







 本文介绍了知识蒸馏的概念,一种通过复杂Teacher模型将知识传授给简化Student模型的模型压缩方法。重点讲解了Teacher-Student模型,softmax层的作用以及如何利用软标签进行训练,以提升Student模型的泛化能力和效率。
本文介绍了知识蒸馏的概念,一种通过复杂Teacher模型将知识传授给简化Student模型的模型压缩方法。重点讲解了Teacher-Student模型,softmax层的作用以及如何利用软标签进行训练,以提升Student模型的泛化能力和效率。
记录第一次写笔记,有错误欢迎补充。
刚研一,最近在看半监督学习的东西,后面的内容会慢慢补充。
目录
知识蒸馏的思想最早是来自于2015年Hinton发表的一篇论文。
知识蒸馏技术是一种模型压缩方法,是一种基于Teacher-Student模型的训练方法。
知识蒸馏(Knowledge Distillation),顾名思义就是将一个复杂的大模型的“知识”,蒸馏到一个简单的小模型中,比较类似于教师(大模型)向学生(小模型)传授(蒸馏)知识。
我们继续解读这篇论文。
1. 介绍
1.1 背景
在大规模的机器学习任务中,我们通常在训练阶段和部署阶段使用非常相似的模型,尽管它们的要求非常不同:对于语音和对象识别这样的任务,训练时必须从非常大的、高度冗余的数据集中提取信息,并且效果好的模型一般非常复杂,而且可能会使用大量的计算。
然而部署模型时是要考虑延迟以及计算资源的。
总之就是你训练和部署模型是不同的事,部署模型时就要考虑成本了。
所以模型压缩(在保证性能的前提下降低模型的复杂度)就成为了一个重要的问题,而知识蒸馏就是一种模型压缩的方法。
1.2 一种概念上的“错误”
我们通常会倾向于用学习到的参数来识别训练模型中的知识,就是要想得到等量的知识,你就得有等量的模型参数。这种想法是有问题的,因为你忽略了训练的方法。
就跟人获取知识类似,想要获取等量的知识,并不一定要学习相同的时间,你完全可以通过改变学习策略(训练方法)来用更少的时间(更简单的模型,参数更少的模型)获取等量的知识(模型的性能)。
因为模型的性能(模型更够学习到的知识量)和模型的参数量之间并不是简单的线性关系,就是说随着模型的参数量的增加并不意味着模型的性能会逐渐增大。这里面会有过拟合、计算和存储开销等问题。
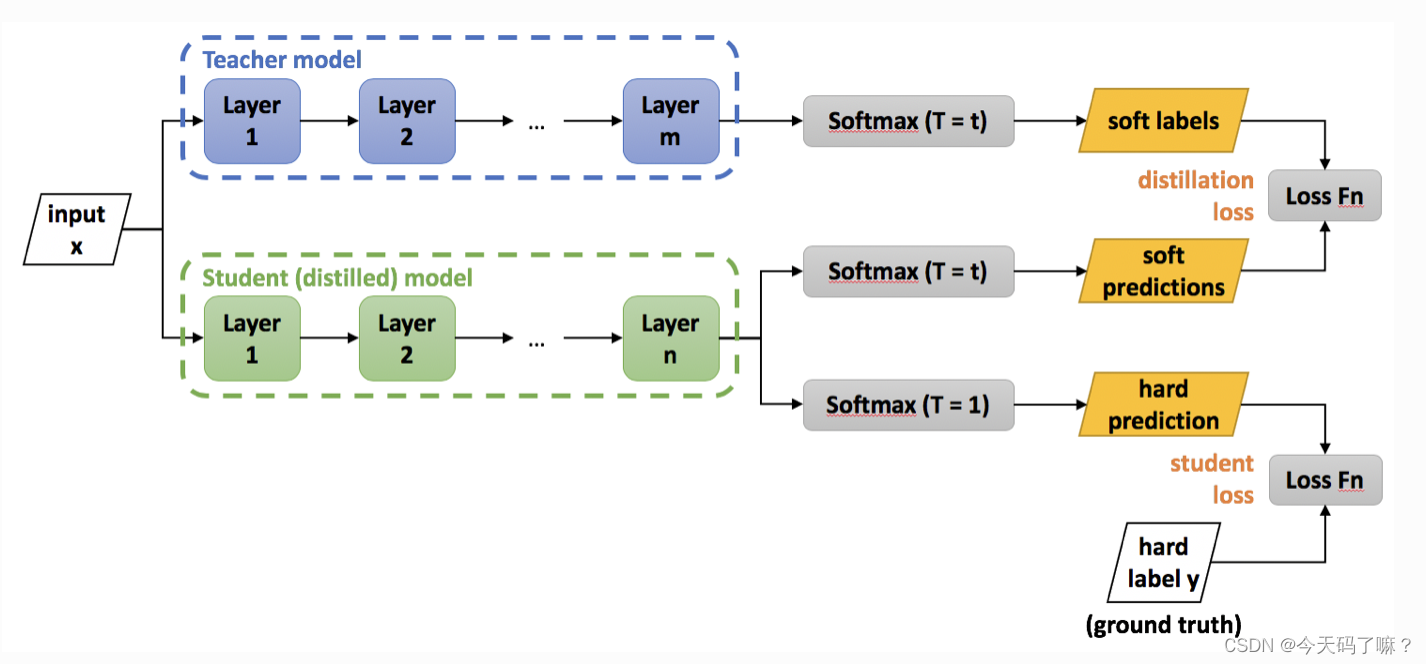
2. Teacher-Student模型
2.1 模型讲解
知识蒸馏中的Teacher-Student模型是一种训练方法,旨在通过一个复杂的Teacher Module的知识来训练一个简化的Student Module。这个过程可以帮助Student Module更好地学习和泛化,同时减少模型的计算资源和存储需求。
在Teacher-Student模型中通常有两个阶段:
- 教师模型训练: 首先训练一个较大或复杂的教师模型,它通常具有更多的参数和复杂性,并能够在训练数据上表现得更好。
- 学生模型训练: 接着,使用教师模型的输出作为辅助目标,指导较简化的学生模型进行训练。学生模型尝试去模仿教师模型的预测结果,以此来学习教师模型的“知识”。
在训练学生模型时,通常会利用教师模型的软标签(soft labels)或教师模型的隐藏层表示(logits)作为额外的监督信号,结合有标签数据进行训练。这个过程中,学生模型的目标是尽量拟合教师模型的预测结果,并同时拟合真实的标签信息。
我们知道,机器学习的目标是要训练一个泛化能力很强的模型,但是在现实生活中,对于某个问题的数据量是很大的,并且这个数据量还会随着时间不断地增大。所以我们在训练过程中只能退而求其次在有限的数据集上建立输入与输出的关系。并且我们在训练数据集上的最优解往往只是局部最优,所以模型要有很好的泛化能力。
而在知识蒸馏的过程中,我们首先已经得到了一个复杂的,泛化能力较强的Teacher Net,我们用Teacher Net去训练Student Net时,可以让Student Net很好的去学习Teacher Net的泛化能力。
一个很高效的迁移泛化能力的方法就是:使用Teacher Net的softmax层输出的类别的概率来作为“soft target”。
解释一下什么是soft target,与之相对应的是hard target。
对于多分类问题,hard target通常以“one-hot”编码形式表示,其中每个类别对应一个位置,该位置上的值为1,其他位置为0。例如,类别总数为10,则一个样本的硬目标标签可能是[0, 0, 1, 0, 0, 0, 0, 0, 0, 0]。
而软目标是指相对于硬目标更加模糊、连续或是由概率分布组成的目标。这些概率值可能代表着对应类别的置信度或概率估计,不一定是0或1。如[0,0.01,0.9,0.01,0.01,0.01,0.01,0.01,0.03]。
softmax层的输出,除了正例之外,负标签也带有大量的信息,比如某些负标签对应的概率远远大于其他负标签。而在传统的训练过程(hard target)中,所有负标签都被统一对待。也就是说,知识蒸馏的训练方式使得每个样本给Student Net带来的信息量大于传统的训练方式。
举个例子,在手写体数字识别MNIST中,输出类别有10个,假设某个输入的“2”更加形似"3",softmax的输出值中"3"对应的概率为0.1,而其他负标签对应的值都很小,而另一个"2"更加形似"7","7"对应的概率为0.1。这两个"2"对应的hard target的值是相同的,都是"2",但是它们的soft target却是不同的,由此我们可见soft target蕴含着比hard target多的信息。也就是更多的知识。
这就解释了为什么通过蒸馏的方法训练出的Student Net相比使用完全相同的模型结构和训练数据只使用hard target的训练方法得到的模型,拥有更好的泛化能力。
2.2 softmax层
论文中对softmax函数做了一个改进:
可以看出,与原softmax函数相比,多了一个温度T。
当softmax输出的概率分布熵相对较小时,负标签的值都很接近0,对损失函数的贡献非常小,小到可以忽略不计。因此"温度T"这个变量就派上了用场。
原来的softmax函数是T = 1的特例。 T越高,softmax的output probability distribution越趋于平滑,其分布的熵也就越大,负标签携带的信息会被相对地放大,模型训练将更加关注负标签。
3. 知识蒸馏的方法
总的损失由两部分加权平均的到:
其中,是输入,
是Student model的参数,
是真实标签,
是交叉熵损失函数,
是改造后的softmax函数,
和
分别是Student model和Teacher model的Logits。
和
都是超参数。
上面的公式可以抽象成:
Teacher model 和 Student model同时输入 transfer set (这里可以直接复用训练Teacher model用到的training set), 用Teacher model产生的softmax distribution (with high temperature) 来作为soft target,Student model在相同温度T条件下的softmax输出和soft target的cross entropy就是Loss函数的第一部分。
其中,
其中和
分别是Student model和Teacher model的Logits。
Student model在T=1的条件下的softmax输出和ground truth的cross entropy就是Loss函数的第二部分。
,其中
第二部分的必要性其实很好理解: Teacher model也有一定的错误率,使用ground truth可以有效降低错误被传播给Student model的可能。打个比方,老师虽然学识远远超过学生,但是他仍然有出错的可能,而这时候如果学生在老师的教授之外,可以同时参考到标准答案,就可以有效地降低被老师偶尔的错误“带偏”的可能性。
参考知乎潘小小的文章

















 2650
2650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









