






Diffusion Model(扩散模型)
Diffusion Model(扩散模型)是一种基于概率生成模型的深度学习方法,通过模拟数据从噪声中逐步去噪生成样本的过程,实现高质量数据生成。其核心思想借鉴了物理学中的扩散现象,结合神经网络实现复杂数据分布的学习与采样。以下从原理、特点、应用及挑战等方面展开介绍:
一、核心原理
- 前向扩散过程(Forward Process)
-
逐步加噪:对输入数据(如图像)逐步添加高斯噪声,使其逐渐转化为纯噪声。
-
马尔可夫链建模:每一步噪声添加仅依赖前一步状态,最终数据分布趋近于高斯分布。
-
数学表达:
-
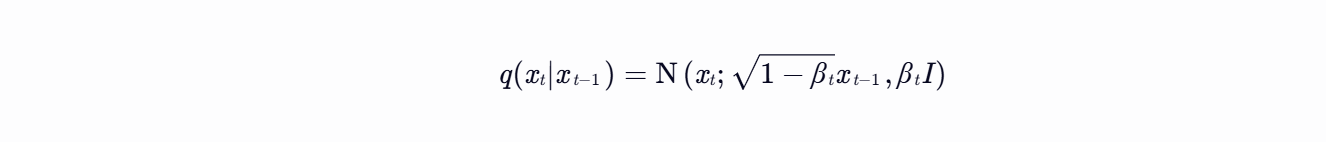
2. 反向去噪过程(Reverse Process)
-
噪声预测与去除:训练神经网络(如UNet)预测每一步的噪声分量,逐步去除噪声恢复数据。
-
参数化建模:反向过程建模为条件高斯分布:
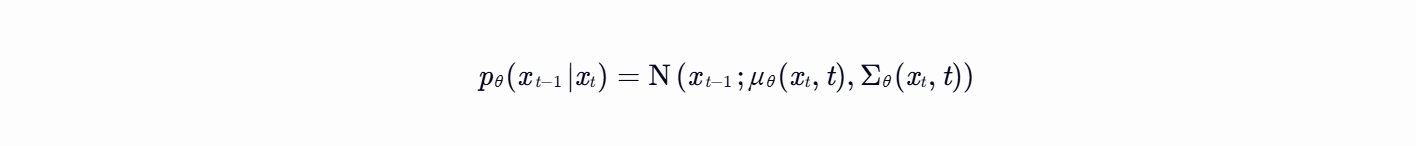
3. 训练目标
-
噪声预测损失:最小化预测噪声与真实噪声的均方误差(MSE):
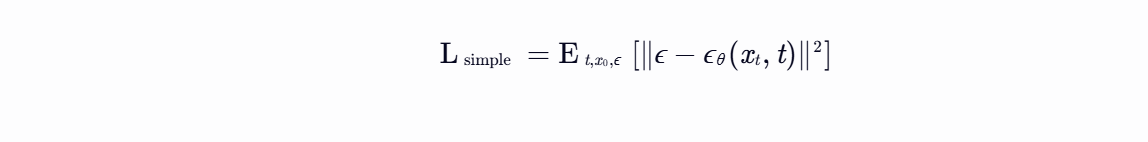
二、模型特点
- 生成质量高
- 通过多步去噪逐步细化样本,生成结果更接近真实数据分布,尤其在图像生成领域表现优异。
- 训练稳定性强
- 无需对抗训练,避免了GAN的模式崩溃、训练不稳定等问题。
- 理论支撑扎实
- 基于概率建模,具有较好的数学可解释性。
- 计算成本高
- 生成过程需多次迭代,推理速度较慢;训练时需处理高维数据,计算资源需求大。
三、典型应用
- 图像生成
- 生成高分辨率、多样化的图像,如Stable Diffusion、DALL-E 3等模型。
- 图像修复与超分辨率
- 通过去噪过程修复缺失区域或提升图像分辨率。
- 音频与视频生成
- 扩展至音频信号处理、视频帧生成等领域。
- 跨模态任务
- 结合文本条件生成图像(如Stable Diffusion支持文本提示)。
四、改进方向
- 加速采样
- DDIM(Denoising Diffusion Implicit Models):通过非马尔可夫采样减少步骤。
- 知识蒸馏:训练更小的网络模拟大模型行为。
- 条件生成优化
- 引入分类器引导(Classifier Guidance)或无分类器引导(Classifier-Free Guidance)增强生成可控性。
- 计算效率提升
- 潜在扩散模型(Latent Diffusion Models, LDM):在低维潜在空间中训练,减少计算量。
- 与其他模型结合
- 结合GAN、VAE或Transformer,融合不同模型优势。
五、与其他生成模型对比
- 与GAN对比
- 优势:生成多样性高,训练稳定;
- 劣势:生成速度慢,计算成本高。
- 与VAE对比
- 优势:生成质量更高,无需显式学习潜在分布;
- 劣势:推理复杂度更高。
六、总结
Diffusion Model通过模拟数据从噪声中逐步去噪的过程,实现了高质量的数据生成,尤其在图像生成领域展现出强大潜力。尽管存在计算成本高、生成速度慢等挑战,但通过加速采样、条件生成优化等技术改进,其应用前景广阔。未来,随着计算资源的发展和算法的优化,Diffusion Model有望在更多领域发挥重要作用。
GAN(生成对抗网络)
GAN(生成对抗网络)是一种基于深度学习的生成式模型,其核心思想是通过两个神经网络——生成器(Generator)和判别器(Discriminator)——的对抗博弈来学习数据分布,从而生成逼真的样本。以下从原理、结构、训练过程、应用、优缺点及改进方向展开详细介绍:
一、原理与结构
- 生成器(Generator)
- 功能:接收随机噪声作为输入,通过神经网络生成与真实数据相似的假样本。
- 目标:欺骗判别器,使其无法区分生成的样本与真实样本。
- 判别器(Discriminator)
- 功能:接收真实数据和生成器生成的假样本,输出一个概率值,表示样本为真实数据的可能性。
- 目标:尽可能准确地判断样本的真假。
- 对抗博弈
- 生成器和判别器通过交替优化进行对抗训练:
- 生成器努力生成更逼真的样本,降低判别器的准确率。
- 判别器努力提高区分能力,准确识别真假样本。
- 最终,生成器生成的样本与真实数据分布几乎无法区分,判别器无法再准确判断样本的真假。
- 生成器和判别器通过交替优化进行对抗训练:
二、训练过程
- 初始化
- 随机初始化生成器和判别器的参数。
- 训练判别器
- 从真实数据分布中采样一批真实样本。
- 从生成器中生成一批假样本。
- 将真实样本和假样本输入判别器,计算损失函数(如二元交叉熵损失)。
- 更新判别器的参数,使其最大化对真实样本的预测概率,同时最小化对假样本的预测概率。
- 训练生成器
- 从生成器中生成一批假样本。
- 将假样本输入判别器,计算损失函数(如将判别器对假样本的预测概率作为生成器的奖励)。
- 更新生成器的参数,使其最大化判别器对假样本的错误预测概率。
- 迭代优化
- 交替训练生成器和判别器,直到达到纳什均衡(生成器和判别器的能力不再显著提升)。
三、应用领域
- 图像生成
- 生成逼真的人脸、风景、动物等图像。
- 典型应用:StyleGAN、BigGAN等模型。
- 图像修复与超分辨率
- 修复图像中的缺失部分或去除噪声。
- 将低分辨率图像转换为高分辨率图像。
- 风格迁移
- 将一幅图像的风格迁移到另一幅图像上,生成具有特定艺术风格的图像。
- 文本生成
- 生成自然语言文本,如对话、故事、诗歌等。
- 典型应用:SeqGAN、LeakGAN等模型。
- 数据增强
- 生成更多的训练样本,增强模型的泛化能力。
- 视频生成
- 预测视频中的下一帧或生成动态视频。
四、优缺点
- 优点
- 生成质量高:GAN生成的样本通常具有较高的真实感和多样性。
- 无需显式建模数据分布:通过对抗训练隐式学习数据分布。
- 适用于无监督学习:无需大量标注数据,适用于无监督或半监督学习任务。
- 缺点
- 训练不稳定:生成器和判别器的训练过程可能难以收敛,容易出现模式崩溃或梯度消失问题。
- 模式崩溃:生成器可能只生成有限种类的样本,忽略数据分布中的其他模式。
- 评估困难:缺乏有效的量化指标来评估生成样本的质量。
- 对超参数敏感:训练过程对网络结构、学习率、优化器等超参数的设置较为敏感。
五、改进方向
- 改进训练稳定性
- WGAN(Wasserstein GAN):使用Wasserstein距离代替JS散度,缓解梯度消失问题。
- LSGAN(Least Squares GAN):使用最小二乘损失函数,提高训练稳定性。
- 谱归一化(Spectral Normalization):对判别器的权重进行归一化,限制Lipschitz常数。
- 缓解模式崩溃
- Mini-batch Discrimination:在判别器中引入样本间的关系信息,鼓励生成多样化的样本。
- Unrolled GAN:在训练生成器时考虑判别器的未来更新,避免生成器过度适应当前判别器。
- 改进评估指标
- Inception Score(IS):评估生成样本的多样性和质量。
- Fréchet Inception Distance(FID):比较生成样本与真实样本的特征分布差异。
- 结合其他技术
- 条件GAN(Conditional GAN):在生成器和判别器中引入条件信息,控制生成样本的类别或属性。
- CycleGAN:实现无监督的图像到图像转换,如将马转换为斑马。
- BigGAN:通过增大网络规模和批量大小,生成更高质量的图像。
文献综述
Diffusion Model与GAN在医学图像生成中的协同演进与未来展望
在医学影像分析领域,生成模型正以突破性的姿态重塑疾病诊断、治疗规划及药物研发的范式。扩散模型(Diffusion Model)与生成对抗网络(GAN)作为两大主流技术路径,各自凭借独特的理论机制与算法优势,在医学图像生成赛道上展现出互补性价值。随着NeurIPS 2023等顶会研究的推进,两种模型的对比与融合趋势愈发清晰,为未来医疗AI的智能化升级提供了关键技术支撑。
理论机制:非平衡热力学与对抗博弈的碰撞
扩散模型的核心逻辑源于非平衡热力学中的扩散过程。通过正向扩散将原始数据逐步“淹没”于高斯噪声,再通过反向去噪实现数据重构,其训练过程本质是条件概率分布的逼近。NeurIPS 2023提出的标签检索增强扩散模型(LRA-Diffusion)通过引入预训练编码器(如CLIP)与标签检索模块,在噪声标签环境下仍能实现高效分类,展现了扩散模型在复杂医学场景中的鲁棒性。而动态组合模型(OneNet)的提出,则进一步验证了扩散模型在时序数据生成中的潜力,为动态医学图像(如心脏MRI时间序列)的生成提供了新范式。
生成对抗网络则遵循“生成器-判别器”的对抗博弈框架。生成器通过学习真实数据分布生成样本,判别器则通过区分真实与伪造样本不断优化自身性能。NeurIPS 2023中,脉冲驱动Transformer等新型GAN架构的提出,在降低能耗、提升效率方面取得进展,但其模式崩溃与训练不稳定性的固有缺陷仍待攻克。
技术优势:生成质量与数据效率的权衡
在医学图像生成质量层面,扩散模型展现出显著优势。其生成样本的保真度与多样性在肿瘤检测、疾病诊断等场景中已得到验证。通过引入不确定性指导(如熵与边缘测量),扩散模型在少量样本下即可实现高效生成,且生成过程可控性强,便于结合条件信息(如文本描述、先验知识)进行个性化生成,适用于精准医疗场景。
相比之下,GAN在生成速度与特征提取方面具有优势,其生成速度通常更快,且在特征提取方面表现突出。然而,GAN对大规模数据的依赖性,以及在复杂场景下易出现的模式崩溃问题,限制了其应用范围。扩散模型虽计算成本高、训练复杂,但通过并行计算与高效优化算法,其生成能力正逐步逼近实用门槛。
应用场景:从图像修复到跨模态重建的拓展
在医学图像修复领域,扩散模型凭借逐步去噪的生成机制,可高效修复损坏或有噪声的影像,为临床诊断提供更准确的参考。而GAN在图像增强方面表现突出,但修复损坏图像时易引入伪影,影响诊断准确性。
疾病诊断与治疗领域,扩散模型生成的医学图像可辅助医生决策,提高诊断准确性。GAN在疾病预测与风险评估中具有潜力,但需结合分类器实现端到端诊断,其生成过程隐式、缺乏可解释性,限制了临床应用。
药物研发领域,扩散模型可模拟分子结构,加速新药筛选。而GAN在药物分子生成方面已有应用,但生成分子的有效性需进一步验证。跨模态重建中,扩散模型在CT与MRI、MRI与PET等模态间实现高质量生成,GAN则表现稳定但需解决模态差异导致的特征对齐问题。
挑战与未来方向
扩散模型面临计算成本高、训练复杂等挑战,需开发更高效优化算法、设计合理网络结构,以及利用并行计算技术降低计算成本。GAN则需解决模式崩溃、训练不稳定等问题,开发更稳定的变种并探索有效评估指标,结合其他生成模型优势进行改进。
未来,两种模型的融合发展将成为重要趋势。混合生成模型可结合二者优势,实现更高效、稳定的医学图像生成。同时,跨学科应用将生成模型与医学知识图谱、临床指南等结合,提升生成结果的医学合理性。例如,利用扩散模型的高质量生成能力与GAN的快速生成特性,开发适用于急诊影像快速生成的混合模型,为临床决策提供实时支持。
结语
扩散模型与生成对抗网络在医学图像生成领域各具特色。扩散模型凭借其生成质量与稳定性,在高质量样本生成和跨模态重建方面具有显著优势。而GAN在生成速度和特征学习方面具有优势,但需解决训练不稳定和模式崩溃等问题。未来,结合两者优势,开发更高效、更稳定的生成模型,将是医学图像生成领域的重要研究方向。通过结合两者的优势,开发混合生成模型,以实现更高效、更稳定的医学图像生成,为医疗AI的智能化升级提供有力支持。
参考文献:
- NeurIPS 2023相关论文(如《Label-Retrieval-Augmented Diffusion Models for Learning from Noisy Labels》arXiv:2305.19518
 https://arxiv.org/abs/2305.19518
https://arxiv.org/abs/2305.19518 - Shi, Diwei et al. “Diffusion coefficient orientation distribution function for diffusion magnetic resonance imaging.” Journal of neuroscience methods vol. 348 (2021): 108986. doi:10.1016/j.jneumeth.2020.108986
- Seider, Nicole A et al. “Accuracy and reliability of diffusion imaging models.” NeuroImage vol. 254 (2022): 119138. doi:10.1016/j.neuroimage.2022.119138
- Cheng, Hu, and Vince Calhoun. “Exploring microstructure with diffusion-weighted imaging: From acquisition to modeling.” Journal of neuroscience methods vol. 363 (2021): 109335. doi:10.1016/j.jneumeth.2021.109335
- Li, Feifei et al. “Voxel-Wise Medical Imaging Transformation and Adaption Based on CycleGAN and Score-Based Diffusion.” Studies in health technology and informatics vol. 302 (2023): 1027-1028. doi:10.3233/SHTI230337

















 2788
2788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









