







《深入浅出 Hibernate》 台湾知名专家夏昕主编,读大学的时候读过这本书,但那是没有Hibernate开发经验,所以也只是知道些皮毛。工作以后在项目中用到这个开源框架,今天再次得到这本电子书,从头到位一口气读了一遍,发现句句真理。故,把一些高级特性记录下来。
Hibernate 优点:不需要写jdbc ,直接操作对象,适合操作简单对象的增删改查。缺点:不适合操作大量数据,不适合数据优化。
方言(dialect):hql 面对的是对象模型,通过方言可以把hql翻译成特定数据库的sql语句。
一 Session
Configuration config=new Configuration().configure("myHibernate.cfg.xml");
SessionFactory sessionFactory=config.buildSessionFactory();
Session session=sessionFactory.openSession();
注意:session设计是非线程安全的,一个session只能由一个线程使用.里面封装了一些持久化的方法:
find、save、update、delete、
查询提供两种方法:(1)、HQL
eg: String HQL="from Tuser user where user.name like ?";
Query query=session.createQuery(HQL);
query.setParameter(0,"chen");
(2)、面向对象查询的
eg: Criteria criteria= session.createCriteria(Tuser.class)
criteria.add(Expression.eq("name","chen"))
二 实体对象生命周期
transient(自由态,实体对象在内存中自由存在,它与数据库的记录无关)
persistent(持久态,实体对象已经纳入了Hibernate框架所管理的状态,一个对象对应一个数据库中的记录,当事务提交以后,Hibernian在清理缓存(脏数据)的时候会和数据库同步)
持久态的对象不需要显示的调用object.save(),只要事务提交就可以保存到数据库
public saveUser(){
Session session = null;
Tuser user = null;
Transaction ts = null;
try {
session = super.getSession()
ts = session.getTransaction();
ts.beginTransaction();
//transient 对象
user = new Tuser();
user.setName("张三");
user.setPassWord("123");
//persistent 对象
session.save(user);
//在此次 user.getId(); 会得到一个id值,后台会打印一条插入的sql语句
user.setName("王五"); //此处对象的name 改变,在后台会打印一条update语句
ts.commit();//事务提交,正式插入数据库
} catch(Exception ex) {
ts.rollback();
} finally{
session.close();
}
//detached 对象
user.setName("李四");
try {
session = super.getSession();
ts = session.getTransaction();
ts.beginTransaction();
session.update(user);//此时的detached 对象又为persistent对象,后台打印一条update语句
ts.commit();//事务提交,正式插入数据库
} catch(Exception ex) {
ts.rollback();
} finally{
session.close();
}
}//end saveUser()
Detached(游离态 处于Persisent状态的对象,其对应的session实例关闭后就处于游离状态)
session 是persistent对象的宿主,宿主消失了,则persistent对象立即转入Detached状态。
detached 显著特征:在数据库中有对应的记录(id) ,只是没有纳入session管理。detached对象一定是经过detached 到persistent 到detached的转换
Detached和transient的区别是:Detached状态的对象还可以关联到另一个session中去,而成为persistent对象.
是因为虽然脱离了曾经是persistent状态的对象已经和数据库中的一条记录有关系了(id 主键唯一性)。所以Detached状态的对象再次加入Hibernate管理时其状态又转换为Persistent状态了。当调用session.delete()方法是这个对象在数据库中被删除,即这个id不存在所以这个对象又为Transient状态。
detached和transient状态的对象统称为VO(value object).
Persistent状态的对象称之为PO(Persistent object) PO是加入了Hibernate实体容器管理中的,PO变化是反映到实际的数据库中去的。
状态转换图:
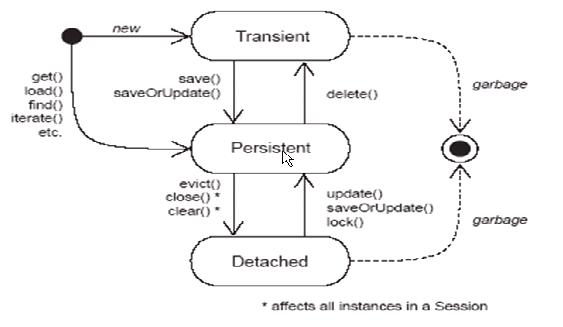
在数据加载中,
Tuser user = (Tuser)get(Tuser.class,id)//注意这个id 是实现了序列化的id ,比如String Intger Long类型的.只要执行到这里后台就会发sql语句,进行查询。如果查找一个没有的记录,则user 为null
Tuser user = (Tuser)load(Tuser.class,id) //这个通过CGLIB返回一个代理类,只有在真正使用它的属性的时候(比如:user.getName())才会真真去数据库中查询数据,这就是延迟加载机制 lazy。如果查找一个没有的记录,并且使用它的属性,则抛出一个ObjectNotFoundException,并且后台打印sql。
三 事务管理
事务的死个特性
原子性 事务中的操作是一个单元,要么都成功要么都失败
一致性 只有合法数据才能写入数据库,如果数据和字段类型不一致,则应该回滚到初始状态
隔离性 事务允许多个用户对数据库并发访问,而不破坏数据的正确性和完整性
持久性 事务结束后,处理的数据必须固化。
四 数据加载
前面已经讲过 查询有两种方法HQL 和Criteria
Tuser user=session.load(Tuser.class,new Integer(2)) //通过id为2加载实体Tuser
session 在加载实例对象的时候做了那些事情
1)、首先在Hibernate一级和二级缓冲中找有没有这个实体,有则返回。没有发起SQL查询
2)、根据映射和相应的SQL得到ResultSet,创建相应的数据对象。
3)、 将数据对象纳入一级和二级缓存。
4)、返回数据对象。
五 关联映射
User.java many
Group.java one
(1) many-to-one 单向 在多的一方加入一个外键,指向一的一端。有多的一方来维护关系
<many-to-one name="group" column="gid" class="" cascade=""/>
name:属性
column:映射到数据库的字段
class:one 方的类
cascade: all,none,save-update,delete(有问题),级联操作,删除,修改,保存。
a: cascade 默认为none的情况
Group g = new Group();
g.setName = "组1";
(1)
User user = new User();
user.setName("chen")
user.SetGroup(g);
session.save(user);
session.getTransaction.commit();//这里会抛TransientObjectExcetpion 因为g是游离态的对象,在数据库里还没有生产主键。
解决办法是在(1)地方 session.save(g);
b:cascade 设置为all 自动会级联把组和用户都存储进去
(2) one-to-many 单向 在多的一方加入一个外键,指向一的一端。由一的一方来维护关系
many-to-one 和one-to-many 的映射策略是一样的,都是在多的一方加入一外键,指向一的一方。只是角度不一样
Group.java
private Set users;
<set name="users">
<key column="gID" not-null="false"/> //key在这里就会把gID(随便取) 这个字段 加入到学生表了
<one-to-many class="cn.com.User"/>//指定users集合里是什么元素
</set>
eg1:
User user = new User();
user.setName("chen")
session.save(user);
User user2 = new User();
user2.setName("chen");
session.save(user2);
Set<User> set = new Set<User>
set.add(user);
set.add(user2);
Group g = new Group();
g.setName("组1");
g.setSet(set);
session.save(g);
session.getTransaction.commit();
//日志
Hibernate:insert into t_user(name) values(?)//首先还不能确定是按个组,所以只是把名字存进去
Hibernate:insert into t_user(name) values(?)
Hibernate:insert into t_group(name) values(?)
Hibernate:update t_user set gid=? where id=?//由一方来维护他们的关系,
Hibernate:update t_user set gid=? where id=?
缺陷:(1)维护困难,sql 语句明显多,需要多发出update语句
(2)<key column="gID" not-null="false"/> 如果设置为非空<not-null="true">肯定要出问题,在保存用户的时候gid还是null
(3) 一对多 双向
1.配置文件
多方
<many-to-one name="group" column="gid" class="" cascade=""/>
一方
<set name="users">
<key column="gid" not-null="false"/>
<one-to-many class="cn.com.User"/>
</set>
这里一定要注意: key中的gid 一定要和many-to-one里面的column="gid" 一模一样
2.属性inverse 反转,<key column="gid" not-null="true" inverse="true"/>
反转以后,一方失效,控制由多方来维护,所以不会再有update语句
eg1中的日志应该是
Hibernate:insert into t_user(name,gid) values(?,?)//首先还不能确定是按个组,所以只是把名字存进去,gid为null
Hibernate:insert into t_user(name,gid) values(?,?)
Hibernate:insert into t_group(name) values(?)
六:HQL
1. 所有属性(实体对象查询)
hql = "from Student " 或者 " select s from Student s "
1. 单个属性
hql = "select name from Student";
2. 多个属性
hql = " select id,name from new Student(id,name)";
属性查询都返回对象数组 Object[]
3. 统计查询
hql = "select count(*) from Student";
Long num = session.createQuery(hql).uniqueResult;//uniqueResult 用在单一值的情况下
两个对象查询 返回的是object[]
hql = " select c.name,count(s) from Student s (inner,left,right)jion s.classes c group by c.name order by c.name"
4. 链接查询 set students = new HashSet();
hql = " select c.name,s.name from Classes c left jion c.students s"
5. 条件查询
1)、通过拼凑字符串"+name+";
2)、单个参数通过? .setParameter(0,"");
3)、多个参数,通过占位符(:ids) setParameterList(ids,new Object[]{1,2,3,4});
采用hql拼接的缺陷:(1) 程序可读性差。(2)、难以进行性能优化,数据库具有对sql解析和优化,并将处理结果放入缓存中,如果
之后有不同的参数,语法相同的sql命令,则直接以缓存结果执行。而如果才用hql并接的sql参数不同则认为是多条sql命令,缓存的不到
利用。(3)、安全风险,SQL 注入攻击。
6. 原生sql 和sql addEntity 把数据库表的别名转换为对应的实体类
String hql = "";
hql+=" select {t.*} from t_user t where t.name="+chenl+";
hql+= " and t_classes=......"
List list = super.getSession().createSQLQuery(hql).addEntity("t",UserImpl.class).list();
return list;
}
7.Hiternate 通用的增删改查
增加:save(object)
删除:delete(object)
修改:saveOrUpdate(object)
查找:(1)、load和find这都是基于对象的,(2)、基于HQL查询(常用) (3)、原生SQL
8:基于DML风格的insert update delete select (批量)
相对于静态的数据可以使用DML风格的操作,尽量少用。因为数据库的更新和缓存不同步(发出sql以后不会在缓存中
同时放一份,压力太大,如果更新10万条数据,就需要在缓存中存放10万个对象。而使用通用的Hibernate操作,如果save操作,会在缓存里同时放一份);
session.createQuery("update Student s set s.name=? where id<?")
.setParameter(0,"李四")
.setParameter(1,3)
.executeUpdate();
9:HQL里面的list 和iterator
list 不会使用缓存,一条语句直接从数据库里查询到所有学生。然后放在缓存里面。所以list只玩缓存里放数据而不会使用缓存
iterator 则首先发去查询id列表的语句,去一级缓存(session)查询id对于的对象,然后如果一级缓存里面没有则通过id去数据库里面查询对应的数据也就是N+1问题。
7 缓存
Hibernate 缓存机制,缓存的持久对象均保存在一个类似Map对象里面,Key值持久对象的标识符(id),Value 为这个持久对象的数据。
(1)、一级缓存:一级缓存生命周期和session生命周期一致,它只缓存实体对象,但不会把普通属性放入一级缓存的
load(Student.class,1)、get(Student.class,1)、HQL里的iterator、Serializable Long id = save()都使用缓存。
一级缓存无法取消,但可以管理,可以通过session.clear()方法来清空缓存。如何避免大量数据入库导致内存溢出,
通过session.flush()同步缓存里的数据到数据库 session.clear()(清除缓存数据)。
(2)、二级缓存:二级缓存通常称为进程级别的缓存又称为sessionFactory,它可以被所有session共享。通过sessionFactory
管理。它的生命周期和sessionFactory的生命周期是一致的。它只缓存实体对象。ehcatch.jar。
如果开启两个session 通过每个session的load方法加载对象只会在调用第一个load方法时发一条sql语句,第二个load方法
不会发sql 它会在二级缓存里去找。可以通过sessFactory来管理二级缓存。比如清除 sessionFactory.evict(Student.class)
或者清除一个对象 sessionFactory.evict(Student.class,1);
二级缓存模式设置
session.setCacheMode(CacheMode.GET),仅仅向二级缓存读,而不向二级缓存写
session.setCacheMode(CacheMode.PUT),仅仅向二级缓存写,而不向二级缓存读
二级缓存适合于放入实体对象不会发生很大变化的数据。
二级缓存需要手动配置。
开启二级缓存,默认是自动开启的,也可以显示开启
<property name="hibernate.cache.use_level_cache">true</property>
指定二级缓存提供商
<property name="hibernate.cache.provide_class">org.hibernate.cache.EhCacheProvider></property>
指定缓存的类,可以在配置文件指定
<class-cache class="com.cn.chenlly.model.Student" usage="read-only"/>
(3)、查询缓存,主要用来缓存普通结果属性和实体对象id。
查询缓存的生命周期不确定。它的生命周期和session 无关。在外界对数据库进行修改之前失效。如果数据库修改以后。查询缓存立即失效
配置文件开启查询缓存
<property name="hibernate.cache.use_query_cache">true</property>
在类中配置
query.setCacheable(true);
注意:查询缓存对Query的list()起作用,对iterator()不起作用。
(4) 缓存对get()、load()、list()(HibernateTemplate 中对应find())、iterator() 影响
Session 对象的load()方法。从当前第一级缓存里标识符属性(id)对应的数据,如果未命中,判断是否配置了二级缓存,如果配置从二级缓存里找;否则从数据库中查询数据,并缓存到对应的一级和二级缓存中。
Session 对象的get()方法。首先从一级缓存里查找,如果未命中,直接查询数据库,并把数据放入一级缓存。
Query 对象的list()方法。一条查询语句查询对象的集合。首先检查是否配置了查询缓存,如果配置了,则判断是否命中缓存。如果未命中,则直接从数据库中查询数据并缓存到相应的一级,二级和查询缓存中。
Query 对象的iterator()方法。发送select 语句检索id字段,然后根据id 值在Session缓存和二级缓存中查找匹配的对象,如果存在,把它直接加到查询结果返回,如果不存在,根据刚才已经检索出来的id,执行额外的 select语句到数据库检索该对象。可能会出现n+1问题。
list()往一级和二级缓存里添加数据,但不利用一,二级缓存。如果没有配置查询缓存,都会发起一条sql往数据库中检索数据。
而iterato()充分利用一,二级缓存,如果缓存里有数据,直接拿,而不需要再次发起sql 检索数据库。















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









