






神经网络的学习
一、数值微分
1、导数

# 不好的实现示例
def numerical_diff(f, x):
h = 10e-50
return (f(x+h) - f(x)) / h函数 numerical_diff(f, x) 的名称来源于数值微分 的英文 numerical differentiation。这个函数有两个参数,即“函数 f”和“传给函数 f 的参数 x”。乍一看这个实现没有问题,但是实际上这段代码有两处需要改进的地方。
(1)因为想把尽可能小的值赋给 h(可以话,想让 h 无限接近 0),所以 h 使用了 10e-50(有 50 个连续的 0 的“0.00 . . . 1”)这个微小值。但是,这样反而产生了舍入误差(rounding error)。所谓舍入误差,是指因省略小数的精细部分的数值(比如,小数点第 8 位以后的数值)而造成最终的计算结果上的误差。比如,在 Python 中,舍入误差可如下表示:
>>> np.float32(1e-50)
0.0(2)第二个需要改进的地方与函数 f 的差分有关。虽然上述实现中计算了函数 f 在 x+h 和 x 之间的差分,但是必须注意到,这个计算从一开始就有误差。如图 4-5 所示,“真的导数”对应函数在 x 处的斜率(称为切线),但上述实现中计算的导数对应的是 (x + h) 和 x 之间的斜率。
为了减小这个误差,我们可以计算函数 f 在 (x + h) 和 (x − h) 之间的差分。因为这种计算方法以 x 为中心,计算它左右两边的差分,所以也称为中心差分(而 (x + h) 和 x 之间的差分称为前向差分)。
(3)改进后的代码
def numerical_diff(f, x):
h = 1e-4 # 0.0001
return (f(x+h) - f(x-h)) / (2*h)2、偏导数
偏导数和单变量的导数一样,都是求某个地方的斜率。不过,偏导数需要将多个变量中的某一个变量定为目标变量,并将其他变量固定为某个值。
3、梯度
由全部变量的偏导数汇总而成的向量称为梯度(gradient)。
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x) # 生成和 x 形状相同的数组
for idx in range(x.size):
tmp_val = x[idx]
# f(x+h) 的计算
x[idx] = tmp_val + h
fxh1 = f(x)
# f(x-h) 的计算
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 还原值
return grad函数 numerical_gradient(f, x) 的实现看上去有些复杂,但它执行的处理和求单变量的数值微分基本没有区别。需要补充说明一下的是,np.zeros_like(x) 会生成一个形状和 x 相同、所有元素都为 0 的数组。
函数 numerical_gradient(f, x) 中,参数 f 为函数,x 为 NumPy 数组,该函数对 NumPy 数组 x 的各个元素求数值微分。现在,我们用这个函数实际计算一下梯度。这里我们求点 (3, 4)、(0, 2)、(3, 0) 处的梯度。
>>> numerical_gradient(function_2, np.array([3.0, 4.0]))
array([ 6., 8.])A
>>> numerical_gradient(function_2, np.array([0.0, 2.0]))
array([ 0., 4.])
>>> numerical_gradient(function_2, np.array([3.0, 0.0]))
array([ 6., 0.])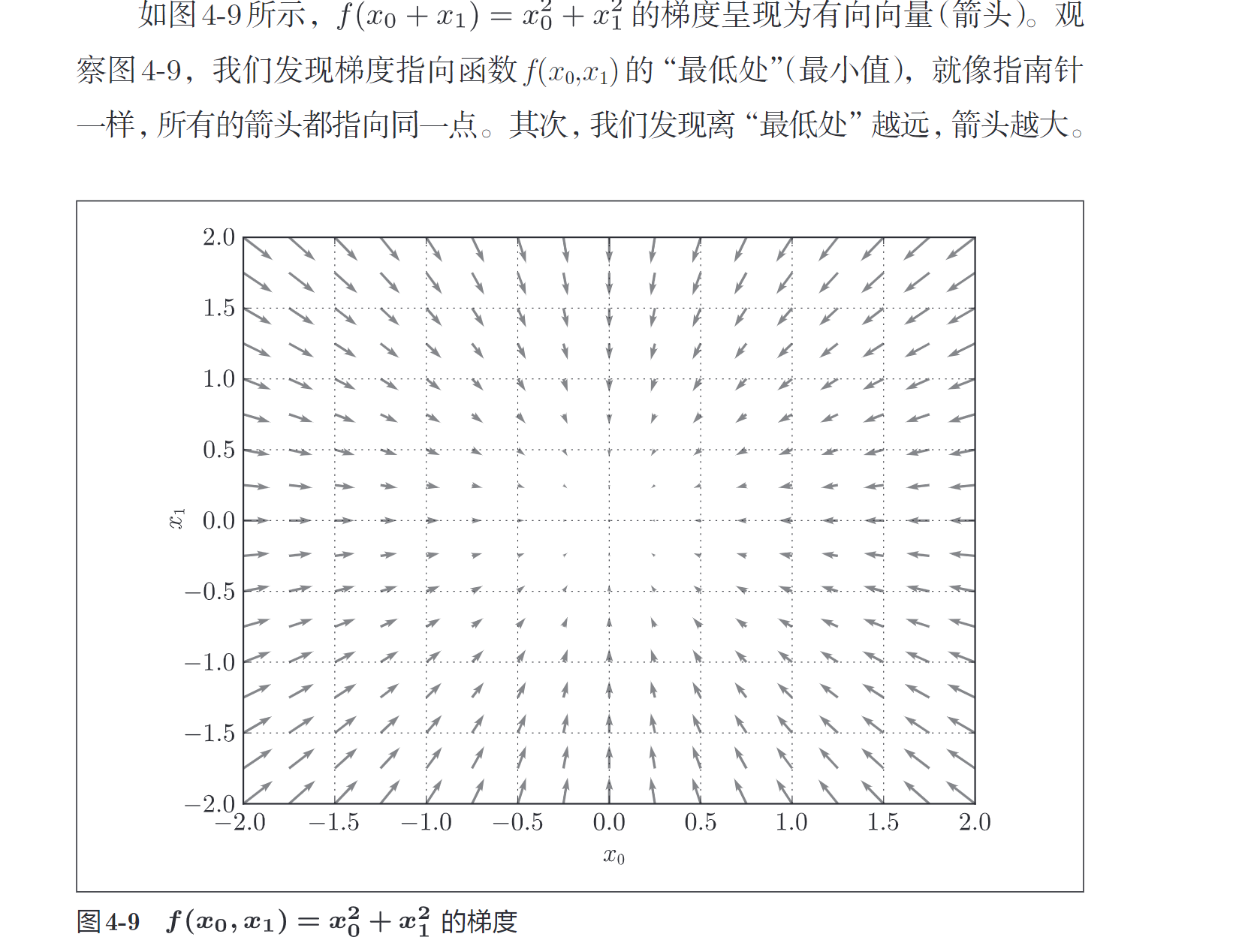
虽然图 4- 9 中的梯度指向了最低处,但并非任何时候都这样。实际上,梯度会指向各点处的函数值降低的方向。更严格地讲,梯度指示的方向是各点处的函数值减小最多的方向。
4、梯度法
(1)一般而言,损失函数很复杂,参数空间庞大,我们不知道它在何处能取得最小值。而通过巧妙地使用梯度来寻找函数最小值(或者尽可能小的值)的方法就是梯度法。
需要注意的是,梯度表示的是各点处的函数值减小最多的方向。因此,无法保证梯度所指的方向就是函数的最小值或者真正应该前进的方向。实际上,在复杂的函数中,梯度指示的方向基本上都不是函数值最小处。
注:函数的极小值、最小值以及被称为鞍点(saddle point)的地方,梯度为 0。极小值是局部最小值,也就是限定在某个范围内的最小值。鞍点是从某个方向上看是极大值,从另一个方向上看则是极小值的点。虽然梯度法是要寻找梯度为 0 的地方,但是那个地方不一定就是最小值(也有可能是极小值或者鞍点)。
(2)在梯度法中,函数的取值从当前位置沿着梯度方向前进一定距离,然后在新的地方重新求梯度,再沿着新梯度方向前进,如此反复,不断地沿梯度方向前进。像这样,通过不断地沿梯度方向前进,逐渐减小函数值的过程就是梯度法(gradient method)。
寻找最小值的梯度法称为梯度下降法(gradient descent method),寻找最大值的梯度法称为梯度上升法(gradient ascent method)。但是通过反转损失函数的符号,求最小值的问题和求最大值的问题会变成相同的问题,因此“下降”还是“上升”的差异本质上并不重要。一般来说,神经网络(深度学习)中,梯度法主要是指梯度下降法。

式(4.7)的 η 表示更新量,在神经网络的学习中,称为学习率(learningrate)。学习率决定在一次学习中,应该学习多少,以及在多大程度上更新参数。
式(4.7)是表示更新一次的式子,这个步骤会反复执行。也就是说,每一步都按式(4.7)更新变量的值,通过反复执行此步骤,逐渐减小函数值。 学习率需要事先确定为某个值,比如 0.01 或 0.001。一般而言,这个值过大或过小,都无法抵达一个“好的位置”。在神经网络的学习中,一般会一边改变学习率的值,一边确认学习是否正确进行了。
用 Python 来实现梯度下降法。如下所示,
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x参数 f 是要进行最优化的函数,init_x 是初始值,lr 是学习率 learningrate,step_num 是梯度法的重复次数。numerical_gradient(f,x) 会求函数的梯度,用该梯度乘以学习率得到的值进行更新操作,由 step_num 指定重复的次数。
学习率过大或者过小都无法得到好的结果。我们来做个实验验证一下。
# 学习率过大的例子:lr=10.0
>>> init_x = np.array([-3.0, 4.0])
>>> gradient_descent(function_2, init_x=init_x, lr=10.0, step_num=100)
array([ -2.58983747e+13, -1.29524862e+12])
# 学习率过小的例子:lr=1e-10
>>> init_x = np.array([-3.0, 4.0])
>>> gradient_descent(function_2, init_x=init_x, lr=1e-10, step_num=100)
array([-2.99999994, 3.99999992])实验结果表明,学习率过大的话,会发散成一个很大的值;反过来,学习率过小的话,基本上没怎么更新就结束了。也就是说,设定合适的学习率是一个很重要的问题。
5、神经网络的梯度


我们以一个简单的神经网络为例,来实现求梯度的代码。为此,我们要实现一个名为 simpleNet 的类
import sys, os
sys.path.append(os.pardir)
import numpy as np
from common.functions import softmax, cross_entropy_error
from common.gradient import numerical_gradient
class simpleNet:
def __init__(self):
self.W = np.random.randn(2,3) # 用高斯分布进行初始化
def predict(self, x):
return np.dot(x, self.W)
def loss(self, x, t):
z = self.predict(x)
y = softmax(z)
loss = cross_entropy_error(y, t)
return loss这 里 使 用 了 common/functions.py 中 的 softmax 和 cross_entropy_error 方法,以及 common/gradient.py 中的 numerical_gradient 方法。simpleNet 类只有一个实例变量,即形状为 2×3 的权重参数。它有两个方法,一个是用于预测的 predict(x),另一个是用于求损失函数值的 loss(x,t)。这里参数 x 接收输入数据,t 接收正确解标签。现在我们来试着用一下这个 simpleNet。
>>> net = simpleNet()
>>> print(net.W) # 权重参数
[[ 0.47355232 0.9977393 0.84668094],
[ 0.85557411 0.03563661 0.69422093]])
>>>
>>> x = np.array([0.6, 0.9])
>>> p = net.predict(x)
>>> print(p)
[ 1.05414809 0.63071653 1.1328074]
>>> np.argmax(p) # 最大值的索引
2
>>>
>>> t = np.array([0, 0, 1]) # 正确解标签
>>> net.loss(x, t)
0.92806853663411326接下来求梯度。和前面一样,我们使用 numerical_gradient(f, x) 求梯度(这里定义的函数 f(W) 的参数 W 是一个伪参数。因为 numerical_gradient(f,x) 会在内部执行 f(x), 为了与之兼容而定义了 f(W))。
>>> def f(W):
... return net.loss(x, t)
...
>>> dW = numerical_gradient(f, net.W)
>>> print(dW)
[[ 0.21924763 0.14356247 -0.36281009]
[ 0.32887144 0.2153437 -0.54421514]]numerical_gradient(f, x) 的参数 f 是函数,x 是传给函数 f 的参数。因此,这里参数 x 取 net.W,并定义一个计算损失函数的新函数 f,然后把这个新定义的函数传递给 numerical_gradient(f, x)。
注:在上面的代码中,定义新函数时使用了“def f(x):···”的形式。实际上,Python 中如果定义的是简单的函数,可以使用 lambda 表示法。使用 lambda 的情况下,上述代码可以如下实现。
>>> f = lambda w: net.loss(x, t)
>>> dW = numerical_gradient(f, net.W)6、学习算法的实现
(1)神经网络的学习分成下面 4 个步骤。
步骤 1(mini-batch)
从训练数据中随机选出一部分数据,这部分数据称为 mini-batch。我们
的目标是减小 mini-batch 的损失函数的值。 步骤 2(计算梯度)
为了减小 mini-batch 的损失函数的值,需要求出各个权重参数的梯度。梯度表示损失函数的值减小最多的方向。 步骤 3(更新参数)将权重参数沿梯度方向进行微小更新。 步骤 4(重复)
重复步骤 1、步骤 2、步骤 3。
神经网络的学习按照上面 4 个步骤进行。这个方法通过梯度下降法更新参数,不过因为这里使用的数据是随机选择的 mini batch 数据,所以又称为随机梯度下降法(stochastic gradient descent)。“随机”指的是“随机选择的”的意思,因此,随机梯度下降法是“对随机选择的数据进行的梯度下降法”。深度学习的很多框架中,随机梯度下降法一般由一个名为 SGD 的函数来实现。
SGD 来源于随机梯度下降法的英文名称的首字母。
(2)实现手写数字识别的神经网络。这里以 2 层神经网络(隐藏层为 1 层的网络)为对象,使用 MNIST 数据集进行学习。
将这个 2 层神经网络实现为一个名为 TwoLayerNet 的类,实现过程如下所示
import sys, os
sys.path.append(os.pardir)
from common.functions import *
from common.gradient import numerical_gradient
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size,
weight_init_std=0.01):
# 初始化权重
self.params = {}
self.params['W1'] = weight_init_std * \
np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * \
np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
def predict(self, x):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
return y
# x: 输入数据 , t: 监督数据
def loss(self, x, t):
y = self.predict(x)
return cross_entropy_error(y, t)
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
# x: 输入数据 , t: 监督数据
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
rads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads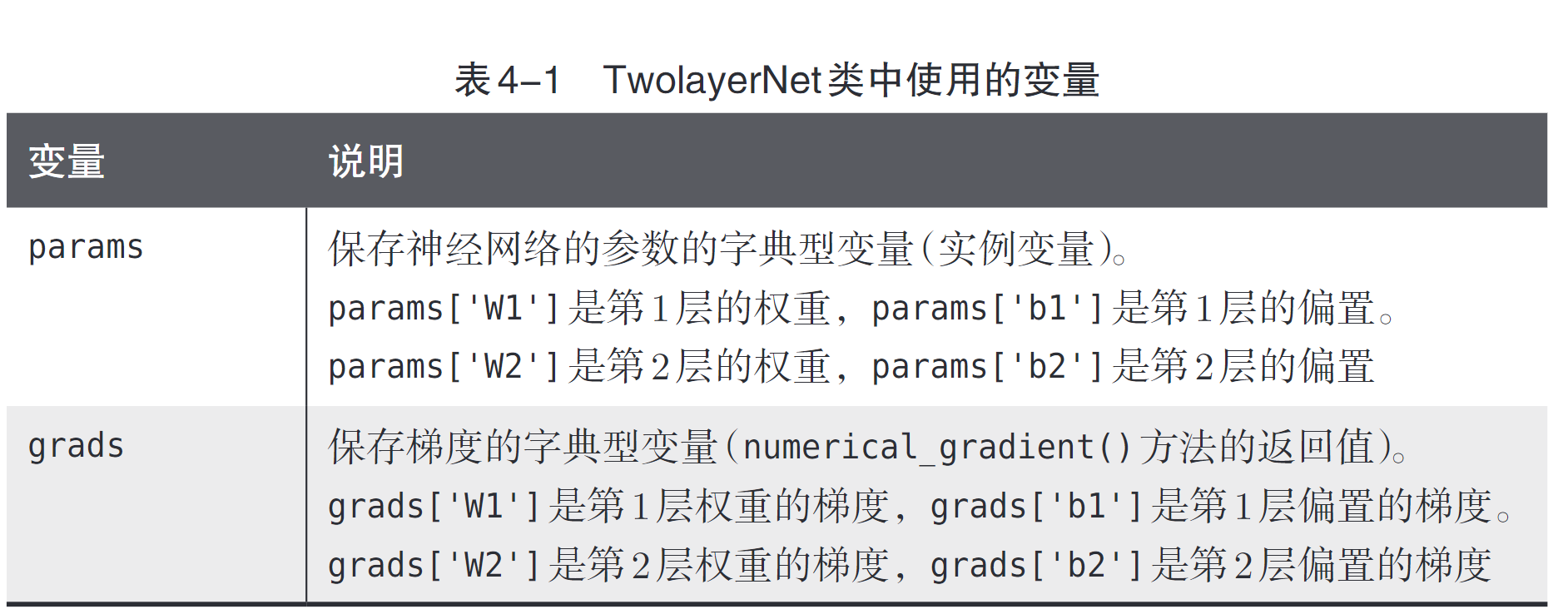

注:1、TwoLayerNet 类有 params 和 grads 两个字典型实例变量。params 变量中保存了权重参数,比如 params['W1'] 以 NumPy 数组的形式保存了第 1 层的权重参数。此外,第 1 层的偏置可以通过 param['b1'] 进行访问。这里来看一个例子。
net = TwoLayerNet(input_size=784, hidden_size=100, output_size=10)
net.params['W1'].shape # (784, 100)
net.params['b1'].shape # (100,)
net.params['W2'].shape # (100, 10)
net.params['b2'].shape # (10,)2、与 params 变量对应,grads 变量中保存了各个参数的梯度。如下所示,使用numerical_gradient() 方法计算梯度后,梯度的信息将保存在 grads 变量中。
x = np.random.rand(100, 784) # 伪输入数据(100 笔)
t = np.random.rand(100, 10) # 伪正确解标签(100 笔)
grads = net.numerical_gradient(x, t) # 计算梯度
grads['W1'].shape # (784, 100)
grads['b1'].shape # (100,)
grads['W2'].shape # (100, 10)
grads['b2'].shape # (10,)3、TwoLayerNet 的方法的实现。首先是 __init__(self,input_size, hidden_size, output_size) 方法,它是类的初始化方法(所谓初始化方法,就是生成 TwoLayerNet 实例时被调用的方法)。从第 1 个参数开始,依次表示输入层的神经元数、隐藏层的神经元数、输出层的神经元数。另外,
因为进行手写数字识别时,输入图像的大小是 784(28 × 28),输出为 10 个类别,所以指定参数 input_size=784、output_size=10,将隐藏层的个数 hidden_size设置为一个合适的值即可。
此外,这个初始化方法会对权重参数进行初始化。权重使用符合高斯分布的随机数进行初始化,偏置使用 0 进行初始化。predict(self, x) 和accuracy(self, x, t) 的实现和上一章的神经网络的推理处理基本一样。另外,loss(self, x, t)是计算损失函数值的方法。这个方法会基于 predict() 的结果和正确解标签,计算交叉熵误差。
剩下的 numerical_gradient(self, x, t) 方法会计算各个参数的梯度。根
据数值微分,计算各个参数相对于损失函数的梯度。另外,gradient(self, x, t)是下一章要实现的方法,该方法使用误差反向传播法高效地计算梯度。
7、mini-batch 的实现
(1)所谓mini-batch 学习,就是从训练数据中随机选择一部分数据(称为 mini-batch),
再以这些 mini-batch 为对象,使用梯度法更新参数的过程。
(2)以TwoLayerNet 类为对象,使用 MNIST 数据集进行学习
import numpy as np
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet
(x_train, t_train), (x_test, t_test) = \ load_mnist(normalize=True, one_hot_
laobel = True)
train_loss_list = []
# 超参数
iters_num = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
for i in range(iters_num):
# 获取 mini-batch
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 计算梯度
grad = network.numerical_gradient(x_batch, t_batch)
# grad = network.gradient(x_batch, t_batch) # 高速版 !
# 更新参数
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
# 记录学习过程
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
注:mini-batch 的大小为 100,需要每次从 60000 个训练数据中随机取出 100 个数据(图像数据和正确解标签数据)。然后,对这个包含 100 笔数据的 mini-batch 求梯度,使用随机梯度下降法(SGD)更新参数。这里,梯度法的更新次数(循环的次数)为 10000。每更新一次,都对训练数据计算损失函数的值,并把该值添加到数组中。
可以发现随着学习的进行,损失函数的值在不断减小。这是学习正常进行的信号,表示神经网络的权重参数在逐渐拟合数据。也就是说,神经网络的确在学习!通过反复地向它浇灌(输入)数据,神经网络正在逐渐向最优参数靠近。
8、基于测试数据的评价
(1)过拟合:神经网络的学习中,必须确认是否能够正确识别训练数据以外的其他数据,即确认是否会发生过拟合。过拟合是指,虽然训练数据中的数字图像能被正确辨别,但是不在训练数据中的数字图像却无法被识别的现象。
(2)神经网络学习的最初目标是掌握泛化能力,因此,要评价神经网络的泛化能力,就必须使用不包含在训练数据中的数据。下面的代码在进行学习的过程中,会定期地对训练数据和测试数据记录识别精度。这里,每经过一个epoch,我们都会记录下训练数据和测试数据的识别精度。
注:epoch 是一个单位。一个 epoch 表示学习中所有训练数据均被使用过一次时的更新次数。
import numpy as np
from dataset.mnist import load_mnist
from two_layer_net import TwoLayerNet
(x_train, t_train), (x_test, t_test) = \ load_mnist(normalize=True, one_hot_
laobel = True)
train_loss_list = []
train_acc_list = []
test_acc_list = []
# 平均每个 epoch 的重复次数
iter_per_epoch = max(train_size / batch_size, 1)
# 超参数
iters_num = 10000
batch_size = 100
learning_rate = 0.1
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
for i in range(iters_num):
# 获取 mini-batch
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 计算梯度
grad = network.numerical_gradient(x_batch, t_batch)
# grad = network.gradient(x_batch, t_batch) # 高速版 !
# 更新参数
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
# 计算每个 epoch 的识别精度
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print("train acc, test acc | " + str(train_acc) + ", " + str(test_acc))在上面的例子中,每经过一个 epoch,就对所有的训练数据和测试数据计算识别精度,并记录结果。之所以要计算每一个 epoch 的识别精度,是因为如果在 for 语句的循环中一直计算识别精度,会花费太多时间。并且,没有必要那么频繁地记录识别精度(只要从大方向上大致把握识别精度的推移就可以了)。因此,我们才会每经过一个 epoch 就记录一次训练数据的识别精度。
撰写文献综述
摘要
本研究探讨了GAN在多模态医学图像合成中的应用,特别是从脑部CT图像合成MRI图像。通过GAN合成的图像可以作为补充数据,提高诊断的准确性和可靠性。
正文
在研究中,首先从多个医疗中心收集高质量的脑部CT和MRI图像,并进行预处理,包括去噪、标准化和对齐,以确保图像质量一致。接着,通过图像配准技术将CT和MRI图像对齐,确保它们在空间上具有相同的解剖结构。然后,设计一个生成器网络,其目标是从输入的CT图像生成逼真的MRI图像。生成器通常采用卷积神经网络(CNN)结构,包含多个卷积层、激活函数(如ReLU)和上采样层。同时,设计一个鉴别器网络,用于区分生成的MRI图像和真实的MRI图像。鉴别器也采用CNN结构,包含多个卷积层和激活函数(如LeakyReLU)。
在训练过程中,将配准后的CT和MRI图像分割成小块,对每个小块进行归一化处理后,交替训练生成器和鉴别器。生成器的损失函数包括像素级损失(如均方误差MSE)和对抗损失(来自鉴别器的反馈)。像素级损失用于确保生成图像与真实图像在像素级别上的相似性,而对抗损失则鼓励生成器生成更逼真的图像以欺骗鉴别器。鉴别器的损失函数基于其对真实图像和生成图像的判别能力,通过最小化真实图像的损失和最大化生成图像的损失来训练鉴别器。
训练完成后,将生成的MRI图像块重新组合成完整的MRI图像,并通过多种指标(如结构相似性指数SSIM、峰值信噪比PSNR)和视觉检查评估生成图像的质量。与真实MRI图像进行对比,验证生成图像的逼真度和诊断价值。最后,在实际临床场景中,将生成的MRI图像作为补充数据,验证其在提高诊断准确性和可靠性方面的贡献。实验结果表明,GAN合成的图像在结构和纹理上与真实图像高度一致,并且在临床诊断中具有潜在的应用价值。
结语
GAN在脑出血图像判断领域的贡献主要体现在病变合成、图像修复、多模态图像合成、辅助诊断以及特征可视化等方面。通过生成高质量的合成图像和修复图像,GAN不仅能够增强数据集,提高诊断模型的性能,还能为脑出血的研究和治疗提供有力支持。未来,随着技术的进一步发展,GAN有望在脑出血的诊断和研究中发挥更大的作用。
参考文献
Jason Jeong J, Patel B, Banerjee I. GAN augmentation for multiclass image classification using hemorrhage detection as a case-study. J Med Imaging (Bellingham). 2022 May;9(3):035504. doi: 10.1117/1.JMI.9.3.035504. Epub 2022 Jun 23. PMID: 35769344; PMCID: PMC9232658.
Qin Z, Liu Z, Zhu P, Ling W. Style transfer in conditional GANs for cross-modality synthesis of brain magnetic resonance images. Comput Biol Med. 2022 Sep;148:105928. doi: 10.1016/j.compbiomed.2022.105928. Epub 2022 Aug 2. PMID: 35952543.
Wang T, Jiang C, Ding W, Chen Q, Shen D, Ding Z. Deep-Learning Generated Synthetic Material Decomposition Images Based on Single-Energy CT to Differentiate Intracranial Hemorrhage and Contrast Staining Within 24 Hours After Endovascular Thrombectomy. CNS Neurosci Ther. 2025 Jan;31(1):e70235. doi: 10.1111/cns.70235. PMID: 39853936; PMCID: PMC11758448.
Khan MM, Chowdhury MEH, Arefin ASMS, Podder KK, Hossain MSA, Alqahtani A, Murugappan M, Khandakar A, Mushtak A, Nahiduzzaman M. A Deep Learning-Based Automatic Segmentation and 3D Visualization Technique for Intracranial Hemorrhage Detection Using Computed Tomography Images. Diagnostics (Basel). 2023 Jul 31;13(15):2537. doi: 10.3390/diagnostics13152537. PMID: 37568900; PMCID: PMC10417300.

















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









