







论文:https://arxiv.org/abs/1803.08494
代码:https://github.com/facebookresearch/Detectron/blob/master/projects/GN
0 摘要
Batch Normalization(BN)是深度学习发展过程中的一个里程碑式的技术,被应用到了各种各样的网络的训练过程中。但是,BN是沿着batch维度进行归一化,如果batch的值比较小时,BN的误差会快速增大。在计算机视觉类模型的训练过程中,如分类、检测和分割任务,用到的网络往往比较大,由于机器显存的限制,就需要设置比较小的batch值。本文作者提出了BN的替代版本 — GN。GN是沿着channel维度计算均值和方差。GN的计算和batch size的大小无关。batch size大小为2时,在ImageNet数据集上训练的GN版本的模型比BN版本的模型的错误率低10.6%。当batch size值较大时,GN和BN的一样好。GN在目标检测、分割和视频分类任务上都超过了BN,显示了其强大的普适性。
1 简介
BN是计算一个mini-batch的均值和方差。实验结果表明,BN有助于减小优化难度,加速深度网络的收敛过程。不同batch之间的随机不确定性还起到了一定程度的正则化效果。但是,BN的缺点是需要较大的batch(例如,每个GPU的batch size需要达到32)才能取得好的效果。batch较小时对batch的统计特性的估计准确度会下降,如图1所示,减小batch的值会增大模型的误差。由于显存的限制,BN的这一缺点阻止了人们去训练更大的模型。在batch size值较小时,BN层退化成了近似于线性层,就起不到归一化的效果了。

 GN的示意如图2所示,是按照channel的方向进行分组,然后对各组内的数据进行归一化处理,因此GN与batch的大小无关(如图1所示)。batch size较小的时候,GN优于BN,batch size较大时,GN和BN几乎一样好。在RNN/LSTM和GAN网络训练过程中会用到LN和IN(图2所示),但把它们用到视觉任务时往往效果不理想。但是GN可以在视觉任务中取得较好的效果,同时也可以用于RNN/LSTM和GAN的训练中取得较好的效果。
GN的示意如图2所示,是按照channel的方向进行分组,然后对各组内的数据进行归一化处理,因此GN与batch的大小无关(如图1所示)。batch size较小的时候,GN优于BN,batch size较大时,GN和BN几乎一样好。在RNN/LSTM和GAN网络训练过程中会用到LN和IN(图2所示),但把它们用到视觉任务时往往效果不理想。但是GN可以在视觉任务中取得较好的效果,同时也可以用于RNN/LSTM和GAN的训练中取得较好的效果。
3 GN
各通道的视觉特征并非完全意义上相互独立。传统的手工设计特征,如SIFT、HOG和GIST,是手工设计的各通道相互独立的特征,这些特征往往按通道进行归一化处理。高层特征,如VLAD和FV也是按通道区分的特征,一组特征可以认为是一组子向量的集合。
不能把深度网络学习到的特征认为是非结构化的特征。例如,CNN中第一个卷积层的特征,conv1,对输入图像使用一个卷积核及其水平翻转后的卷积核,大概率是可以得到类似分布的输出特征。这些具有一定关联关系的通道是可以归一化到一起的。
3.1 公式
BN、LN、IN和GN,都是进行了类似的计算:
x
^
i
=
1
σ
i
(
x
i
−
u
i
)
(1)
\hat x_i = \frac{1}{\sigma_i}(x_i - u_i) \tag{1}
x^i=σi1(xi−ui)(1)
x
x
x表示某层输出的特征,
i
i
i表示位置索引。输入是2D图像时,
i
=
(
i
N
,
i
C
,
i
H
,
i
W
)
i = (i_N,i_C,i_H,i_W)
i=(iN,iC,iH,iW)是以(N,C,H,W)顺序表示的四维索引。
u i = 1 m ∑ k ∈ S i x k , σ i = 1 m ∑ k ∈ S i ( x k − u i ) 2 + ϵ (2) u_i = \frac{1}{m}\sum_{k \in S_i}x_k,\sigma_i = \sqrt{\frac{1}{m}\sum_{k \in S_i}(x_k - u_i)^2 + \epsilon} \tag{2} ui=m1k∈Si∑xk,σi=m1k∈Si∑(xk−ui)2+ϵ(2)
S i S_i Si表示要进行归一化处理的像素集合。不同的归一化算法的区别也就是 S i S_i Si的不同。
BN:
S
i
=
{
k
∣
k
C
=
i
C
}
(3)
S_i = \{k | k_C = i_C\} \tag{3}
Si={k∣kC=iC}(3)
即,对同一个通道的像素进行归一化处理。
LN:
S
i
=
{
k
∣
k
N
=
i
N
}
(4)
S_i = \{k|k_N=i_N\} \tag{4}
Si={k∣kN=iN}(4)
即,对用一个样本的像素进行归一化处理,和batch size的大小无关。
IN:
S
i
=
{
k
∣
k
N
=
i
N
,
k
C
=
i
C
}
(5)
S_i = \{k|k_N=i_N,k_C = i_C\} \tag{5}
Si={k∣kN=iN,kC=iC}(5)
即,对同一样本的同一通道的像素进行归一化处理,和batch size的大小无关。
BN,LN和IN都学习了一组参数
(
γ
,
β
)
(\gamma,\beta)
(γ,β)来补偿归一化造成的表示能力的减弱。
y
i
=
γ
x
i
^
+
β
(6)
y_i = \gamma \hat{x_i} + \beta \tag{6}
yi=γxi^+β(6)
Group Normalization:
GN用于计算均值和方差的像素集合
S
i
S_i
Si为:
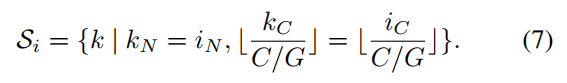
G表示组数,是预先定义的超参数。GN的含义就是对同一个样本的各通道进行分组 ,然后对各组的像素进行归一化处理。GN也是对各个通道学习一组
γ
\gamma
γ和
β
\beta
β。
GN和LN、IN的关系:
如果设置G=1,那么GN就变成了LN。LN认为某层中的各通道具有相似的分布,对于卷积层来说,这个假设不是特别成立。GN的限制比LN要弱,只是认为一组通道具有相似的分布,不同组之间依然可以去学习不同的分布。如图4所示,GN比LN有更强的泛化能力。
如果设置G=C,则GN变为IN。IN只考虑了空间信息去计算均值和方差,并没有考虑通道之间的依赖关系。
tf实现Group Norm:
 pytorch实现了group norm函数,为torch.nn.GroupNorm2d();更多信息可以参考:https://blog.csdn.net/shanglianlm/article/details/85075706
pytorch实现了group norm函数,为torch.nn.GroupNorm2d();更多信息可以参考:https://blog.csdn.net/shanglianlm/article/details/85075706
4 实验
4.1 ImageNet分类实验
batch size较大时:


batch size比较大时,BN效果较好。但在训练集上GN优于BN,表明GN比BN更易于优化,GN在验证集上的效果略差于BN,表明GN的泛化能力略差于BN。这是因为BN中的随机组批操作引入了一定的不确定性,增强了泛化能力,而LN、IN和GN都没有这样的操作,因此也损失了一定的泛化能力。
batch size较小时:

 对于BN来说,当batch size减小时,学习率也跟随调整。batch size为32时,学习率为0.1,如果batch size为N,则学习率调整为0.1N/32.
对于BN来说,当batch size减小时,学习率也跟随调整。batch size为32时,学习率为0.1,如果batch size为N,则学习率调整为0.1N/32.
实验结果表明,随着batch size的减小,BN的分类误差在增加,而GN的误差则很稳定。这表明随着batch的减小,batch的均值和方差的不确定性在增加。GN在batch size减小的时候依然可以取得良好的效果,这样就可以在内存/显存受限的情况下去尝试更大的模型。
对比batch renorm:
batch renorm是对BN计算的均值和方差进行限制,上限值设置为
γ
m
a
x
\gamma_{max}
γmax和
d
m
a
x
d_{max}
dmax。对ResNet-50,设置
γ
m
a
x
=
1.5
\gamma_{max} = 1.5
γmax=1.5和
d
m
a
x
=
0.5
d_{max} = 0.5
dmax=0.5。当batch size为4时,使用ResNet50模型,BN的错误率为27.3%,BR的错误率为26.3%,GN的错误率为24.2%。
不同分组方式:
按照固定的组数分组:组数大于1时的分类效果比组数等于1(LN)的时候更好。
按照固定的channel数分组:按照固定的channel数分组时,效果也比各通道一个组(IN)更好。

4.2 COCO的目标检测和分割

表4的第一行和第二行对比,使用Mask R-CNN时,可以发现GN比BN的效果更好。
对于FPN,使用GN替换BN,也可以取得更好的检测和分割效果。这里作者使用了4conv1fc替换2个全连接头,可以取得更好的效果。
5 总结
作者提出了GN,一种新的按照通道分组归一化的方法。该方法和batch size的大小无关。在不同类型的应用场景下,都显示了GN的有效性。然而,作者发现,由于前期BN的广泛应用,目前广泛应用的很多网络的超参数都是针对BN进行设计的,但是这些超参数并不适用于GN。重新设计新的网络结构或者使用新的超参数可能会取得更好的效果。
作者还建议可以在RNN/LSTM、GAN及增强学习中尝试使用GN。














 548
548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









