







前言
很久没有读交通预测的论文,突然发现工作后还是要读读最新的论文,关注学术界最新的工作和动向,保持学习。看了几篇22年会议上最新的论文,记录下笔记,因为是泛读的,全文不涉及公式,只描述了论文的大致思想,读论文的顺序大致是:标题=> 摘要=> 模型图 => introduction => 方法 (Methods) => 实验,这样读确实快很多。
1. Event-Aware Multimodal Mobility Nowcasting(AAAI 2022)
解决问题: 时空序列预测,侧重点是对特殊的事件,和学习时间序列中的动态模式

方法:一方面,本文使用多重异构图,提取节点、边的信息;另一方面,本文提出了一个基于内存的预测网络,在时空模型的Encoder和Decoder之间,加上一个内存网络,以存储Encoder的隐变量,在Decoder进行预测的时候,通过设计的attention机制,从内存网络中查找相似的隐藏状态表示输入到Decoder中,为预测增加的位置增加与之相似的上下文信息,从而提升预测效果。
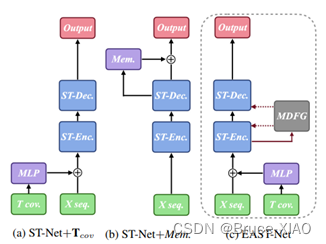
与传统的时空预测模型的结构对比
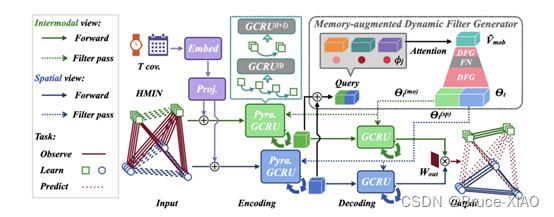
EAST-Net模型
实验中比较有意思的一个点是,模型可以学习到与事件相关的流量预测,下图显示了纽约市6天的流量曲线,可以看到,EAST-Net可以更好地适应周末时的时间序列的动态变化
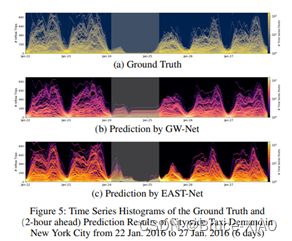
思考:如果能学习到因事件、节假日、极端天气导致的时间序列的陡增和骤减,从一定程度上可以提升整体的预测;一个问题在于,这些模式下的数据样本出现的较少,如何让模型更多地看到这类样本,是一个值的研究的问题。另外,还是要会编故事,Event-Aware, 看上去就比较make sense。
2. Few-Shot Traffic Prediction with Graph Networks using Locale as Relational Inductive Biases(TITS 2022)
解决问题:
本文研究了小数据集下使用轻量级模型来预测时间序列;LOCALEGN可以从上的不同节点学习大型网络,因此可以将其声明为轻量的权重模型,使用很少的训练样本,便中做出准确的短期预测。
文章强调了局部空间模式(locally spatial pattern),和few-shot交通预测任务, 如何理解few-shot? 是指样本少吗?few-shot是指从源领域迁移特征、知识到目标领域。
LocaleGN学习了局部的空间和时间模式,这样极大减少了网络的模型参数;本文使用的是从一个城市转移知识到另外一个城市。
思考:few-shot learning, 交通中的迁移学习是一个值的探索的方向。
3. FOGS: First-Order Gradient Supervision with Learning-based Graph for Traffc Flow Forecasting(IJCAI 2022)
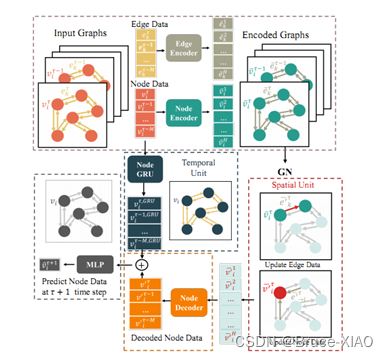
摘要:手工构造的图结构不能准确地提取交通数据中复杂的模式。一方面,本文提出一个基于学习的方法来学习图节点之间的关联;另一方面使用一阶梯度来训练交通流预测模型,有效避免拟合不规则的交通流分布。
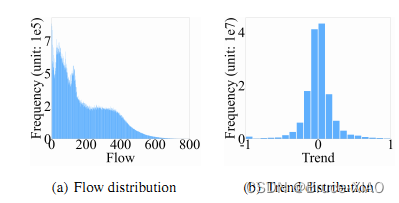
左图,流量分布,右图,相邻时刻的流量变化变化分布。
本文选用了k个时间模式上相似的、和空间相邻的节点;构建了时间序列相似性图,空间相邻图,以此做节点的Embedding.
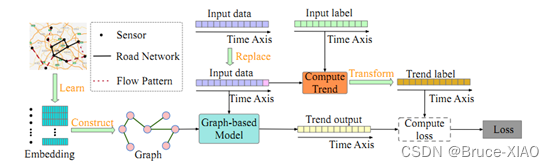
模型结构图
使用k近邻算法学习k个最近的时间维度特征最近的k个邻居,使用node2vec学习节点的embedding; 这不是一个端到端的学习框架?前一部分包含了预训练?
预测趋势(trend)比直接预测流量效果更好,trend服从正态分布,流量数据是偏态的。
4. LEARNING TO REMEMBER PATTERNS: PATTERN MATCHING MEMORY NETWORKS FOR TRAFFIC FORE-CASTING(ICLR 2022)
摘要:交通预测是一个具有挑战性问题,因其复杂的道路网络和由道路事件导致的速度突变。本文将预测问题转化为模式匹配任务。本文提出了一个模式匹配内存网络,学习将输入数据表示为以key-value存储形式的数据。首先通过聚类来提取相似的交通模式,将其作为key, 然后匹配key和输入数据。本文提出了memory网络整合了attention和GCN。PM-MemNet比现有预测模型更加精确。
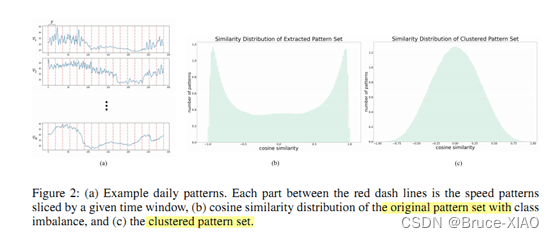
相似交通流模式的提取
下图中,(a)是一天的流量序列,(b)是类别不平衡下的序列余弦相似性,(c)是流量模式聚类后的结果,呈现出正态分布
问题的定义和转换,相比以往的模型直接学习一个函数f来预测未来的多步流量,本文先通过KNN算法提取了每个节点在每个时间步的的相似性流量模式P,再由P预测X
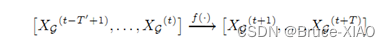
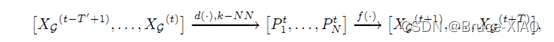
模型结构,包括encoder和decoder两部分,其中重要的组件是GCMem, 由GCN和内存组成的网络,从内存中使用attention机制查询出相似的流量模式,然后使用knn算法选取最近的k个流量模式。
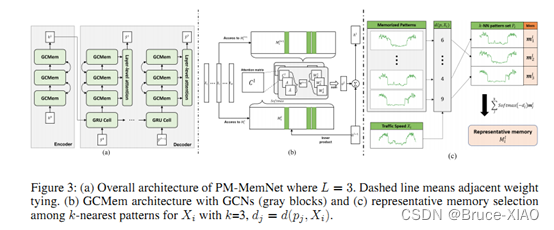
总结:
将交通流缩小至一个更小的模式空间进行表征,然后进行流量预测,相当于缩小了特征的空间,作者在abliation study验证了不同Memory size(模式数量)对实验的影响。
作者在倒数第二段指出了本文的局限:(1)预先将交通流量映射成模式,如果模式冗余则不能起到很好的区分效果,memory-size任然是一个超参数,(2)对于稀有的模式,即极端的流量情况,内存网络可能不能做到较好的泛化(3)使用余弦相似度计算交通流的相似度,并不是最有的选择,应该使用一种可学习的方式学习流量之间的相似性。
5. Pre-training Enhanced Spatial-temporal Graph Neural Network for Multivariate Time Series Forecasting(KDD 2022)
摘要:现有的时空模型大多从短期一小时的历史数据中捕获时间和空间模式,而时间和空间模式的分析需要长期的历史数据,例如超过一小时的。为了解决这个问题,本文提出了一个可扩展的时间序列预训练模型,设计了一个预训练模型从非常长的历史数据学习时间模式,并产生片段级的表示,作为短期时间序列的上下文,输入到STGNN,促进时间序列依赖关系的建模。
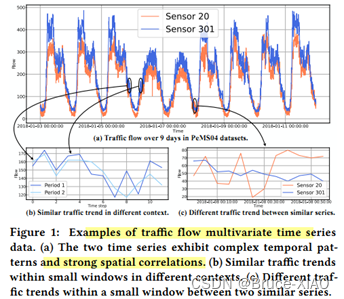
两个传感器时间序列的相似和不相似趋势
模型分为两阶段,第一阶段是预训练阶段,对长的时间序列进行分段,然后输入到Transformer中进行预训练;第二阶段是预测阶段,使用分段的表示作为上下文增强预测模型的准确度。
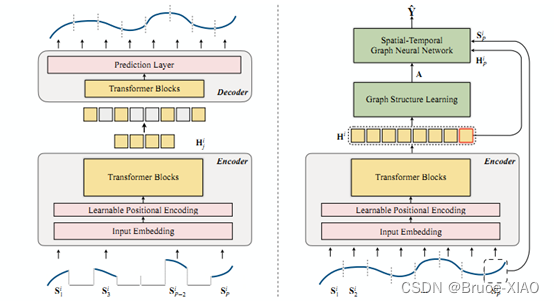
总结:现在的论文都在强调时间模式上的相似性了,使用memory、 预训练等方法都是从历史数据中获取与要待预测的序列的相似的时间序列模式,作为上下文信息,以增加预测阶段的信息量,从而提升预测效果。














 3218
3218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









