






 本文详细介绍了如何使用minmax标准化处理数据以适应LSTM模型,包括其在收敛、稳定性和泛化能力上的优势。此外,还展示了如何定义LSTM模型,优化参数并进行未来预测,以及模型的评估方法。获取完整代码请访问gzhfinance褪黑素,回复关键词【24012202】。
本文详细介绍了如何使用minmax标准化处理数据以适应LSTM模型,包括其在收敛、稳定性和泛化能力上的优势。此外,还展示了如何定义LSTM模型,优化参数并进行未来预测,以及模型的评估方法。获取完整代码请访问gzhfinance褪黑素,回复关键词【24012202】。
本文包括数据处理、模型定义与优化参数算法以及模型评估三个主要部分,对代码和流程做了具体解释。
代码文件可在gzh‘finance褪黑素'回复关键词【24012202】得到。
目录
一、数据和minmax标准化
将数据集df划分为8:2:

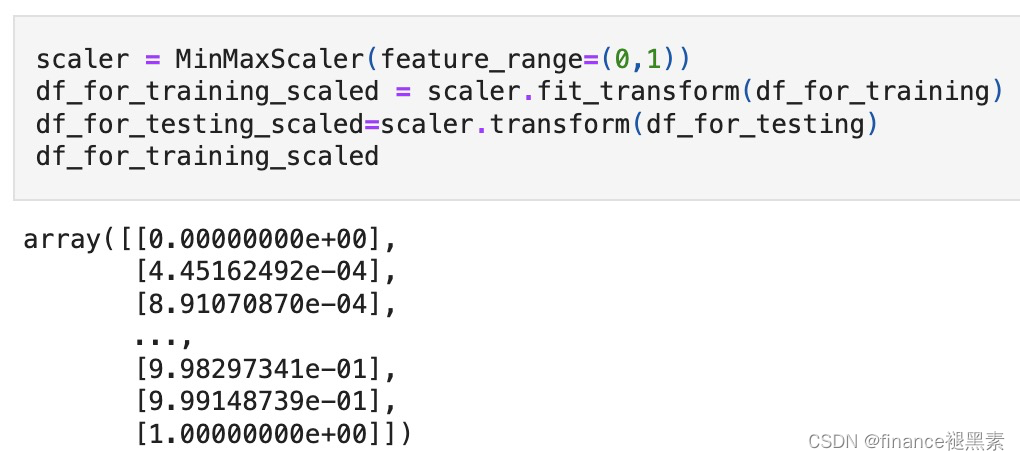
minmax标准化:
在训练深度学习模型,尤其是像LSTM这样的循环神经网络(RNN)时,进行标准化或归一化处理是一种常见的数据预处理。
加速收敛: 标准化或归一化可以使输入数据的分布更加接近标准正态分布,这有助于避免梯度消失或梯度爆炸的问题,从而加速模型的收敛过程。
提高梯度的稳定性: 标准化或归一化可以确保输入特征的尺度一致,这有助于使梯度在反向传播过程中更加稳定。
更好的泛化能力: 标准化或归一化可以提高模型的泛化能力,使其更适应不同尺度和范围的输入数据。
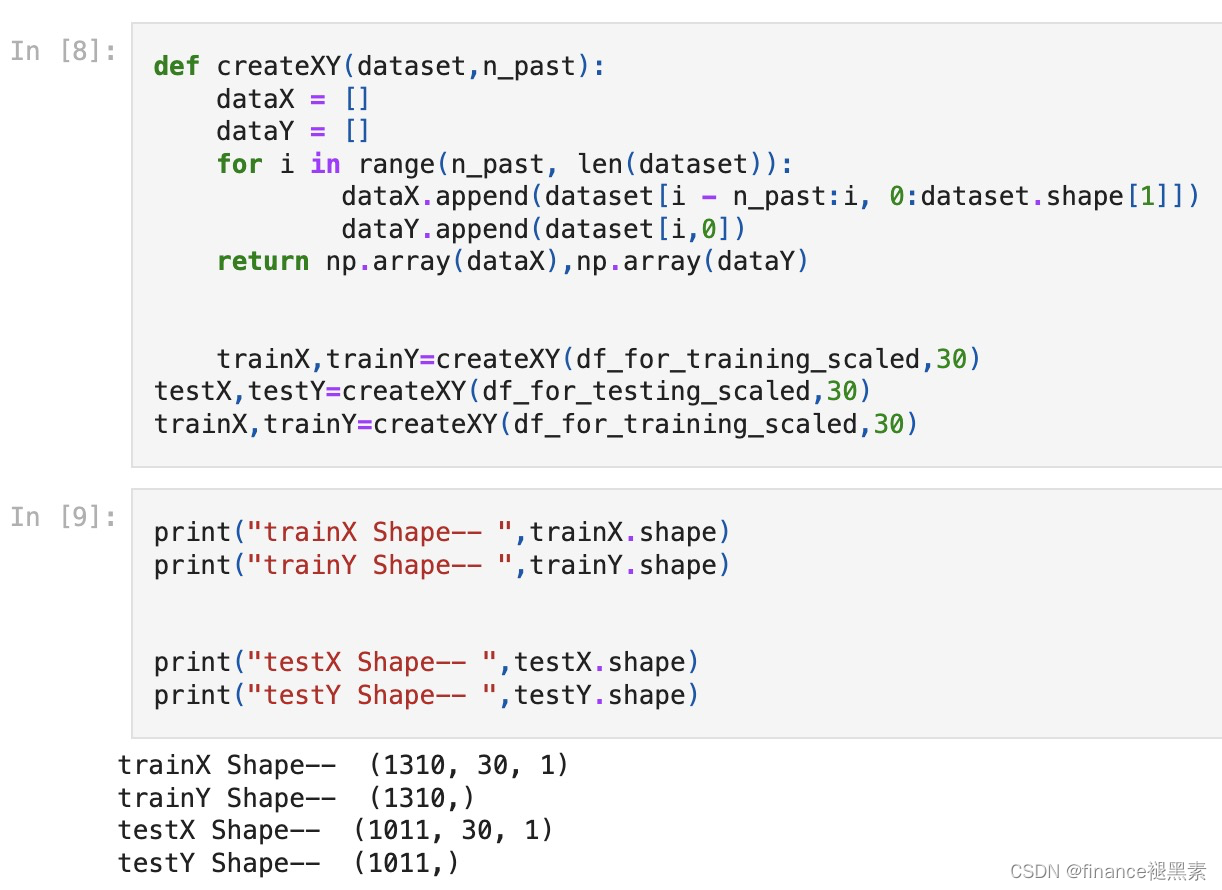
处理数据变成满足LSTM输入格式的数据:
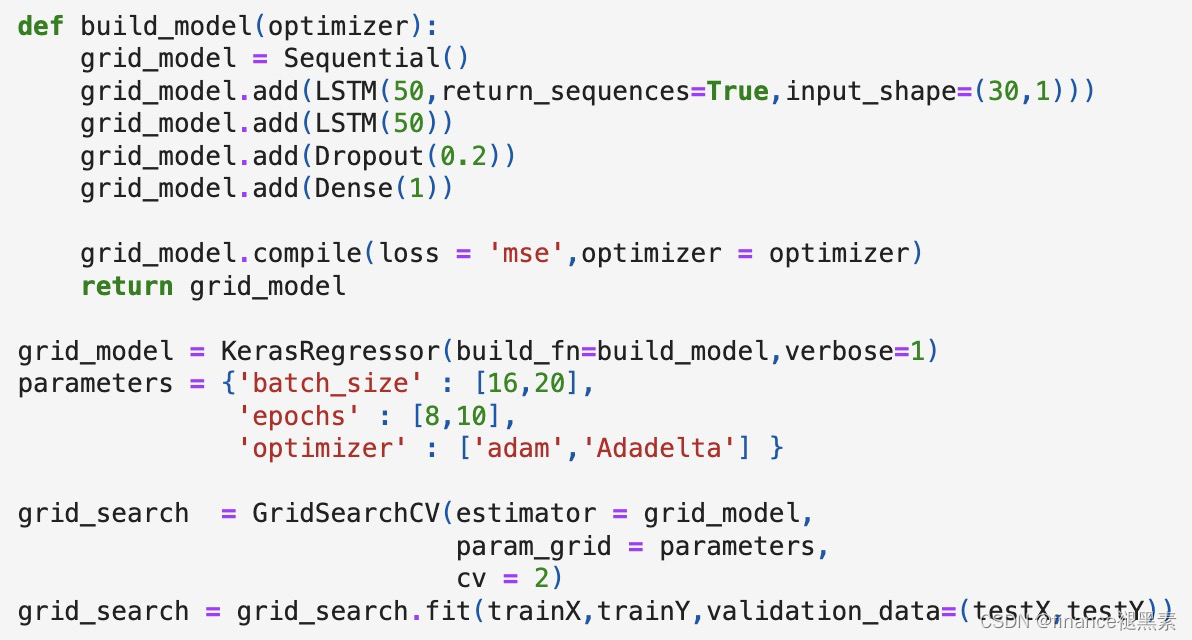
二、定义LSTM模型+优化参数算法
通过代码
grid_search.best_params_
输出训练得到的最佳参数:
{'batch_size': 16, 'epochs': 10, 'optimizer': 'adam'}
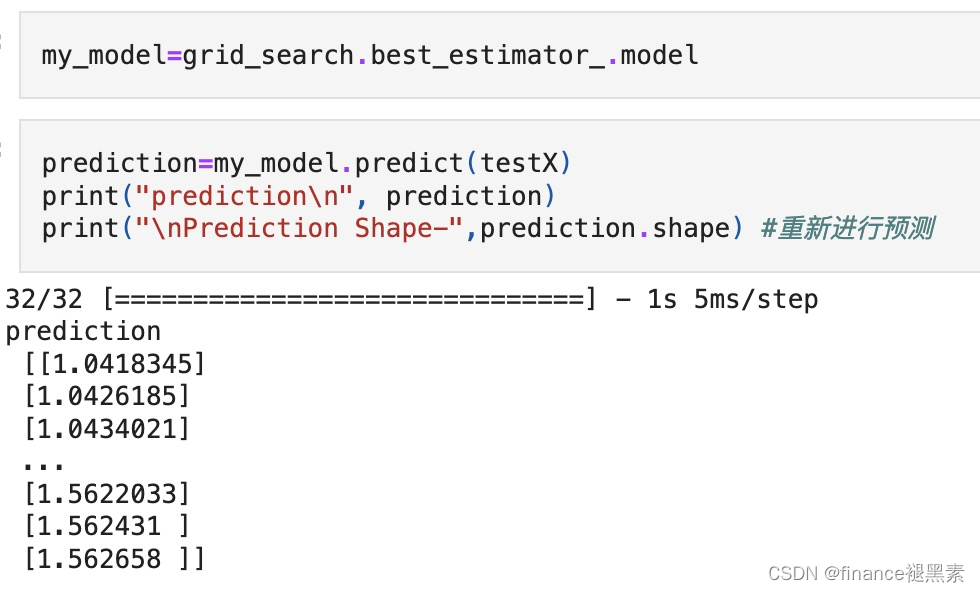
保存最佳参数为模型,继续预测测试集的数据:
外推未来30天的数据:
Pred Values-- [20.930216 20.934555 20.938894 ... 23.811514 23.812777 23.814034] Original Values-- [20.84429222 20.84897917 20.85366523 ... 24.49422085 24.49615282 24.49808021]
三、评估
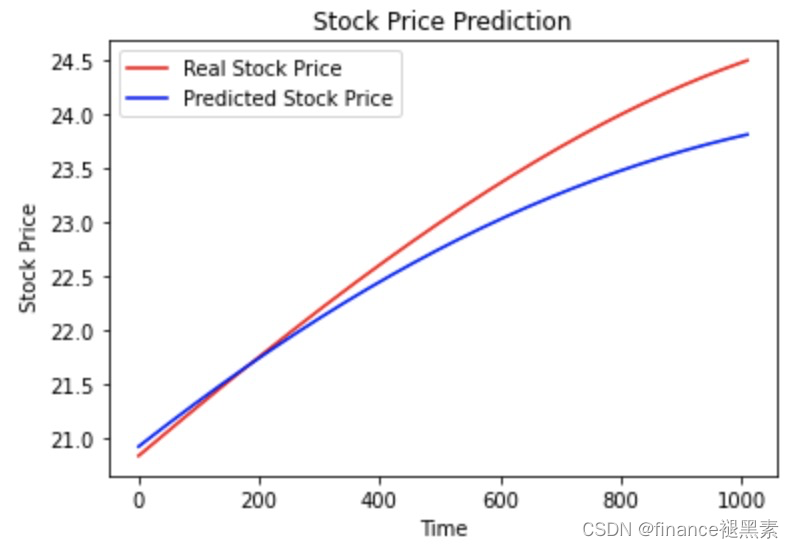
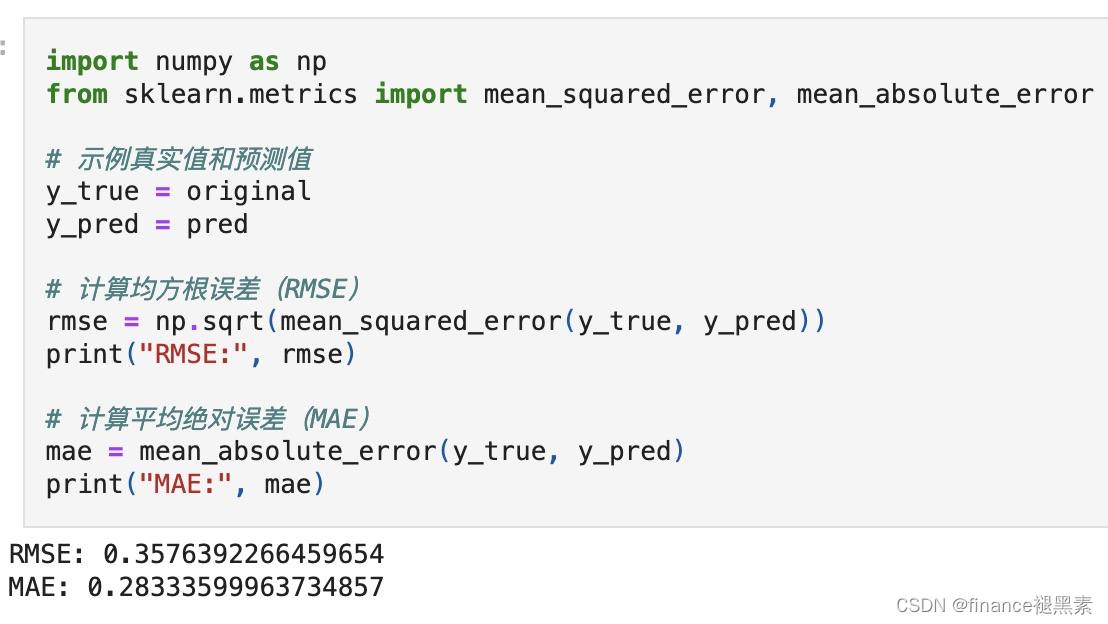
代码文件可在gzh‘finance褪黑素'回复关键词【24012202】

















 5857
5857

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









