









相关系数pearson、spearman、kendall和R语言中的cor/cor.test
1. 相关系数pearson、spearman、kendall
Pearson相关系数很简单,是用来衡量两个数据集的线性相关程度;而Spearman相关系数不关心两个数据集是否线性相关,而是单调相关,Spearman相关系数也称为等级相关或者秩相关(即rank);kendall相关系数是分类相关。
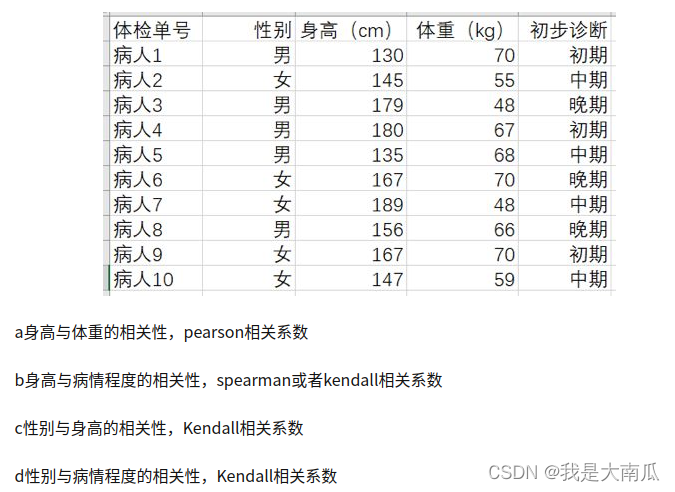
Pearson相关系数要求统计资料要是连续型变量,并且符合正态分布,而Spearman相关系数没有这个要求;Pearson相关系数在出现奇异值,或者长尾分布的时候稳定性差,不太靠,而Spearman要相对稳健很多。
require(gridExtra)
set.seed(1234)
a <- sample(100:130, 30)
b <- sample(100:130, 30)
df <- data.frame(a, b)
# 画散点图,线性拟合
p1 <- ggplot(df, aes(x=a, y=b)) + geom_smooth(method="lm") + geom_point() + xlim(0, 140) + ylim(0, 140)
# 计算Pearson和Spearman相关系数
cor.test(a, b, method="pearson")
cor.test(a, b, method="spearman")
a1=append(a,0)
b1=append(b,0)
length(b1)
df2 <- data.frame(a1, b1)
# 画散点图,线性拟合
p2 <- ggplot(df2, aes(x=a1, y=b1)) + geom_smooth(method="lm") + geom_point() + xlim(0, 140) + ylim(0, 140)
cor.test(a1, b1, method="pearson")
cor.test(a1, b1, method="spearman")
grid.arrange(p1,p2,ncol=2)

结果如下,由此可见,pearson方法确实对离群值不稳健,在本数据中没有spearman好。
> cor(a,b,method = "pearson")
[1] 0.02579568
> cor(a,b,method = "spearman")
[1] 0.01668521
> cor(a1,b1,method = "pearson")
[1] 0.8419337
> cor(a1,b1,method = "spearman")
[1] 0.108871
对于kendall相关系数,适用于分类变量:
参考:
https://baike.baidu.com/item/kendall%E7%A7%A9%E7%9B%B8%E5%85%B3%E7%B3%BB%E6%95%B0/6246854

2. R语言cor函数和cor.test函数
二者功能基本相同,只不过cor.test给出更详细的结果,此外cor.test不能使用矩阵,cor可以一次性计算矩阵两两相似性。
关于cor和cor.test中的method可选择不同的相关系数计算方法,另一个参数 use 也存在几种可选,可详细查看选择自己需要的mode。(参考最后一个链接)
参考:
https://byteofbio.com/archives/16.html (spearman 和pearson实例,代码来源)
https://zhuanlan.zhihu.com/p/33465271 (表格来源)
https://baike.baidu.com/item/kendall%E7%A7%A9%E7%9B%B8%E5%85%B3%E7%B3%BB%E6%95%B0/6246854 (kendall相关系数)
https://www.jianshu.com/p/6b9265bce085 (cor use参数讲解)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









