






一、前言
记录一下使用C++使用TensorRT加速yolov5的过程。至于为什么使用yolov5来做测试呢,主要是因为yolov5是一款较为经典的目标检测算法吧。而TensorRT是Nvidia开发的一款专门针对Nvidia显卡开发的一套加速库,它可以较大程度提升卷积神经网络的推理速度。比如,在yolov5中使用TensorRT加速后,在Win11系统和Nvidia RTX3050 6GB的配置下,使用yolov5s的权重推理一张640x640的图像只需要7ms左右,使用yolov5m的权重只需要15ms左右。这个推理速度已经满足大部分工程需要了。(注意:这里使用的是yolov5-7.0版本)
二、准备工作
在讲述C++的TensorRT相关代码之前需要做一些基本的配置,如:OpenCV、TensorRT、CUDA以及cuDNN的安装。在安装完成上述库之后,需要从yolov5官方网站中下载代码(GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite)以及对应权重。在下载完成后,将对应权重放在yolov5目录下,并在该目录下打开终端,如下图:
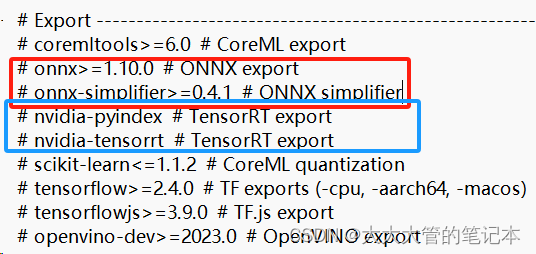
(注意:这里没有安装onnx,如果需要一起安装可以把requirements.txt文件中,下面两部分取消注释):
输入下面指令完成yolov5所需要的各种库:
pip install -r requirements.txt # install完成上述安装后,可以开始生成TensorRT所需要的权重文件了。
python export.py --weights yolov5s.pt --include engine --device 0运行上面代码之后,需要耐心等待一会儿。上面的代码需要先将yolov5s的.pt权重先转换为.onnx权重,然后转换为.engine权重。在后面这一步的转换速度会较慢。等待程序运行完成后,会多出两个文件yolov5s.onnx和yolov5s.engine。
三、TensorRT加速yolov5
1.生成.engine文件
如果在准备工作中已经使用官方的python代码生成了.engine权重的话,这一步可以跳过。
主要流程为:
(1)创建builder;
(2)创建网络network;
(3)创建onnx文件解析类,解析onnx文件;
(4)创建生成器配置;
(5)创建推理引擎,并进行序列化,将引擎保存在本地;
代码及注释如下:
void onnx_to_engine(std::string onnx_file_path, std::string engine_file_path, int type) {
// 构建器,获取cuda内核目录以获取最快的实现
// 用于创建config、network、engine的其他对象的核心类
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(gLogger);
const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH); // 显式批处理
// 解析onnx网络文件
// tensorRT模型类
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(explicitBatch);
// onnx文件解析类
// 将onnx文件解析,并填充rensorRT网络结构
nvonnxparser::IParser* parser = nvonnxparser::createParser(*network, gLogger);
// 解析onnx文件
parser->parseFromFile(onnx_file_path.c_str(), 2);
for (int i = 0; i < parser->getNbErrors(); ++i) {
std::cout << "load error: " << parser->getError(i)->desc() << std::endl;
}
printf("tensorRT load mask onnx model successfully!!!...\n");
// 创建推理引擎
// 创建生成器配置对象。
nvinfer1::IBuilderConfig* config = builder->createBuilderConfig();
// 设置最大工作空间大小。
config->setMaxWorkspaceSize(1 << 30); //2的30次方的大小
// 设置模型输出精度
if (type == 1) {
config->setFlag(nvinfer1::BuilderFlag::kFP16);
}
if (type == 2) {
config->setFlag(nvinfer1::BuilderFlag::kINT8);
}
// 创建推理引擎
nvinfer1::ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
// 将推理引擎保存到本地
std::cout << "try to save engine file now~~~" << std::endl;
std::ofstream file_ptr(engine_file_path, std::ios::binary);
if (!file_ptr) {
std::cerr << "could not open plan output file" << std::endl;
return;
}
// 将模型转化为文件流数据
nvinfer1::IHostMemory* model_stream = engine->serialize();
// 将文件保存到本地
file_ptr.write(reinterpret_cast<const char*>(model_stream->data()), model_stream->size());
// 销毁创建的对象
model_stream->destroy();
engine->destroy();
network->destroy();
parser->destroy();
std::cout << "convert onnx model to TensorRT engine model successfully!" << std::endl;
}2.初始化引擎
读取生成的.engine文件(注意:这里要使用二进制的方式读取)。然后进行反序列化,生成推理引擎。
// 日志记录接口
Logger logger;
// 反序列化引擎
initLibNvInferPlugins(&logger, "");
nvinfer1::IRuntime* runtime = nvinfer1::createInferRuntime(logger);
// 推理引擎
// 保存模型的模型结构、模型参数以及最优计算kernel配置;
// 不能跨平台和跨TensorRT版本移植
nvinfer1::ICudaEngine* engine = runtime->deserializeCudaEngine(model_stream, size);
// 上下文
// 储存中间值,实际进行推理的对象
// 由engine创建,可创建多个对象,进行多推理任务
nvinfer1::IExecutionContext* context = engine->createExecutionContext();3.创建内存缓冲区
在学习TensorRT时,这一部分最难理解,下面将仔细讲一讲。在理解之后,就比较容易了。简单来讲就是CPU内存和GPU内存相互转换,在CPU中进行图像的预处理等,然后将处理后的图片放到GPU内存中进行计算,当GPU计算完毕后有需要将计算好的数据放到CPU中进行后续的处理,比如筛选、非极大值抑制、画框等。
// 创建GPU显存缓冲区
void** data_buffer = new void* [num_ionode]; // 一个输入,一个输出
// 创建GPU显存输入缓冲区
int input_node_index = engine->getBindingIndex(input_node_name); // input_node_index=0
nvinfer1::Dims input_node_dim = engine->getBindingDimensions(input_node_index);
size_t input_data_length = input_node_dim.d[1] * input_node_dim.d[2] * input_node_dim.d[3]; // BCWH {1, 3, 640, 640, 0, 0, 0, 0}
cudaMalloc(&(data_buffer[input_node_index]), input_data_length * sizeof(float));
// 创建GPU显存输出缓冲区
int output_node_index = engine->getBindingIndex(output_node_name); // output_node_index=1
nvinfer1::Dims output_node_dim = engine->getBindingDimensions(output_node_index);
size_t output_data_length = output_node_dim.d[1] * output_node_dim.d[2];// [b,num_pre_boxes,classes+5] {1, 25200, 85, 0, 0, 0, 0, 0}
cudaMalloc(&(data_buffer[output_node_index]), output_data_length * sizeof(float));上面代码就是根据输入和输出,在GPU中创建内存缓冲区,这个时候里面是没有数据的,是为了后面将CPU中的图像数据放进去,以及CPU从GPU的哪一段内存中获取输出的数据。
4.图像预处理
这里不是重点,简单讲一下,就是将图像添加黑边,缩放到输入尺寸640x640,然后归一化等操作。
5.预热
这一部分在源码中是没有的,而这一步非常重要。因为博主刚学习的时候,源码中缺少这一段,导致输出的结果的时间大概为40多ms,而python中的时间大致为8,9ms,差距太大了。博主仔细对比了C++代码和python代码,发现C++代码中缺少预热这一步,导致输出数据差距过大。
预热这一步的思路也比较简单,在CPU中开辟内存,并以0填充,同步到GPU中,在GPU中计算。
// 预热(预热可以大幅提升速度)
for (int i = 0; i < 10; i++)
{
void* h_ptr = malloc(input_data_length * sizeof(float)); // CPU中按照输入尺寸开启内存
memset(h_ptr, 0, input_data_length * sizeof(float)); // 用0来填充内存
cudaMemcpyAsync(data_buffer[input_node_index], h_ptr, size, cudaMemcpyHostToDevice, stream); // 同步到GPU内存
free(h_ptr); // 释放CPU中的内存
context->enqueueV2(data_buffer, stream, nullptr); // 在GPU中推理
cudaStreamSynchronize(stream); // 将流作为参数并等待,直到给定流中的所有先前命令都已完成
}
std::cout << "Model warm up 10 times." << std::endl;这里贴一下两者的计算速度的区别,使用预热处理前:

使用预热处理后:
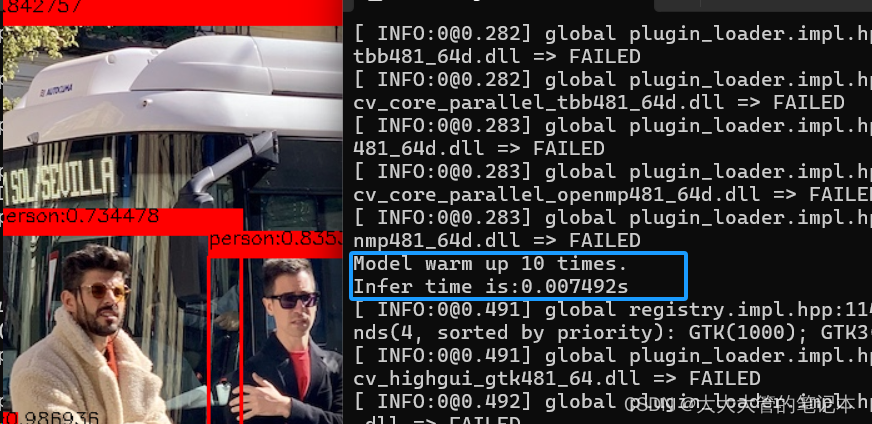
6.推理
推理的代码比较简单,在推理前需要将CPU数据放在GPU中,在GPU中计算完毕后,再同步到CPU中,做后处理。(注意:这里输出的时间,仅仅是在GPU中进行推理的时间,不包括前处理和后处理部分的时间)
// 输入数据由内存到GPU显存
cudaMemcpyAsync(data_buffer[input_node_index], input_data.data(), input_data_length * sizeof(float), cudaMemcpyHostToDevice, stream);
auto start = std::chrono::system_clock::now(); // 计算推理时间
// 模型推理
context->enqueueV2(data_buffer, stream, nullptr);
// 将GPU数据同步到CPU中
float* result_array = new float[output_data_length];
cudaMemcpyAsync(result_array, data_buffer[output_node_index], output_data_length * sizeof(float), cudaMemcpyDeviceToHost, stream);
auto end = std::chrono::system_clock::now();
auto tc = (double)std::chrono::duration_cast<std::chrono::microseconds>(end - start).count()/1000000.;
std::cout << "Infer time is:" << tc << std::endl;7.后处理
后处理部分需要理解yolov5的相关输出以及后处理的思路。简单来讲就是判断是否满足置信度、对满足条件的锚框做非极大值抑制、还原图片大小等。
四、总结
总的来说C++使用TensorRT加速yolov5不算太难,重要的是理解CPU内存与GPU内存的转换以及yolov5输出的后处理等。后面需要不断学习,在GitHub - triple-Mu/YOLOv8-TensorRT: YOLOv8 using TensorRT accelerate !中对onnx的处理就比较奇妙了,直接将nms融入到最后网络中,把输出分成了4个,分别对4个输出进行处理,简直太妙啦~~
博主也是初学,要是有不正确的地方,希望得到您的指点,万分感谢~~~
头文件等都在源码中 ,请自寻寻找。
最后,贴一下修改后的代码:
#include<windows.h>
#include <fstream>
#include <iostream>
#include <sstream>
#include <vector>
#include "NvInfer.h"
#include "NvOnnxParser.h"
#include "NvInferPlugin.h"
#include <opencv2/opencv.hpp>
#include "include/result.h"
// @brief 用于创建IBuilder、IRuntime或IRefitter实例的记录器用于通过该接口创建的所有对象。
// 在释放所有创建的对象之前,记录器应一直有效。
// 主要是实例化ILogger类下的log()方法。
class Logger : public nvinfer1::ILogger
{
void log(Severity severity, const char* message) noexcept
{
// suppress info-level messages
if (severity != Severity::kINFO)
std::cout << message << std::endl;
}
} gLogger;
void onnx_to_engine(std::string onnx_file_path, std::string engine_file_path, int type) {
// 构建器,获取cuda内核目录以获取最快的实现
// 用于创建config、network、engine的其他对象的核心类
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(gLogger);
const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH); // 显式批处理
// 解析onnx网络文件
// tensorRT模型类
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(explicitBatch);
// onnx文件解析类
// 将onnx文件解析,并填充rensorRT网络结构
nvonnxparser::IParser* parser = nvonnxparser::createParser(*network, gLogger);
// 解析onnx文件
parser->parseFromFile(onnx_file_path.c_str(), 2);
for (int i = 0; i < parser->getNbErrors(); ++i) {
std::cout << "load error: " << parser->getError(i)->desc() << std::endl;
}
printf("tensorRT load mask onnx model successfully!!!...\n");
// 创建推理引擎
// 创建生成器配置对象。
nvinfer1::IBuilderConfig* config = builder->createBuilderConfig();
// 设置最大工作空间大小。
config->setMaxWorkspaceSize(1 << 30); //2的30次方的大小
// 设置模型输出精度
if (type == 1) {
config->setFlag(nvinfer1::BuilderFlag::kFP16);
}
if (type == 2) {
config->setFlag(nvinfer1::BuilderFlag::kINT8);
}
// 创建推理引擎
nvinfer1::ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
// 将推理引擎保存到本地
std::cout << "try to save engine file now~~~" << std::endl;
std::ofstream file_ptr(engine_file_path, std::ios::binary);
if (!file_ptr) {
std::cerr << "could not open plan output file" << std::endl;
return;
}
// 将模型转化为文件流数据
nvinfer1::IHostMemory* model_stream = engine->serialize();
// 将文件保存到本地
file_ptr.write(reinterpret_cast<const char*>(model_stream->data()), model_stream->size());
// 销毁创建的对象
model_stream->destroy();
engine->destroy();
network->destroy();
parser->destroy();
std::cout << "convert onnx model to TensorRT engine model successfully!" << std::endl;
}
int main() {
const char* model_path_onnx = "这里改成自己的路径/yolov5s.onnx";
const char* model_path_engine = "这里改成自己的路径/yolov5s.engine";
const char* image_path = "这里改成自己的路径/bus.jpg";
std::string lable_path = "这里改成自己的路径/lable.txt";
const char* input_node_name = "images"; // 这里需要看一下onnx文件的输入
const char* output_node_name = "output0"; // 这里需要看一下onnx文件的输出
int num_ionode = 2;
// 读取本地engine模型文件
std::ifstream file_ptr(model_path_engine, std::ios::binary);
if (!file_ptr.good()) {
std::cerr << "文件无法打开,请确定文件是否可用!" << std::endl;
}
size_t size = 0;
file_ptr.seekg(0, file_ptr.end); // 将读指针从文件末尾开始移动0个字节
size = file_ptr.tellg(); // 返回读指针的位置,此时读指针的位置就是文件的字节数
file_ptr.seekg(0, file_ptr.beg); // 将读指针从文件开头开始移动0个字节
char* model_stream = new char[size];
file_ptr.read(model_stream, size);
file_ptr.close();
// 日志记录接口
Logger logger;
// 反序列化引擎
initLibNvInferPlugins(&logger, "");
nvinfer1::IRuntime* runtime = nvinfer1::createInferRuntime(logger);
// 推理引擎
// 保存模型的模型结构、模型参数以及最优计算kernel配置;
// 不能跨平台和跨TensorRT版本移植
nvinfer1::ICudaEngine* engine = runtime->deserializeCudaEngine(model_stream, size);
// 上下文
// 储存中间值,实际进行推理的对象
// 由engine创建,可创建多个对象,进行多推理任务
nvinfer1::IExecutionContext* context = engine->createExecutionContext();
delete[] model_stream;
// 创建GPU显存缓冲区
void** data_buffer = new void* [num_ionode]; // 一个输入,一个输出
// 创建GPU显存输入缓冲区
int input_node_index = engine->getBindingIndex(input_node_name); // input_node_index=0
nvinfer1::Dims input_node_dim = engine->getBindingDimensions(input_node_index);
size_t input_data_length = input_node_dim.d[1] * input_node_dim.d[2] * input_node_dim.d[3]; // BCWH {1, 3, 640, 640, 0, 0, 0, 0}
cudaMalloc(&(data_buffer[input_node_index]), input_data_length * sizeof(float));
// 创建GPU显存输出缓冲区
int output_node_index = engine->getBindingIndex(output_node_name); // output_node_index=1
nvinfer1::Dims output_node_dim = engine->getBindingDimensions(output_node_index);
size_t output_data_length = output_node_dim.d[1] * output_node_dim.d[2];// [b,num_pre_boxes,classes+5] {1, 25200, 85, 0, 0, 0, 0, 0}
cudaMalloc(&(data_buffer[output_node_index]), output_data_length * sizeof(float));
// 图象预处理 - 格式化操作
cv::Mat image = cv::imread(image_path);
int max_side_length = std::max(image.cols, image.rows);
cv::Mat max_image = cv::Mat::zeros(cv::Size(max_side_length, max_side_length), CV_8UC3);
cv::Rect roi(0, 0, image.cols, image.rows);
image.copyTo(max_image(roi));
// 将图像归一化,并放缩到指定大小
cv::Size input_node_shape(input_node_dim.d[2], input_node_dim.d[3]);
cv::Mat BN_image = cv::dnn::blobFromImage(max_image, 1 / 255.0, input_node_shape, cv::Scalar(0, 0, 0), true, false);
std::vector<float> input_data(input_data_length);
memcpy(input_data.data(), BN_image.ptr<float>(), input_data_length * sizeof(float)); //将图像数据放到input_data中(CPU)
// 创建输入cuda流
cudaStream_t stream;
cudaStreamCreate(&stream);
// 预热(预热可以大幅提升速度)
for (int i = 0; i < 10; i++)
{
void* h_ptr = malloc(input_data_length * sizeof(float)); // CPU中按照输入尺寸开启内存
memset(h_ptr, 0, input_data_length * sizeof(float)); // 用0来填充内存
cudaMemcpyAsync(data_buffer[input_node_index], h_ptr, size, cudaMemcpyHostToDevice, stream); // 同步到GPU内存
free(h_ptr); // 释放CPU中的内存
context->enqueueV2(data_buffer, stream, nullptr); // 在GPU中推理
cudaStreamSynchronize(stream); // 将流作为参数并等待,直到给定流中的所有先前命令都已完成
}
std::cout << "Model warm up 10 times." << std::endl;
// 输入数据由内存到GPU显存
cudaMemcpyAsync(data_buffer[input_node_index], input_data.data(), input_data_length * sizeof(float), cudaMemcpyHostToDevice, stream);
auto start = std::chrono::system_clock::now(); // 计算推理时间
// 模型推理
context->enqueueV2(data_buffer, stream, nullptr);
// 将GPU数据同步到CPU中
float* result_array = new float[output_data_length];
cudaMemcpyAsync(result_array, data_buffer[output_node_index], output_data_length * sizeof(float), cudaMemcpyDeviceToHost, stream);
auto end = std::chrono::system_clock::now();
auto tc = (double)std::chrono::duration_cast<std::chrono::microseconds>(end - start).count()/1000000.;
std::cout << "Infer time is:" << tc << "s" << std::endl;
ResultYolov5 result;
result.factor = max_side_length / (float)input_node_dim.d[2]; // 缩放因子 图像最长边/输入网络宽高(640)
result.read_class_names(lable_path);
cv::Mat result_image = result.yolov5_result(image, result_array);
// 查看输出结果
cv::imshow("C++ + tensorRT + Yolov5 推理结果", result_image);
cv::waitKey();
}
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









