







1. 平台概述
数据加工处理是实现数据标准化的过程,包括了数据的提取、清洗、关联、比对、标识、对象化等操作,支持实时计算和离线计算,支持批量处理操作。数据传输过程支持分布式数据传输方式。在数据处理过程中,引入人工智能技术,实现结构化和非结构化数据的处理,采用图计算和内存计算技术,实现数据的价值提升。在数据处理过程中,引入模型体系和标签工程和知识图谱技术,进一步提升数据价值密度,为数据智能应用实现数据增值、数据准备、数据抽象。
2. 平台架构
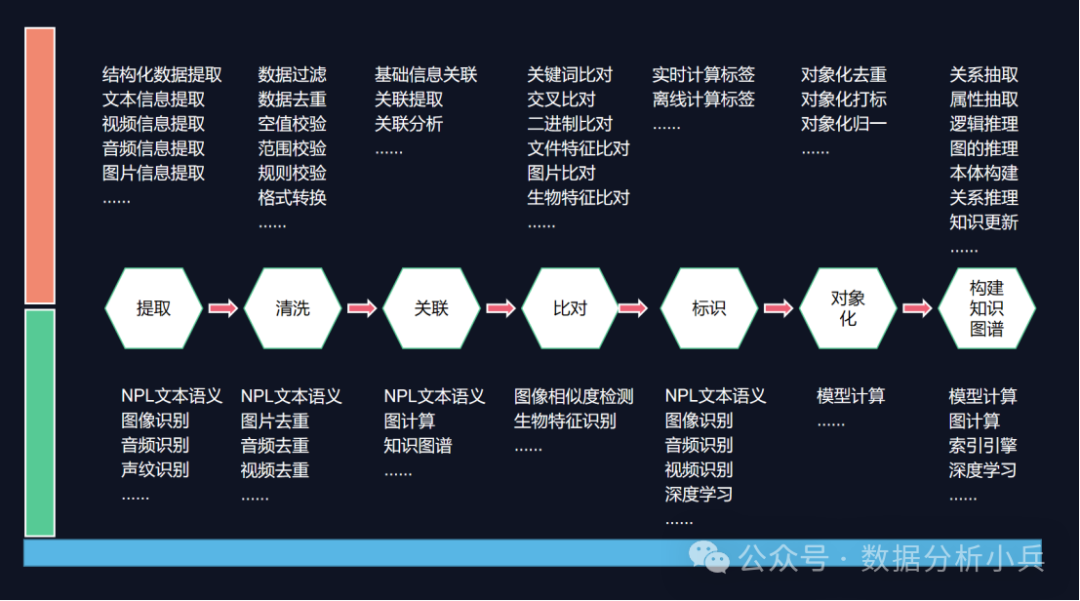
数据处理遵循相关标准,通过对数据进行提取、清洗、关联、比对、标识、对象化、构建知识图谱等规范化处理流程,实现异构数据 的标准化及深度融合。数据处理采用开放式架构,能够以统一、标准,易于扩展的方式进行数据处理流程的动态编排。同时,在各环节引入了自然语言处理、多媒体信息处理和机器学习等技术,实现对数据的智能感知和认知。
3. 数据流程
4. 平台功能
4.1. 数据提取
数据提取的过程主要是从功能各个业务系统上根据约定的采集 周期采集全量或增量数据,生成相应的文本文件。在采集过程中可能涉及系统内或跨系统的数据关联获取。这些文本文件的结构与源数据基本相同(根据具体需求可能要滤掉一些字段信息),我们称这些存放源数据的文本文件为EXF (Extract Format)。
数据抽取需要注意如下事项:
为提高ETL效率,数据在进入ETL系统后的EXF文件将转换为系统内部文件格式。
²从ETL程序设计的灵活性和整体结构的一致性考虑,尽量采用pull的方式,减少对源系统的影响和对其他开发队伍的依赖,并减少网络压力,目前最先进的方式是基于LOG捕获纯增量。
²EXF的文件格式接近数据源的数据结构定义
²在业务需求清晰明确的前提下,Extract过程中可以过滤不需要 的数据记录和字段数据转换。
数据转换过程中数据载体为文件,这样充分发挥ETL工具处理文件的强大性能和稳定性,根据数据抽取过程生成的CIF文件,经过数据清洗、数据转换、数据聚合、复杂计算以及数据匹配等处理过程,生成与目标数据结构相同的PLF (Pre-Load Format)文件。具体包含以下过程:
n数据内容数值的检查
n代码转换。包括转换为数据仓库系统自己语言
n数据内容数据格式的规范化
n參代理键的生成
n数据内容Merge
在整个数据转换过程中需要记录很多诸如出错日志、处理流程监控日志以及一些统计信息。这主要由一些公用的程序模块来完成,保证无论数据是否非法都会在我们的ETL处理范围之内。
4.2. 数据清洗
数据清洗的任务是过滤那些不符合要求的数据,将过滤的结果能够直观地展示给相应的主管部门,主管部门确认是否过滤掉或者修正之后再进行抽取。
不符合要求的数据主要有一下几类:
缺失的数据:主要是一些数据的信息准确,如物品名称、物品代号、业务系统中数据不能匹配等。在系统中用户可以自动逸过滤规则,把这一类数据过滤出来,输出到文本文件或 Excel等格式文件提交给业务用户,业务用户在人工对数据修改核对后,再写入数据仓库,如果修改的规则是固定的,也可以由系统按照规则自动添加、修改数据。
错误的数据:错误的数据生产的原因是业务系统不够健全,或者人为误操作在接手输入后没有进行判断直接写入后台数据 库造成的,这一类数据也要进行分类,不同的分类采取不同的处理方式,包括人工处理和自动处理,处理之后再更改数据库里的数据。
重复的数据:重复的数据特别是再维表中会常出现这种情况,系统可以按照规则将重复数据导出来,让用户确认并回写到数据库。
数据清洗是一个和业务用户反复沟通的过程,不可能在很短的时间内完成,只能不断的发现问题,可能解决问题。对于是否过滤,是否修正一般要求用户确认,对于过滤掉的数据要写入文本文件、Excel文件、数据库表。数据清洗需要注意的是对于每个过程规则都要认证进行验证,并要用户确认。
4.3. 数据关联
数据的多源性,导致不同来源的数据之间的关系是离散的,需要对这些离散关系进行匹配或联接,进一步提高数据可用性。
数据经过提取、清洗之后形成的数据实体,比如可以通过命名实体识别对身份证进行识别,根据两个身份证之间的共现或根据词向量计算词与词之间的相似度来判断两个人是否有关系。
4.4. 数据对比
数据比对包括结构化比对、关键词比对等,满足数据关联、线索发现、触网报警等业务需要。从数据类型上分,数据比对分为结构化数据比对、非结构化数据比对。
在数据处理过程中,数据的比对通常作为数据的查重、筛选和补充,将输入数据与已有数据进行比对关联,结构化数据主要通过数据库查询、关键字索引实现比对,非结构化数据图像、声纹等。数据比对除了在各种应用场景作为数据查询与识别的方式,在数据管理方面,将比对之后的数据进行存储、建模、标识管理,不仅可以完善数据关系、丰富数据资源库,还可以优化比对引擎,与数据应用形成良好的循环。常见的比对方式如下:
结构化数据比对:通过对数据库系统的SQL查询,来实现精确数据的比对查询。
非结构化数据比对:在海量非结构化数据中,通过AI等相关技术,提取发现数据,命中发现的相关信息。
结构化和非结构化融合比对:规则中同时支持对结构化和非结构化信息的比对,实时发现海量数据和海量全文中的相关信息。
按照数据比对的方式,数据比对又分为如下比对:
关键词比对:通过对关键词及关键词组合的比对,在海量全文数据库中命中发现关键词相关信息。
二进制比对:通过对二进制文件(如文档文件、图片文件、音视频文件等)的比对,在数据中发现二进制文件相关信息。
4.5. 数据标识
标识是对数据、数据集进行某一特征、特征的识别和认定。对数据进行标识化可以增加数据维度,拓展数据的属性,提供建立在数据之上的抽象。标识流程主要是围绕标识建立一套包括标识的定义、执行、流程管理以及可视化等功能的系统。
数据标识支持离线和在线标识。其中离线标识由离线处理引擎完成,采用离线批处理的方式进行规则处理,生成并保存标签值。离线处理引擎支持结构化和非结构化数据的处理模式。在线标识是由实时处理引擎实现,引擎结构流数据或消息数据,对数据进行实时规则处理,生成并保存标签值。实时规则处理模式支持对数据源自身的规则处理,以数据源与数据中台其他数据源进行关联分析的规则处理方式。
数据标识依托标识规则和知识库,对输入数据进行比对分析、逻辑计算,输出打上敏感级别语言、区域、位置等标识的数据,为上层应用提供支持。数据标识分为通用标识和业务标识,通用标识是数据自身所蕴含的特定含义的显性化,通常由数据的自身定义或由处理关联、比对结果等来确定。业务标识是根据不同的知识库形成具有明确业务含义的标识,对数据进行业务标识,支撑各种资源库、主题库的形成及模型分析。
在对各种数据进行标识的过程中,需要预先从策略和配置中心获取标识部分的策略和规则。
通过对用户信息的分析、提炼形成尚度精炼的自定义特征标识定义:基于标识定义并结合资源目录、规则库、模型库、算法库等应用 需求,在数据处理过程中同步对数据进行标识。根据地理、业务、安全等级和数据的敏感等级等对数据进行标识。通过人工智能(语音识 别、图像识别)和文本识别技术(NLP)对文本、图片和媒体文件进行标识。
4.6. 数据纠错
数据的标准化处理过程,按照数据标准,基本实现了自动化和智能化的处理,但是由于数据的多源异构特性,数据的庞大复杂性,对此类数据的自动化处理将是一个渐进改进的过程。在平台前期运行中,对进入各类资源库、主题库和业务库的数据需要进行准确性认定。针对有误的策略执行回滚操作,针对错误的数据中实现纠正错误数据功能。
4.7. 知识图谱建设
将各类数据,汇总融合成为人、事、地、物、组织等多类实体,根据其中的属性联系、时空联系、语义联系、特征联系等,建立相互关系,最终形成一张由人事地物组织构成的关系大网。关系网根据数据的接入可自动更新,有效解决大数据时代数据分散、割裂以及难以统一处理的问题,为系统提供多维度、可查询、可分析、可研判的数据系统。
根据展示、分析需要,可以通过扇形层次树、圆形层次树、关系网络图、柱状图、时序图等主流常规的统计分析图形来组织和展示数据,方便用户更方便、更直观、更深入、更全面地获取信息,及时应用到综合研判作战系统中去,为实际作战提供有效支撑。
大规模知识库的构建与应用需要多智能信息处理技术的支持。通过知识抽取技术,可以从一些公开的半结构化、非结构化的数据中提取出实体、关系、属性等知识要素。通过知识融合,可以消除实体、关系、属性等画像与事实对象之间的歧义,形成高质量的知识库。知识推理则是在已有的知识库基础上进一步挖掘、扩展知识库。
知识图谱逻辑架构:知识图谱在逻辑上可以分为模式层与数据层两个层次,数据层主要是由一系列的事实组成,而知识将以事实为单位进行存储。模式层构建在数据层之上,主要是通过本体库来规范数据层的一系列事实表达。本体是结构化知识库的概念模板,通过本体库而形成的知识库不仅层次结构较强,并且冗余程度较小。
知识图谱体系架构:知识图谱的体系架构是指构建模式结构,主要由自顶向下(top-down)与自底向上(bottom-up)两种构建方式。自顶向下指的是先为知识图谱定义好本体与数据模式,再将实体加入到知识库。该构建方式需要利用一些现有的结构化知识库作为其基础知识库。自底向上指的是从一些开放数据中提取出实体,选择其中置信度的加入到知识库,再构建顶层的本体模式。目前,大多数知识图谱都是采用自底向上的方式进行构建。
由于知识图谱中的知识来源广泛,存在知识质量良莠不齐、来自不同数据源的知识重复、知识间的关联不够明确等问题,所以必须要进行知识的融合。知识融合是高层次的知识组织,使来自不同的知识源的知识再同一框架规范下进行异构数据整合、消岐、加工、推理验证、更新等步骤,达到数据、信息、方法、经验以及人的思想的融合,形成高质量的知识库。
4.8. 人工智能语义分析建设
实体语义分析平台是一款集成统计学习、机器学习、深度学习等关键自然语言处理技术,具备专属语义模型建设和场景化自然语言处理流程建设能力的非结构化文本数据语义挖掘工具。致力于解决机器学习算法与业务的自动映射,提供业务建模与业务计算能力为企业实现非结构化文本落地。实现对非结构化文本进行智能处理,输出多维度业务标签,将无序的非结构化信息转换为满足业务需求的结构化数据。
可实现实体数据模型构建,高度抽象各项业务库、表,以构建对象、属性、方法的方式,对非结构化数据的重构。在通过对象、属性、方法的关系配置,实现业务数据的关系定义。目前各级机关已经逐步建立了各类公共基础信息资源库、人员社会行为动态信息资料库和业务信息系统,积累了大量的数据资源,这些数据中存在相当一部分是非结构化文本信息,由于其非结构化的特征,导致无法充分利用,不能对非结构化信息形成索引,无法建立要素的主题库,无法去执行精 确查找和匹配;缺乏支撑非结构化问题信息查询分析引擎,缺乏对一词 多义、多词一义、表达方式等中文词语、句子的在刑侦场景下的准确理解功能,导致查询结果的关联性、拓展性差。
通过智能实体语义分析平台,运用大数据的思维,可对数据进行结构化梳理,根据不同客户的不同需求,使这些数据具有结构化的特征,为维护社会安全和打击犯罪提供助力。


















 971
971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











