







论文:https://arxiv.org/abs/2005.12872
代码:https://github.com/facebookresearch/detr
0 摘要
作者提出了一种新的目标检测算法,把目标检测问题当做set预测问题进行处理。简化了传统的使用CNN进行目标检测的处理过程,移除了NMS后处理过程和anchor提供的先验知识。算法的核心部分叫做DETR,使用Transformer(Encoder + Decoder)实现目标类别和位置的预测。在COCO数据集上的目标检测效果和效率与高度优化的Faster R-CNN相近。DETR也适用于目标分割并取得了较好的效果。
1 简介
目标检测的目的是预测多个感兴趣目标的类别和位置信息。基于CNN的检测算法都使用了间接的方式,在一系列预定义/预测的proposal、anchor或window上进行目标类别的预测和位置的回归,并且需要后处理过程消除重复的预测框。但是本文提出的DETR是端到端的,借鉴了机器翻译和语音识别这些复杂的结构化预测任务中端到端训练取得了良好性能提升的启发。前面的一些使用端到端进行目标预测的工作要么加了很多的先验信息,要么结果竞争力不足。本文尝试弥补这些差距。
作者把目标检测看做是set预测的问题,那么目标检测问题也就变成了一个seq2seq的问题,所以作者使用了Transformer结构,称之为DETR。完整的处理流程如下图所示。
 主要包含下述过程:
主要包含下述过程:
- 使用CNN提取图像的feature map;
- feature map经过reshape操作后送入Transformer,本文使用的decoder为NAT类型,可以一次性得到所有的输出;
- 训练时,对decoder的输出和ground-truth进行匈牙利匹配,计算训练损失。损失反向传播,迫使模型对每个类别使用固定的decoder的Positional Encoding进行表示,也就是让每个框针对指定的类别进行学习;
- 预测时,每个图像得到指定数量的预测框,每个框代表了特定的类别,根据其概率判定是否有该类型目标,根据预测的位置得到目标的位置。
作者在COCO数据集上对比了DETR和Faster R-CNN的检测结果。Faster R-CNN经过多次迭代优化后,其效果已远远超过初始论文。实验结果表明两者取得了相近的性能。更具体的说,DETR因为使用了Transformer,捕获了全局的信息,对大目标取得了更好的检测效果。但是对于小目标,检测效果就要差一些,期望未来可以像使用FPN提升Faster R-CNN那样使用FPN提升DETR对于小目标的检测效果。
DETR泛化应用能力也较好,实验表明预训练的检测DETR + 分割head就可以取得良好的目标分割的效果。
2 相关工作
2.1 set预测
没有典型能用于set预测的深度学习模型。最相近的set预测任务是多标签分类,但其基本方法one-vs-rest也不适用于目标检测任务,因为目标检测任务会预测多个几乎相同的框。目标检测任务的第一个难点是避免重复预测,一般使用NMS后处理进行解决,但是set预测问题中是不进行后处理的,set预测问题一般都使用全局元素间的交互度判断解决冗余。对于固定数量的set预测问题,全连接网络可以解决但是计算量太大,不实用。一般的方法是如RNN所示的那样使用auto-regressive序列模型,至于损失值一般都是使用匈牙利匹配算法得到的预测值和ground-truth之间的最佳匹配来计算得到。本文作者使用了NAT算法,可以一次性得到decoder的结果,从而可以并行解码。
2.2 Transformer和并行解码
Transformer中使用了self-attention模块,后者可以计算输入的不同单元之间的关联程度,从而获取全局的关联关系。其相比RNN内存占用较小且可以捕获全局信息,因此适用于长输入数据的处理。Transformer在NLP、语音处理和CV领域已经广泛取代了RNN。
但是auto-regressive的Transformer是一个一个的预测输出,因此推理时间和输出的长度成正比且难以并行化处理。本文使用了Non auto-regressive,可以一次性得到所有的decoder结果,很容易用到需要并行化处理的场景,可以提升处理效率。
2.3 目标检测
基于CNN的目标检测深度依赖于先验知识,Two-stage的目标检测器依赖于预测proposal,One-Stage目标检测器则依赖于预定义的anchor或目标中心点位置。最近有工作证明预定于的先验知识的好坏直接决定了最终的检测效果。本文作者提出的DETR不依赖于先验知识,且去掉了后处理过程,直接输入图像输出预测框,实现了端到端的检测。
3 DETR核心思想
3.1 结构

3.1.1 Backbone
Backbone使用CNN实现,作用是将输入图像映射为feature map。
使用数学公式表示为: x ∈ R 3 × H 0 × W 0 ⇒ f ∈ R C × H × W x \in R^{3 \times H_0 \times W_0} \Rightarrow f \in R^{C \times H \times W} x∈R3×H0×W0⇒f∈RC×H×W,最常用的参数是 C = 2048 , W = W 0 / 32 , H = H 0 / 32 C = 2048,W = W_0 / 32,H = H_0 / 32 C=2048,W=W0/32,H=H0/32。
代码中使用的是ResNet50模型,参数如上段所述。layer1不参与训练过程,layer2,layer3,layer4均按照学习率1e-5参与训练过程,最终返回layer4的输出。
class BackboneBase(nn.Module):
def __init__(self, backbone: nn.Module, train_backbone: bool, num_channels: int, return_interm_layers: bool):
super().__init__()
for name, parameter in backbone.named_parameters():
if not train_backbone or 'layer2' not in name and 'layer3' not in name and 'layer4' not in name:
parameter.requires_grad_(False)
if return_interm_layers:
return_layers = {"layer1": "0", "layer2": "1", "layer3": "2", "layer4": "3"}
else:
return_layers = {'layer4': "0"}
self.body = IntermediateLayerGetter(backbone, return_layers=return_layers)
self.num_channels = num_channels
def forward(self, tensor_list: NestedTensor):
xs = self.body(tensor_list.tensors)
out: Dict[str, NestedTensor] = {}
for name, x in xs.items():
m = tensor_list.mask
assert m is not None
mask = F.interpolate(m[None].float(), size=x.shape[-2:]).to(torch.bool)[0]
out[name] = NestedTensor(x, mask)
return out
class Backbone(BackboneBase):
"""ResNet backbone with frozen BatchNorm."""
def __init__(self, name: str,
train_backbone: bool,
return_interm_layers: bool,
dilation: bool):
backbone = getattr(torchvision.models, name)(
replace_stride_with_dilation=[False, False, dilation],
pretrained=is_main_process(), norm_layer=FrozenBatchNorm2d)
num_channels = 512 if name in ('resnet18', 'resnet34') else 2048
super().__init__(backbone, train_backbone, num_channels, return_interm_layers)
3.1.2 Transformer
具体的Transformer结构如下图所示:

3.1.2.1 Encoder
和原始的Transformer一样,Encoder也是由多个重复块组成,每个块含有一个multi-head self-attention + 一个 FFN组成。
对输入数据的处理过程为:
- 首先使用 1 × 1 1 \times 1 1×1卷积层减少 f f f的channel数,比如从C减小为d,得到新的feature map z 0 ∈ R d × H × W z_0 \in R^{d \times H \times W} z0∈Rd×H×W;
- 对 z 0 z_0 z0进行reshape,输出为 R d × H W R^{d \times HW} Rd×HW,因为encoder期望二维的输入;
- 对 z 0 z_0 z0叠加Positional Encoding,注意Positional Encoding不是和原始Transformer一样只添加到第一个基础块,而是添加到了每一个基础块中;
- 输入送入Encoder进行编码。
Encoder中使用二维的Positional Encoding:
原版Transformer中的位置编码使用的是sinecosine,公式为:
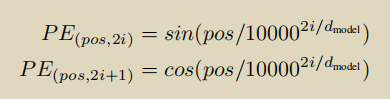
上式中的pos表示输入的绝对位置,即token在sequence中的位置,例如第一个token “我” 的 pos = 0;i表示向量的索引位置,即Positional Encoding的维度,取值范围为[0,
d
m
o
d
e
l
/
2
d_{model}/2
dmodel/2);
d
m
o
d
e
l
d_{model}
dmodel为向量总体长度。可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码。
本文中作者仍然使用sinecosine编码,计算公式和上面的完全一致。但是不同点在于作者将一维编码变成了二维编码。上式中,pos为一个维度上的位置,每个pos位置都被编码成了长度为
d
m
o
d
e
l
d_{model}
dmodel的向量。本文中作者考虑了两个维度上的位置,更加符合图像的特征,即将x,y两个方向上分别编码成长度为
d
m
o
d
e
l
/
2
d_{model}/2
dmodel/2的向量,将两者concat之后得到总体的编码向量。在每一个方向编码时,仍然是偶数位置采用sine函数,奇数位置采用cosine函数。总体计算编码公式为:
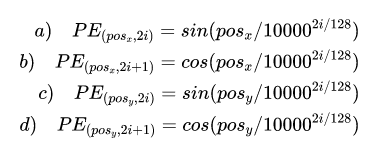
即x方向上每个位置都编码为长度为
d
m
o
d
e
l
/
2
d_{model}/2
dmodel/2的向量,y方向上的每个位置也都编码成长度为
d
m
o
d
e
l
/
2
d_{model}/2
dmodel/2的向量。各个方向上如果位置索引为偶数,采用sine函数;如果位置索引为奇数,采用cosine函数。对位置
(
p
o
s
x
,
p
o
s
y
)
(pos_x,pos_y)
(posx,posy),两个
d
m
o
d
e
l
/
2
d_{model}/2
dmodel/2的向量拼接得到长度为
d
m
o
d
e
l
d_{model}
dmodel的向量,表示该点的位置编码。在代码中,设置
d
m
o
d
e
l
=
256
d_{model} = 256
dmodel=256。
class PositionEmbeddingSine(nn.Module):
"""
This is a more standard version of the position embedding, very similar to the one
used by the Attention is all you need paper, generalized to work on images.
"""
def __init__(self, num_pos_feats=64, temperature=10000, normalize=False, scale=None):
super().__init__()
self.num_pos_feats = num_pos_feats
self.temperature = temperature
self.normalize = normalize
if scale is not None and normalize is False:
raise ValueError("normalize should be True if scale is passed")
if scale is None:
scale = 2 * math.pi
self.scale = scale
def forward(self, tensor_list: NestedTensor):
x = tensor_list.tensors
mask = tensor_list.mask
assert mask is not None
not_mask = ~mask
y_embed = not_mask.cumsum(1, dtype=torch.float32)
x_embed = not_mask.cumsum(2, dtype=torch.float32)
if self.normalize:
eps = 1e-6
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)
pos_x = x_embed[:, :, :, None] / dim_t
pos_y = y_embed[:, :, :, None] / dim_t
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
return pos
数据处理过程:

最右侧的输出送入encoder层启动编码。
Encoder层的计算过程:
- 执行self-attention操作:如上图Fig. 10所示,以
Image feature + Positional Embedding的和作为k和q,以Image feature作为v,进行self-attention计算; - Add + Layer Norm;
- FFN;
- Add + Layer Norm;
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(src, pos)
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
def forward_pre(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
src2 = self.norm1(src)
q = k = self.with_pos_embed(src2, pos)
src2 = self.self_attn(q, k, value=src2, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src2 = self.norm2(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src2))))
src = src + self.dropout2(src2)
return src
def forward(self, src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(src, src_mask, src_key_padding_mask, pos)
return self.forward_post(src, src_mask, src_key_padding_mask, pos)
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers, norm=None):
super().__init__()
self.layers = _get_clones(encoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
def forward(self, src,
mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
output = src
for layer in self.layers:
output = layer(output, src_mask=mask,
src_key_padding_mask=src_key_padding_mask, pos=pos)
if self.norm is not None:
output = self.norm(output)
return output
3.1.2.2 Decoder
和原始的Transformer一样,Decoder也是由多个重复块组成,每个块含有两个multi-head self-attention + 一个 FFN组成。
Decoder部分的特殊设计有:
- Decoder使用的是Non auto-regressive方法,一次性可以得到所有的输出而不是每次只得到一个输出;
- Decoder的Positional Encoding也是输入到每一个基础块中而不仅是第一个块;
- Decoder的Positional Encoding称之为object queries,其是训练得到的且数量和每个图像要预测的框的数量一致,表示为N,物理含义是每个Positional Encoding负责一个框的类别和位置的预测;
object queries:
object queries输入到decoder中,类型为nn.Embedding,表示其是可以学习的。大小为
(
N
,
d
m
o
d
e
l
)
(N,d_{model})
(N,dmodel)。
decoder 层的计算过程:
- 输入:输入形状和object query一致,如果是第一个decoder block,则为全0 tensor,否则为上一层的输出;
- 第一个self-attention层:q和k使用
输入 + object queries,v使用输入。因为要计算q和k之间的attention,所以可以看成是计算Object queries矩阵内部通过学习建模了N个物体之间的全局关系,例如房间里面的桌子旁边(A类)一般是放椅子(B类),而不会是放一头大象(C类),那么在推理时候就可以利用该全局注意力更好的进行解码预测输出; - Add + Layer Norm;
- 第二个self-attention层:q使用
第一个self-attent层的输出 + object queries,k使用encoder的输出 + encoder使用的位置编码,v使用的是encoder的输出; - Add + Layer Norm;
- FFN;
- Add + Layer Norm;
class TransformerDecoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(tgt, query_pos)
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
def forward_pre(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
tgt2 = self.norm1(tgt)
q = k = self.with_pos_embed(tgt2, query_pos)
tgt2 = self.self_attn(q, k, value=tgt2, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt2 = self.norm2(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt2, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt2 = self.norm3(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2))))
tgt = tgt + self.dropout3(tgt2)
return tgt
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
return self.forward_post(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
class TransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers, norm=None, return_intermediate=False):
super().__init__()
self.layers = _get_clones(decoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
self.return_intermediate = return_intermediate
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
output = tgt
intermediate = []
for layer in self.layers:
output = layer(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask,
pos=pos, query_pos=query_pos)
if self.return_intermediate:
intermediate.append(self.norm(output))
if self.norm is not None:
output = self.norm(output)
if self.return_intermediate:
intermediate.pop()
intermediate.append(output)
if self.return_intermediate:
return torch.stack(intermediate)
return output.unsqueeze(0)
3.1.3 FFN
FFN组成为:
- 3层线性变换 + ReLU,得到目标的位置,用归一化的目标中心点坐标和框的宽高组成;
- 单个线性层,输出搭配softmax函数得到目标的类别概率;
FFN的输出数量固定为N,N设置为要比一副图像中通常存在的目标数量更大,使用一个特殊的label ϕ \phi ϕ表示没有目标,也就是背景类。
3.2 损失函数
DETR对每张输入图像一次性推理出N个bounding box,N设置为要比一副图像中通常存在的目标数量更大。训练时最大的难点是衡量预测目标(class,position,size)和ground-truth之间的损失。
3.2.1 ground-truth和预测框指派
对一张训练图像,使用
y
y
y表示ground-truth,
y
^
=
{
y
i
^
}
i
=
1
N
\hat y= \{\hat{y_i}\}_{i=1}^N
y^={yi^}i=1N表示N个预测框。因为N比真实的目标数量要多,因此对
y
y
y添加用
ϕ
\phi
ϕ表示的空集以使得其数量同样为N。那么对于N个预测结果和N个ground-truth之间的最优化指派问题可以表示为:
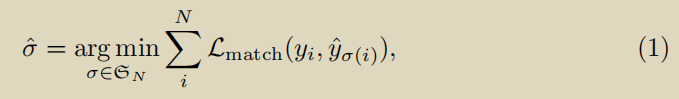
L
m
a
t
c
h
(
y
i
,
y
^
σ
(
i
)
)
L_{match}(y_i,\hat{y}_{{\sigma(i)}})
Lmatch(yi,y^σ(i))表示ground-truth
y
i
y_i
yi和索引为
σ
(
i
)
\sigma(i)
σ(i)的预测框的匹配损失。具体的指派过程使用了匈牙利算法。
匹配损失需要考虑 预测类别的准确率 + 预测框和真实框的相似度。对于第i个ground-truth box,可以表示成 y i = ( c i , b i ) y_i=(c_i,b_i) yi=(ci,bi), c i c_i ci表示类别(可能为 ϕ \phi ϕ), b i ∈ [ 0 , 1 ] 4 b_i \in [0,1]^4 bi∈[0,1]4表示框的归一化的中心点坐标和宽高。对索引为 σ ( i ) \sigma(i) σ(i)的预测框,其类别为 c i c_i ci的概率为 p ^ σ ( i ) ( c i ) \hat{p}_{\sigma(i)}(c_i) p^σ(i)(ci),预测框可以表示为 b ^ σ ( i ) \hat{b}_{\sigma(i)} b^σ(i)。
总的 L m a t c h ( y i , y ^ σ ( i ) ) = − 1 { c i ≠ ϕ } p ^ σ ( i ) ( c i ) + 1 { c i ≠ ϕ } L b o x ( b i , b ^ σ ( i ) ) L_{match}(y_i,\hat{y}_{{\sigma(i)}}) = -1_{\{c_i \neq \phi\}}\hat{p}_{\sigma(i)}(c_i)+1_{\{c_i \neq \phi\}}L_{box}(b_i,\hat{b}_{\sigma(i)}) Lmatch(yi,y^σ(i))=−1{ci=ϕ}p^σ(i)(ci)+1{ci=ϕ}Lbox(bi,b^σ(i))。基于 L m a t c h L_{match} Lmatch应用匈牙利匹配算法可以得到预测框和ground-truth之间的最佳匹配。对于 c i = ϕ c_i = \phi ci=ϕ的ground-truth box,其类别损失和 p ^ σ ( i ) ( c i ) \hat{p}_{\sigma(i)}(c_i) p^σ(i)(ci)无关,而是定义为一个常量。之所以对 c i ≠ ϕ c_i \neq \phi ci=ϕ的ground-truth box,其类别损失定义成 − p ^ σ ( i ) ( c i ) -\hat{p}_{\sigma(i)}(c_i) −p^σ(i)(ci),也是作者实验发现这样有更好的效果。
3.2.2 训练损失函数
预测框和ground-truth匹配的过程和CNN目标检测模型中anchor/proposal与ground-truth的匹配过程是一样的,唯一的区别在于预测框和ground-truth的数量都是N,因此不存在重复匹配,只允许一对一的匹配。
根据上面公式(1)计算得到的预测框和ground-truth之间的最佳匹配关系,可以计算损失值为:
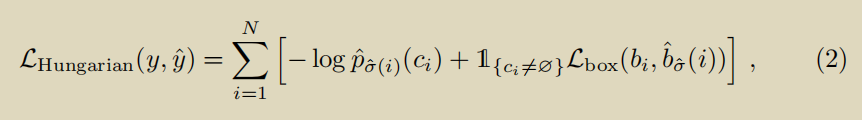
- 分类损失:使用的是负对数似然值;但是由于N个ground-truth box中可能大部分都是补充的空label,即 c i = ϕ c_i = \phi ci=ϕ,为了保证正负样本的均衡,对和 c i = ϕ c_i = \phi ci=ϕ的ground-truth box匹配的预测框的类别损失 − log p ^ σ ( i ) ( c i ) -\text{log}\hat{p}_{\sigma(i)}(c_i) −logp^σ(i)(ci)要额外除以10,这种做法和Faster R-CNN中也是一致的;
- Bounding box损失: L b o x ( b i , b ^ σ ( i ) ) = λ i o u L i o u ( b i , b ^ σ ( i ) ) + λ L 1 ∣ ∣ b i − b ^ σ ( i ) ∣ ∣ 1 L_{box}(b_i,\hat{b}_{\sigma(i)})=\lambda_{iou}L_{iou}(b_i,\hat{b}_{\sigma(i)})+\lambda_{L1}||b_i - \hat{b}_{\sigma(i)}||_1 Lbox(bi,b^σ(i))=λiouLiou(bi,b^σ(i))+λL1∣∣bi−b^σ(i)∣∣1, λ i o u \lambda_{iou} λiou和 λ L 1 \lambda_{L1} λL1是两个超参数。 L i o u L_{iou} Liou使用的是GIOU损失。
3.2.3 额外的decoding损失
decoder共包含了6个decoder layer,每一层都输出了目标的位置和类别信息。每个decoder layer的输出都和ground-truth一起进行了损失的计算。
3.3 总体含义
DETR是怎么训练的?
训练集里面的任何一张图片,假设第1张图片,我们通过模型产生100个预测框
,假设这张图片有只3个GT box ,它们分别是Car,Dog,Horse。
问题是:我怎么知道这100个预测框哪个是对应Car,哪个是对应Dog,哪个是对应Horse?
我们建立一个(100,3)的矩阵,矩阵里面的元素就是
L
m
a
t
c
h
L_{match}
Lmatch的计算结果,举个例子:比如左上角的(1,1)号元素的含义是:第1个预测框对应Car的情况下的
L
m
a
t
c
h
L_{match}
Lmatch值。我们用scipy.optimize这个库中的 linear_sum_assignment函数找到最优的匹配,这个过程我们称之为:“匈牙利算法 (Hungarian Algorithm)”。
假设linear_sum_assignment做完以后的结果是:第23个预测框对应Car,第44个预测框对应Dog,第95个预测框对应Horse。
现在把第23,44,95个预测框挑出来,按照 L H u n g a r i a n L_{Hungarian} LHungarian计算Loss,得到这个图片的Loss。
把所有的图片按照这个模式去训练模型。
训练完以后怎么用?
训练完以后,你的模型学习到了一种能力,即:模型产生的100个预测框,它知道某个预测框该对应什么目标
,比如,模型学习到:第1个预测框对应Car,第2个预测框对应Bus,第3个预测框对应Sky,第4个预测框对应Dog,第5个预测框对应Horse,第6-100个预测框对应
ϕ
\phi
ϕ,等等。
以上只是我举的一个例子,意思是说:模型知道了自己的100个预测框每个该做什么事情,即:每个框该预测什么样的目标。
为什么训练完以后,模型学习到了一种能力,即:模型产生的100个预测框,它知道某个预测框该对应什么目标?
还记得前面说的Object queries吗?它是一个维度为(100,b,256)维的张量,初始时元素全为0。实现方式是nn.Embedding(num_queries, hidden_dim这里num_queries=100,hidden_dim=256,它是可训练的。这里的b指的是batch size,我们考虑单张图片,所以假设Object queries是一个维度为(100,256)维的张量。我们训练完模型以后,这个张量已经训练完了,那此时的Object queries究竟代表什么?
我们把此时的Object queries看成100个格子,每个格子是个256维的向量。训练完以后,这100个格子里面注入了不同目标的位置信息和类别信息。比如第1个格子里面的这个256维的向量代表着Car这种目标的位置信息,这种信息是通过训练,考虑了所有图片的某个位置附近的Car编码特征,属于和位置有关的全局Car统计信息。
测试时,假设图片中有Car,Dog,Horse三种物体,该图片会输入到编码器中进行特征编码,假设特征没有丢失,Decoder的Key和Value就是编码器输出的编码向量(如图30所示),而Query就是Object queries,就是我们的100个格子。
Query可以视作代表不同目标的信息,而Key和Value可以视作代表图像的全局信息。
现在通过注意力模块将Query和Key计算,然后加权Value得到解码器输出。对于第1个格子的Query会和Key中的所有向量进行计算,目的是查找某个位置附近有没有Car,如果有那么该特征就会加权输出,对于第3个格子的Query会和Key中的所有向量进行计算,目的是查找某个位置附近有没有Sky,很遗憾,这个没有,所以输出的信息里面没有Sky。
整个过程计算完成后就可以把编码向量中的Car,Dog,Horse的编码嵌入信息提取出来,然后后面接FFN进行分类和回归就比较容易,因为特征已经对齐了。
发现了吗?Object queries在训练过程中对于N个格子会压缩入对应的和位置和类别相关的统计信息,在测试阶段就可以利用该Query去和某个图像的编码特征Key,Value计算,若图片中刚好有Query想找的特征,比如Car,则这个特征就能提取出来,最后通过2个FFN进行分类和回归。所以前面才会说Object queries作用非常类似Faster R-CNN中的anchor,这个anchor是可学习的,由于维度比较高,故可以表征的东西丰富,当然维度越高,训练时长就会越长。
这就是DETR的End-to-End的原理,可以简单归结为上面的几段话,你读懂了上面的话,也就明白了DETR以及End-to-End的Detection模型原理。
4 实验
4.1 对比Faster R-CNN
 DETR和Faster R-CNN的效果相当,但是DETR对大目标的检测效果要好于Faster R-CNN,对小目标的检测效果则不如Faster R-CNN。
DETR和Faster R-CNN的效果相当,但是DETR对大目标的检测效果要好于Faster R-CNN,对小目标的检测效果则不如Faster R-CNN。
4.2 消融研究
4.2.1 encoder的层数
 encoder的层数越多越好。
encoder的层数越多越好。
 最后一个encoder的self-attention的输出,可以看出已经有能力区分出不同的目标。
最后一个encoder的self-attention的输出,可以看出已经有能力区分出不同的目标。
4.2.2 decoder的层数

decoder也是层数越多越好,但是要注意对于decoder而言,前面的层应用NMS可以提升效果,后面的层应用NMS的效果则比较小。
 decoder的注意力可以看出其更加关注目标的细节信息,作者猜测这是因为encoder已经关注到了目标的全局信息,decoder关注信息信息更加有助于进行正确的检测。
decoder的注意力可以看出其更加关注目标的细节信息,作者猜测这是因为encoder已经关注到了目标的全局信息,decoder关注信息信息更加有助于进行正确的检测。
4.2.3 不同位置编码的影响

4.2.4 不同损失的影响
















 1009
1009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









