这意味着静态图必须动态修改以适应处理结果。HALFpipe通过定义一个数据结构来解决这个问题,该结构不仅包含统计图的文件名,还包含可用于即时调整处理的标签和元数据。例如,使用这个数据结构,可以基于实际具有可用统计图的受试者构建组模型的设计矩阵。
2.6 预处理
HALFpipe的主要预处理是通过fMRIPrep完成的,它执行任何fMRI研究所需的预处理步骤的共识(Esteban, Markiewicz等,2019)。结构图像的共识步骤包括颅骨剥离、组织分割和空间标准化。功能图像的共识步骤包括运动校正、扫描层时间校正、磁敏感性失真校正、配准和空间标准化(图1)。
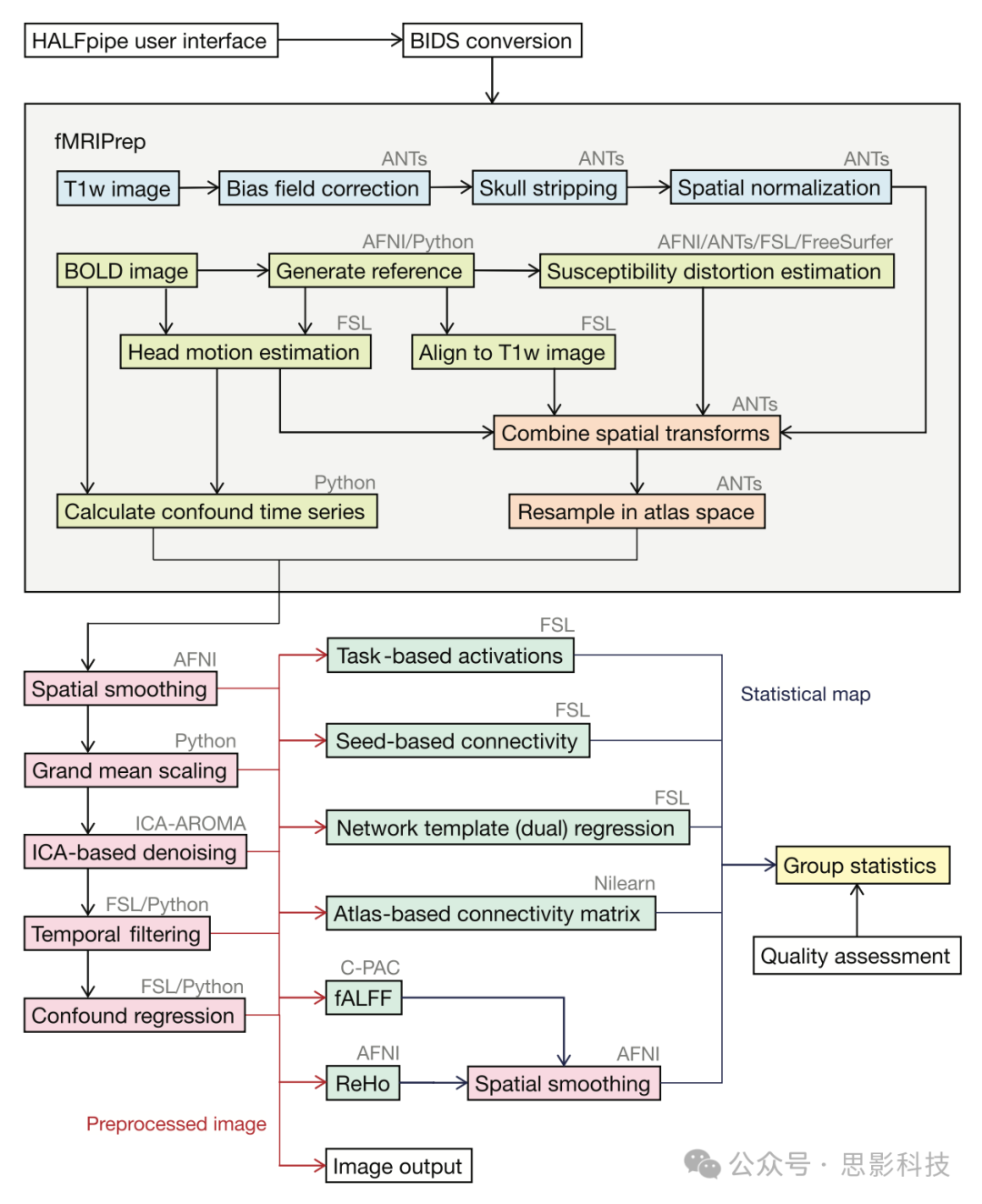
图1 HALFpipe工作流
HALFpipe在用户界面中配置,在该界面中向用户询问一系列关于其数据和要执行的处理步骤的问题。然后将数据转换为BIDS格式(Gorgolewski等,2016)以允许标准化处理(白色)。使用fMRIPrep(Esteban, Blair等,2019)对结构(蓝色)和功能(绿色和橙色)数据进行最小预处理后,可以选择额外的预处理步骤(红色)。使用预处理后的数据,可以在特征提取(青色)期间计算统计图。最后,可以执行组统计(黄色)。请注意,并非所有预处理步骤都适用于每个特征,如表3所述。为了增加视觉清晰度,该图省略了这些信息。
HALFpipe将标准空间定义为MNI152NLin2009cAsym模板,这是可用的最新和最详细的模板(Horn,2016)。请注意,标准空间模板不可由用户配置,因此HALFpipe一个版本生成的任何输出都可以轻松与HALFpipe另一个版本生成的输出进行比较。
一旦fMRI数据经过fMRIPrep处理并重采样到标准空间,HALFpipe实施了一些额外的预处理步骤,用于去噪、滤波和协调功能数据(另见图1):
ICA-AROMA是一种基于独立成分分析的算法。它将成分分类为包含信号的成分和噪声成分(Pruim等,2015)。为了实现这一点,ICA-AROMA依赖于在MNI152NLin6Asym空间中定义的参考模板,这与fMRIPrep使用的标准空间模板MNI152NLin2009cAsym不同。因此,为了允许ICA-AROMA运行,有必要不仅在默认模板空间中提供预处理图像,还要在ICA-AROMA所需的空间中提供。默认情况下,fMRIPrep将估计到这个其他模板的第二次标准化,将其应用于本机空间中的fMRI图像,并在生成的图像上运行ICA-AROMA(Ciric等,2021)。这种方法实际上使空间标准化所花费的处理器时间翻倍,并可能需要手动检查两个空间配准。
为避免这种大量工作,HALFpipe通过使用两个标准模板空间之间的现有变形(Horn,2016)实现了一种不同的方法。这个预定义的变形与fMRIPrep已经估计的标准化连接在一起,然后使用fMRIPrep的bold_std_trans_wf执行第二轮重采样。这样,只需要运行两次重采样步骤。
最后,使用fMRIPrep的ica_aroma_wf工作流在MNI152NLin6Asym空间中的生成的fMRI图像上运行基于独立成分分析的自动去除运动伪影(ICA-AROMA),该工作流还包括固定为6 mm FWHM平滑核的空间平滑。生成的分类将保留到步骤4。
HALFpipe使用AFNI的3dBlurToFWHM(Full Width at Half Maximum)实现空间平滑(Friedman, Glover, Krenz和Magnotta,2006)。每个体素的信号与周围体素的信号加权平均,权重由各向同性高斯核确定。在大脑边缘,该核可能包括非大脑体素,因此平滑受大脑掩模约束。这等同于人类连接组计划最小预处理流程中的程序(Glasser等,2013)。此外,3dBlurToFWHM估计生成图像的平滑度,并迭代降低平滑量,使生成的平滑度与用户设置匹配。这样,可以协调数据集之间的内在平滑度差异(例如,由于不同的体素大小)。
总体均值标度化将图像均值(定义为所有体素和时间点的扫描内均值)设置为预定义值。总体均值与扫描仪参数(如RF功率或放大器增益)密切相关,但与神经机制无关(Gavrilescu等,2002)。通过标度化调整总体均值使分析结果更具可解释性,并可在受试者、会话和站点之间进行比较。基于带掩模的功能图像计算标度因子,并应用于fMRI数据和fMRIPrep提取的混淆时间序列。
如果选择,则从平滑和总体均值标度化的fMRI数据中移除先前估计的ICA-AROMA噪声成分。这以非激进的方式执行,以最大限度地减少删除信号和噪声成分之间共享的方差。ICA-AROMA使用FSL命令fsl_regfilt实现此步骤,该命令为每个体素计算普通最小二乘回归,其中设计矩阵包括信号和噪声成分作为回归因子。这意味着生成的回归权重反映了噪声成分的唯一方差(而不是与信号成分共享的方差)。然后,噪声成分回归因子乘以其回归权重,这些乘积相加得到一个噪声时间序列。从体素时间序列中减去噪声得到去噪时间序列(回归残差)。使用HALFpipe中使用Numpy(Harris等,2020)的fsl_regfilt自定义重新实现完成此步骤。
可以选择时间滤波以通过高通滤波器去除低频漂移,通过低通滤波器去除高频噪声,或同时使用带通滤波器。HALFpipe实现了两种时间滤波方法,一种是基于频率的方法(Jo等,2013),另一种是基于高斯加权的方法(Marchini和Ripley,2000)。基于频率的时间滤波器在选择要保留或删除的频率方面非常精确,通常用于计算低频波动的分数幅度(fALFF)和局部同质性(ReHo)。高斯加权时间滤波器是FSL Feat(Jenkinson等,2012)使用的默认值,在时间序列的开始和结束处可能有较少的边缘效应。然而,其频谱也具有更渐进的滚降,这意味着它在去除接近所选截止值的频率时不那么积极。
重要的是,HALFpipe在进行一些修改的情况下运行fMRIPrep。例如,在没有场图的情况下,我们禁用了fMRIPrep的实验性磁敏感性失真校正,因为它尚未验证。此外,HALFpipe为每个预处理步骤提供默认设置,如表3所述。请注意,一些是基于该领域的最佳实践选择的(即ALFF和ReHo的带通时间滤波器),而大多数默认设置可以由用户调整。最后,HALFpipe默认不输出预处理和标准化的功能图像,因为它们占用大量磁盘空间。但是,在用户界面中,用户可以手动选择使用他们选择的预处理设置输出预处理的功能图像。
表3. 每个特征的预处理设置默认值
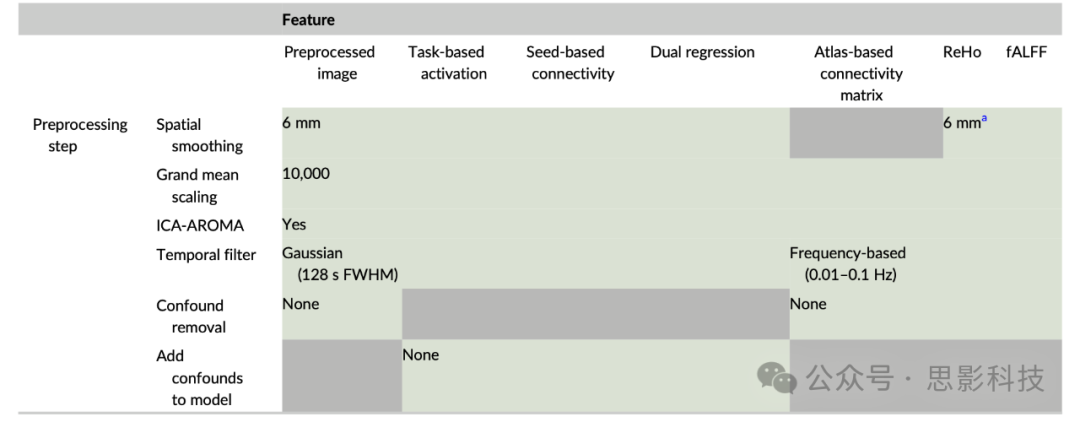
注意:灰色填充的单元格表示该选项无法在用户界面中选择,所有其他设置都可由用户调整。a 在特征提取后对统计图进行处理。
2.7 混淆时间序列去除
fMRIPrep不仅输出标准空间中的预处理图像,还输出名为confounds.tsv的含混淆时间序列的电子表格。这些包括运动参数(平方)的(导数)、aCompCor成分(Behzadi, Restom, Liau和Liu,2007)、白质信号、脑脊液信号和全局信号。在将fMRIPrep混淆时间序列与上一节概述的预处理步骤结合使用时,需要考虑一个关键问题:将混淆时间序列用作噪声回归因子与经过时间滤波或去噪的数据一起使用可能会将已删除的时间或噪声信号重新引入体素时间序列(Hallquist, Hwang和Luna,2013)。
这种现象的一个例子可能是在通过时间滤波去除低频漂移后回归一组fMRIPrep混淆时间序列。在实践中,这意味着为每个体素设置回归模型,其中体素时间序列是因变量,回归因子是混淆时间序列。回归将为每个混淆时间序列产生一个权重,使总模型解释最大方差量(假设正态分布)。将混淆时间序列乘以这些权重后,它们的乘积相加为一个包含该体素中混淆相关信号的时间序列。然后从原始体素时间序列中减去该时间序列以获得结果(即回归残差)。但是,如果混淆时间序列恰好包含任何低频漂移,那么它们的加权和也可能包含低频漂移。由此可见,从经过时间滤波的体素数据中减去具有时间漂移的时间序列将重新引入时间漂移,无论之前是否应用了时间滤波器。
在HALFpipe中,应用于体素时间序列的任何(可选)去噪或滤波也应用于fMRIPrep混淆时间序列。这样,先前去除的方差不会意外重新引入,因为它已从回归方程的两边去除。例如,当用户选择执行ICA-AROMA去噪时,相同的去噪将应用于时间fMRIPrep混淆时间序列,使用时间滤波器时也是如此。请注意,这意味着HALFpipe生成的混淆时间序列将与原始fMRIPrep混淆时间序列不同,用户在运行自定义分析时应注意使用适当的文件。
2.8 质量评估
评估数据和预处理的质量是一项费力的工作,通常手动执行。通过预定义的图像质量特征阈值(Alfaro-Almagro等,2018)或机器学习(Esteban等,2017)来自动化此过程的努力尚未准备好取代经过训练的研究人员检查数据的眼睛。然而,各种方法使这个过程更容易。首先,与直接查看三维神经影像文件相比,生成和查看包含二维图像的报告可以节省大量时间。其次,slicesdir(在FSL中)、fMRIPrep和MRIQC等工具生成包含多个报告图像的HTML文件,可以在网络浏览器中浏览。MRIQC还提供了一个交互式小部件来评估每个图像的质量(Esteban, Blair等,2019)。
在HALFpipe中,我们使用一组固定的处理步骤进行质量评估。虽然slicesdir允许研究人员轻松比较不同受试者的相同图像类型,但它不能用于生成所有类型图像的报告。相比之下,fMRIPrep/MRIQC HTML文件包含了广泛的信息和质量报告图像,但一个HTML文件始终特定于一个受试者。因此,检查多个受试者的多个处理步骤可能很麻烦。
为克服这些问题,HALFpipe提供了包含在单个HTML文件中的交互式Web应用程序。该应用程序动态加载包含图像的报告,可以处理多达数千张图像的数据集而不会影响性能。图像可以按受试者排序(如fMRIPrep/MRIQC所做的)或按图像类型排序(如slicesdir中所做的)。每个图像可以评为好、不确定或差。预定义的逻辑自动将这些评级转换为HALFpipe组统计的纳入/排除决定。此外,将图像标记为不确定使用户能够有效地检索这些图像并与同事或合作者讨论,之后可以对图像质量做出明确的决定。
2.9 组统计
HALFpipe使用FSL FMRIB局部混合效应分析(FLAME,Woolrich, Behrens, Beckmann, Jenkinson和Smith,2004)进行组统计,因为FLAME在其混合效应模型中考虑了低水平估计的受试者内方差。此外,其估计是保守的,这意味着它们对假阳性率提供了稳健的控制(Eklund, Nichols和Knutsson,2016)。
fMRI研究中的一个常见问题是大脑覆盖的空间范围可能因受试者而异。一个常见的选择是将更高水平的统计限制在每个受试者都获得的体素上。然而,在大脑覆盖范围有较大变化的情况下(在汇集多队列数据时可以预期),最终可能会从分析中排除相当大部分的大脑。为规避这个问题,HALFpipe在Numpy(Harris等,2020)中使用FLAME的重新实现。在这个实现中,为每个体素生成唯一的设计矩阵,因此只包括对给定体素有可测量值的受试者。然后,使用FLAME算法估计模型。这种列表式删除方法取决于体素完全随机缺失(MCAR)的假设,这意味着回归因子(因此统计值)独立于扫描仪覆盖范围。
对于组模型,用户可以指定包括协变量和组比较的灵活因子模型。默认情况下,这些变量的缺失值也通过列表式删除处理,但用户也可以选择在去均值设计矩阵中用零替换缺失值。后一种方法等同于用样本均值进行插补。使用Python模块Patsy(Smith等,2018)生成灵活因子模型的设计矩阵。使用lsmeans程序(Lenth,2016)指定组间对比。
2.10 在高性能集群上运行
在多个节点(如高性能集群(HPC))上部署Nipype执行计算特别具有挑战性。默认情况下,Nipype为每个处理命令(图节点)向集群队列提交单独的作业,而不考虑执行命令所需的时间。在头节点上运行的监视进程收集已完成命令的输出并提交下一个处理命令。这个过程在某些HPC上可能效率低下,因为需要不断分配和释放计算资源。我们为HALFpipe实现了一种更有效的方法,将处理图划分为许多独立的子图,用户可以将其作为单独的作业提交。可用的最小粒度是每个受试者一个子图,通过命令行标志—use-cluster自动调用。在流程开始运行之前,为所有受试者创建和验证Nipype工作流。在集群设置中,最有效的资源利用是将每个受试者作为单独的作业提交,并在两个CPU核心上运行每个作业。
2.11 程序
HALFpipe启动为基于终端的用户界面,提示用户回答一系列关于正在分析的数据集和所需分析计划的问题。HALFpipe分析的主要阶段(详见下文)包括加载数据、使用fMRIPrep预处理、质量评估、特征提取和组水平统计。用户可以灵活地一次性指定每个处理阶段的设置,或在每个阶段分别指定。如果HALFpipe在中间阶段停止并恢复,HALFpipe将检测已完成的阶段,并要求用户指出所需的进一步分析。例如,用户可以请求预处理和特征提取,但不进行组水平统计,稍后恢复处理时仅指定组水平统计。
2.12 加载数据
HALFpipe的一个主要优点是它接受以各种格式组织的输入数据,无需文件命名约定或特定目录结构。使用终端界面,要求用户提供T1加权和fMRI BOLD图像文件的位置(预处理所需),以及场图和任务事件文件(如果可用或适用)。然而,HALFpipe需要额外的信息将图像文件链接起来以自动运行,例如指定哪组图像属于同一受试者的信息。
通过使用路径模板,HALFpipe可以处理各种文件夹结构和数据布局。路径模板的语法改编自C-PAC的数据配置(Giavasis, Pellman, Clucas和Lurie,2020)。与在SPM或FSL用户界面中手动为每个受试者分别添加每个输入文件不同,模板描述了用于命名文件的模式。该模式可以匹配许多文件名,从而减少用户的手动工作量。例如,当在文件路径{subject}_t1.nii.gz中放置标签{subject}时,将选择所有以_t1结尾且扩展名为.nii.gz的文件。解析算法现在将文件名中_t1之前的部分解释为受试者标识符。当来自不同模态的多个文件具有相同的受试者标识符、会话号等时,它们将通过这些标签自动匹配。然后可以围绕生成的数据结构构建自动处理工作流。
与C-PAC的数据配置语法相比,HALFpipe路径模板使用BIDS标签(Gorgolewski等,2016)。HALFpipe路径模板可以通过在标签名称后添加冒号和正则表达式(如标准Python正则表达式语法)进一步指定。例如,{subject:[0-9]}只匹配仅包含数字的受试者标识符。这对于更复杂的数据布局很有用,例如当多个数据集放在同一目录中,并且只使用单个子集时。更多示例见表4。
表4. 路径模板语法示例

在HALFpipe用户界面中,用户可以获得有关匹配的文件数量和类型的反馈,因此可以交互式输入路径模板。重要的是,通过用户界面完成配置过程后,所有文件都会内部转换为标准化的BIDS结构,这是运行fMRIPrep的先决条件。但是,不会复制文件,转换完全基于原始文件的符号链接(别名)。如果数据已经是BIDS格式,HALFpipe仍会进行此转换以保持一致性。然后,BIDS格式的结果数据集存储在工作目录的名为rawdata的子文件夹中。
2.13 质量评估
质量评估可以在交互式的基于浏览器的用户界面中执行(见图2)。HALFpipe提供了详细的质量评估用户手册,可在网页上链接。Web应用程序显示了几个预处理步骤的报告图像,如T1颅骨剥离和标准化、BOLD时序信噪比、运动混淆、基于ICA的伪影去除和空间标准化(参见质量评估方法部分)。这些图像可以由查看者进行视觉检查并评级为好、不确定或差。
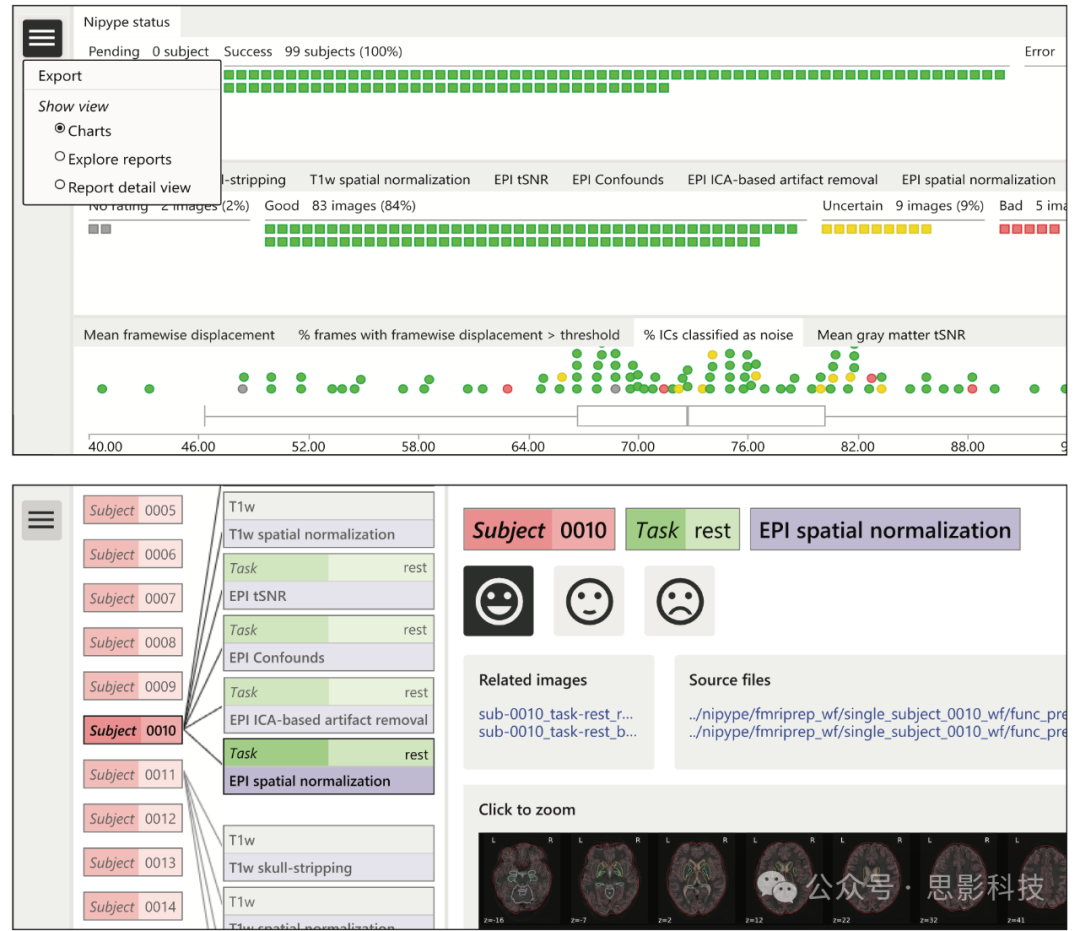
图2 质量评估用户界面
顶部面板显示图表视图,包含一个处理状态图表、一个质量评级图表和一个图像质量指标图表。在左上角,导航菜单打开,显示导出评级以用于组统计的选项。底部面板包含浏览器视图的截图,允许用户在受试者和图像类型之间导航。浏览器视图在右侧显示当前选定的报告图像,以及其评级、相关图像和用于构建它的源文件。通过点击图像或在导航菜单中选择报告详细视图,可以使用鼠标缩放和平移图像。
评级将保存在本地浏览器存储中。完成后,可以以JSON格式下载以供HALFpipe读取。如果放在工作目录中,HALFpipe将自动检测评级并用于排除组水平统计的受试者。此外,HALFpipe将自动检测所有名称以exclude开头的其他JSON文件,以适应多个研究人员的质量评估。在评级发生冲突的情况下,将使用较低的评级。
HALFpipe将尽可能多地包含数据,同时排除所有评级为"差"的扫描。评级为"好"和"不确定"的将包含在组分析中。任何与结构/解剖处理相关的报告图像的"差"评级将排除整个受试者。任何与功能图像处理相关的报告图像的"差"评级将仅排除特定的功能扫描。这意味着如果受试者有一个"差"的扫描,其他扫描仍可能包含在组统计中。
此外,以箱线图显示了所有受试者的平均帧间位移、高于指定阈值的帧间位移的帧百分比、被分类为噪声的独立成分百分比和平均灰质时序信噪比。在报告图像旁边显示源图像的链接,这样可以通过在首选图像查看器(例如fsleyes)中打开它们来更详细地检查这些图像。
通过点击可以放大图像。为了让高级用户操作更快,评级和导航不仅可以通过用户界面按钮访问,还可以通过基于WASD键的键盘快捷键访问。按A键回到上一个图像,D键前进,而W、S和X键分别将图像评级为好、不确定或差。Web应用程序提供了一个概览图表,指示预处理成功的受试者和出错的受试者,一个质量评级图表,以及反映运动、噪声成分和时序信噪比(tSNR)样本分布的箱线图。这三个都实现了用户可以将光标悬停在图表元素上以查看元信息(如受试者标识符)并点击以导航到相关报告图像的功能。HTML文件是使用TypeScript构建的无框架Web应用程序。源代码可在https://github.com/HALFpipe/QualityCheck 获取。
HALFpipe为每个受试者显示两个结构/解剖处理的报告图像,以及每种功能扫描类型的四个额外图像。详细说明可在https://github.com/HALFpipe/HALFpipe#quality-checks 的质量评估手册中找到。
-
T1w颅骨剥离显示偏场校正的解剖图像,用红线勾勒出大脑掩模。用户必须检查掩模中没有缺少大脑区域,且掩模中不包含头骨或头部部分。
-
T1w空间标准化显示重采样到标准空间的解剖图像,叠加了标准空间中的大脑图谱。用户需要检查图谱的区域是否与重采样图像紧密匹配。
-
回波平面成像(EPI)时序信噪比显示使用fMRIPrep预处理后的功能图像的时序信噪比。用户必须检查信号恢复在整个大脑中均匀分布,并排除具有不对称、失真、局部信号丢失或条纹伪影的扫描。
-
EPI混淆显示由fMRIPrep生成的地毯图(Aquino, Fulcher, Parkes, Sabaroedin和Fornito,2020; Power,2017)。地毯图是扫描内时间序列的二维图,时间在x轴上,体素在y轴上。体素分为皮层灰质(蓝色)、皮层下灰质(橙色)、小脑(绿色)以及白质和脑脊液(红色)。地毯图上方是帧间位移(FD)、全局信号(GS)、脑脊液中的全局信号(GSCSF)、白质中的全局信号(GSWM)和DVARS(时间序列的时间导数D和体素上均方根方差VARS)的幅度(y轴)的时间过程(x轴)。用户必须查看热图/强度变化与上方的运动和信号变化的关系。地毯图中的突变可能对应于运动峰值,而延长的信号变化可能表示由扫描仪硬件缺陷引起的采集伪影。
-
基于EPI ICA的伪影去除显示从每个ICA成分提取的平均信号的时间过程及其分类为信号(绿色)或噪声(红色)。此图由fMRIPrep生成。对于每个成分,都有一个空间图(左侧)、时间序列(右上)和功率谱(右下)。用户必须检查分类为噪声的成分不含已知为信号的大脑网络或时间模式。
-
EPI空间标准化显示使用fMRIPrep预处理后的功能图像,叠加了标准空间中的大脑图谱。如前所述,用户必须检查图谱的区域是否与重采样图像紧密匹配。
2.14 特征提取
预处理后,HALFpipe可以提取静息态和任务态分析中常用的几个特征。这些包括检查大脑区域之间功能连接的各种方法(基于种子点的连接、网络模板(或双重)回归、基于图谱的连接矩阵),以及局部活动的度量(ReHo、fALFF)。HALFpipe允许用户选择几个感兴趣区掩模(种子点)、模板网络和图谱,阈值指示用户要求的种子点、模板网络或图谱区域与受试者fMRI数据之间的最小重叠。对于每个特征,用户可以更改空间平滑和时间滤波的默认设置,并选择要去除的混淆。用户可以选择多次提取相同的特征,每次改变预处理、混淆和去噪设置,以探索多重分析中分析决策的影响。值得注意的是,对于选定的特征,某些选项不可用。例如,对于基于图谱的连接矩阵禁用空间平滑(Alakörkkö, Saarimäki, Glerean, Saramäki和Korhonen,2017),或在计算ReHo和fALFF之后执行空间平滑(见表3)。
方框1中提供了特征的简要说明。
2.15 组水平统计
可以使用FSL的FLAME算法对个体特征进行组水平统计。在交互式质量评估中具有较差质量数据的受试者被排除。此外,可以通过选择允许的最大平均帧间位移(FD)和异常帧百分比(即,运动高于指定FD阈值的帧)来基于运动排除受试者。
对于组水平统计,用户可以选择仅计算截距(即所有受试者的平均值)或运行灵活因子模型。对于后者,HALFpipe提示用户指定包含受试者ID、组成员资格和其他变量的协变量文件的路径(支持多种文件格式),并指定这些变量是连续的还是分类的。协变量文件中的缺失值可以通过列表式删除或均值替换处理。用户可以指定变量之间的主效应和交互作用,同时也可以进行针对连续变量(例如症状严重程度)的组内回归。
2.16 输出
计算完成后,所有输出都可在工作目录中访问。fMRIPrep的输出存储在derivatives/fmriprep文件夹中,类似于在HALFpipe之外运行fMRIPrep的情况。derivatives文件夹还包含halfpipe文件夹,其中包含生成的任何预处理图像和特征。就像fmriprep文件夹一样,halfpipe文件夹符合BIDS派生数据集标准(BIDS贡献者,2021)。这意味着所有文件名以标准化方式包含结构化信息,如受试者ID sub-01或特征的给定名称feature-seedConn,这可能与原始文件命名不同。为符合BIDS,从受试者ID、会话ID等中删除下划线、破折号和其他非字母数字字符。HALFpipe的标准化输出文件命名意味着可以轻松自动化额外的分析步骤。
组统计的输出放在类似的文件夹结构中,便于共享协作元分析项目的汇总统计。
| 方框1. HALFpipe特征概述 任务态激活 对事件相关或区块设计运行一级一般线性模型(GLM)。描述每个任务条件刺激呈现的GLM回归因子与双伽马HRF进行卷积,使用FSL FILM(Woolrich, Ripley, Brady和Smith,2001)对大脑中的每个体素拟合整体模型。测试感兴趣的对比,这将产生任务条件之间比较的全脑任务激活图。 基于种子点的连接 从由二值掩模图像定义的种子点感兴趣区(ROI)提取平均BOLD时间序列。该时间序列用作一级GLM中的回归因子,使用fsl_glm对大脑中的每个体素拟合模型。这将产生全脑功能连接图,表示ROI与大脑中每个体素之间的连接强度。 网络模板(或双重)回归 使用fsl_glm的双重回归(Beckmann, Mackay, Filippini和Smith,2009)生成连接网络(例如,默认模式、突显性、任务正网络)的受试者特异性表征。在第一个回归模型中,将网络模板图集回归到个体fMRI数据,这为每个模板网络生成时间序列。接下来,运行第二个回归模型,将网络时间序列回归到个体fMRI数据。这为每个模板网络生成受试者特异性空间表示,可以认为代表每个网络内的体素连接强度。
基于图谱的连接矩阵 使用受Pypes(Savio, Schutte, Graña和Yakushev,2017)和Nilearn(Abraham等,2014)启发的自定义代码从所选大脑图谱的每个区域提取平均时间序列。使用Pandas(McKinney,2010)计算图谱区域之间的成对连接矩阵,使用皮尔逊积矩相关,表示图谱中包含的所有区域对之间的成对功能连接。 局部一质性(ReHo) 使用AFNI(Taylor和Saad,2013)附带的FATCAT的3dReHo,使用肯德尔一致性系数(Zang, Jiang, Lu, He和Tian,2004)计算给定体素及其最近邻体素之间时间序列的局部相似性(或同步性)。 低频振幅分数(fALFF) 计算BOLD信号中低频振幅的方差,将低频范围(0.01-0.1 Hz)的功率除以整个频率范围的功率(Zou等,2008),使用C-PAC实现fALFF的自定义版本。 |
3 讨论
大样本对最近的神经影像学应用至关重要,如影像-遗传关联研究、复杂机器学习模型的训练,甚至无监督学习。这种需求刺激了汇集多个观察性研究数据的努力,这些研究通常比事先设计用于解决特定科学问题的研究产生更大的偏差。在ENIGMA内,我们开发了HALFpipe来支持跨多个实验室和队列的任务态和静息态fMRI数据分析和质量评估的协调。HALFpipe通过在Singularity(Kurtzer, Sochat和Bauer,2017)和Docker(Docker Inc.)发布中容器化所需组件,将所有软件工具、库函数和其他依赖项打包在一起。容器化确保提供所有软件依赖项和运行时环境。因此,无论安装在笔记本电脑、计算集群还是云计算服务等任何计算环境中,像HALFpipe这样的容器化软件都能可靠运行(Grüning等,2018)。
HALFpipe工作流程的设计、实现和测试促使其1.0版本在2021年初发布。来自29个ENIGMA PTSD联盟站点的数千个静息态fMRI数据集已经作为首个使用HALFpipe的发表报告的一部分进行了分析(Weis,2020),而其他大型多站点数据集的分析目前正在ENIGMA工作组进行,包括ENIGMA任务态fMRI工作组(Veer等,2019)。运行HALFpipe每台计算机或集群节点需要约8-20 GB的RAM,在单个处理器核心上需要6-10小时才能完成。确切的资源使用情况取决于体素分辨率和fMRI数据中的体积数。用户选择的特征数量对处理时间的影响可以忽略不计。
HALFpipe用户体验包括交互式用户界面,以促进快速分析原型设计,同时保留通过JSON格式的配置文件脚本自动分析大型数据集的能力,配置文件详细规定了数据集、分析步骤和输入参数。重要的是,HALFpipe可以同时协调处理任务态和静息态fMRI数据,这有助于两种fMRI模态之间的跨模态比较(例如,Kerestes, Chase, Phillips, Ladouceur和Eickhoff,2017)。
我们对HALFpipe的实现使用户能够以高度统一的方法应用来处理联盟多队列fMRI数据分析。具体来说,我们建立了一个标准化的流程和分析方法,涉及预先指定的:(a)软件工具集,(b)每个工具的软件版本,(c)用户定义的参数集,(d)分析步骤序列,(e)质量评估流程,和(f)排除不合格数据的标准。因此,HALFpipe在进行组水平统计之前,促进了在每个站点和/或队列无缝实施标准化流程(预处理和特征提取)。这种能力有望通过支持执行数百或数千样本的多站点多队列研究来显著推进基础神经科学,特别是临床神经科学—最终支持协调的跨疾病比较。虽然不是HALFpipe工作流程的一部分,但神经影像学的跨站点/平台协调技术最近经历了巨大增长(Fortin等,2018; Pezoulas, Exarchos和Fotiadis,2020; Wachinger等,2021)。这种方法创新很大程度上是在早期遗传数据跨平台协调发展的基础上出现的(Borisov等,2019; Haghverdi, Lun, Morgan和Marioni,2018; Johnson, Li和Rabinovic,2007; Pontikos等,2017)。预计这些神经影像数据协调方面的进展将与HALFpipe等标准化工作流程产生协同作用,因为这两个要素对大规模影像联盟工作都是必不可少的(Thompson, Jahanshad等,2020)。
fMRI数据质量指标的实施一直是一个渐进的过程,稳步朝着建立基于经验的最佳实践迈进。历史上,质量标准在研究实验室之间的应用并不均衡。近年来,人们对系统和原则性质量指标在最小化混淆因素(例如,运动伪影(Murphy, Birn和Bandettini,2013; Power等,2014; Power, Barnes, Snyder, Schlaggar和Petersen,2012))和广泛的fMRI信号偏转(Aquino等,2020)方面的基本作用有了更高的认识。自动化质量控制方法正在开发并受到越来越多的关注,如MRI质量控制软件MRIQC(Esteban等,2017)。HALFpipe采用了MRIQC部分功能,通过基于Web浏览器的界面提供增强的用户体验来生成质量报告,以促进快速查看、筛选和选择要纳入或排除的个体受试者数据。统一质量评估程序的应用在mega分析甚至meta分析多站点/扫描仪数据时特别重要,这在ENIGMA中进行。也就是说,如果没有跨站点统一实施质量评估,按站点分类的研究变量更有可能导致混淆(例如,Wachinger等,2021)。通过其协调的质量程序,HALFpipe旨在最小化此类效应。
3.1 局限性
不同站点之间可能不同的计算平台已知会由于操作系统和硬件而在输出中引入微小差异(Gronenschild等,2012)。在HALFpipe处理之前在一个中心站点收集原始多站点数据可确保使用相同的计算平台处理所有数据。虽然这是最优的,但由于数据共享的限制,这通常不切实际,即使数据完全去标识化(即无法再将数据链接到受保护的健康或其他敏感信息)。
HALFpipe通过统一处理fMRI数据提供协调,但其他非统一性来源超出了其范围。跨站点/平台协调的最新进展可能还会纠正站点、扫描仪硬件或不同处理器上计算的差异(Fortin等,2018; Pezoulas等,2020; Wachinger等,2021)。这些方法可以应用于提取的HALFpipe特征,通过集中式或使用COINSTAC(Plis等,2016)等工具的分布式计算,产生可能更具普遍性的结果。
4 结论
HALFpipe提供了一个标准化的工作流程,涵盖了任务态和静息态fMRI分析的基本要素,建立在fMRIPrep开发者的进展和贡献基础之上,并通过多样化的后处理功能将功能扩展到预处理步骤之外。HALFpipe代表了解决功能神经影像学可重复性危机的重要一步,它提供了一个工作流程,该工作流程维护用户选项的细节、分析中执行的步骤、与分析相关的元数据、代码透明度、容器化安装和重新创建运行时环境的能力,同时实现功能神经影像学社区采用的基于经验支持的最佳实践。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









