







 本文概述3D目标检测现状,介绍PCDet库,并深入解析PointPillars算法原理与工程实践,适合自动驾驶及机器人领域的研究者。
本文概述3D目标检测现状,介绍PCDet库,并深入解析PointPillars算法原理与工程实践,适合自动驾驶及机器人领域的研究者。

本文是根据github上的开源项目:https://github.com/open-mmlab/OpenPCDet整理而来,在此表示感谢,强烈推荐大家去关注。使用的预训练模型也为此项目中提供的模型,不过此项目已更新为v0.2版,与本文中代码略有不同。
本文实现的3D目标检测算法是PointPillars,论文地址为:https://arxiv.org/abs/1812.05784,使用的激光雷达点云数据是KITTI数据(http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d)。
文章目录
1. 3D目标检测
在开始写代码实现PointPillars检测算法之前,我想先介绍一些关于点云3D目标检测的背景知识。大家有时间的话可以看看下面这个报告,是OpenPCDet项目作者此前分享的报告(https://www.bilibili.com/video/av89811975?zw)。
(2021-04-11日补充):点云3D目标检测算法库OpenPCDet解析与开发实践(Video)
基于点云场景的三维物体检测算法及应用
(2021-1-27日补充):这是PointNet作者2021年分享的报告《3D物体检测发展与未来》,对3D物体检测感兴趣的朋友可以看看,PointNet作者对PointPillars算法进行了解读。
【PointNet作者亲述】90分钟带你了解3D物体检测算法和未来方向!
1.1 3D目标检测研究现状
毋庸置疑,在自动驾驶或辅助机器人等应用中,3D目标检测现在变得越来越重要。在这当中,激光雷达(LiDAR)是使用最为广泛的3D传感器,LiDAR可以生成稀疏,不规则的点云数据。
关于3D目标检测,根据点云表示方法大致可以分为两类:the grid-based methods 和 the point-based methods。下面简要介绍这两种方法:
3D Object Detection with Grid-based Methods:由于点云是不规则的,之前的学者通常会对点云进行投影或栅格化处理,转换成规则的grid数据格式,然后再使用2D或3DCNN处理。
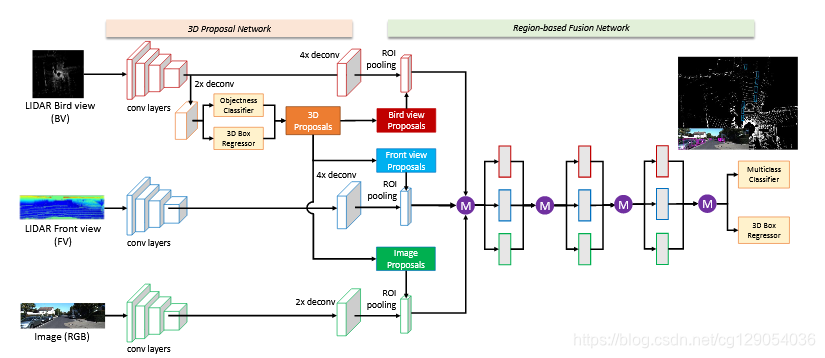
MV3D(https://arxiv.org/abs/1611.07759)将点云投影到鸟瞰图或前视图上进行处理,然后使用多个预定义的3D anchors来生成3D bounding boxes。- 除了将点云投影到鸟瞰图上,还可以将点云直接转换为
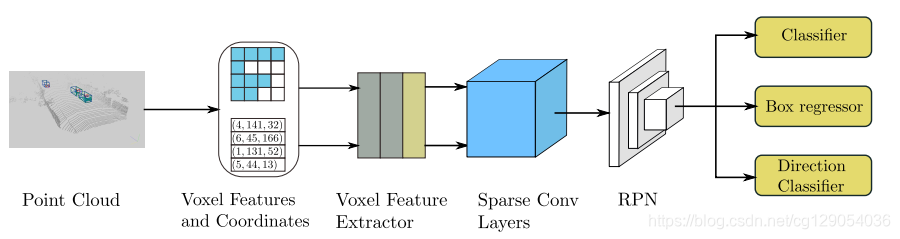
3D Voxels格式,然后使用3DCNN来检测,这其中的代表论文有VoxelNet(https://arxiv.org/abs/1711.06396),Second(https://www.mdpi.com/1424-8220/18/10/3337)。
| MV3D | VoxelNet | Second |
|---|---|---|
 |  |  |
以上方法虽然能够高效的生成3D候选方案,但是其目标检测感受野往往是有限的,点云在转换成grid时,不可避免的会出现信息丢失的情况。 |
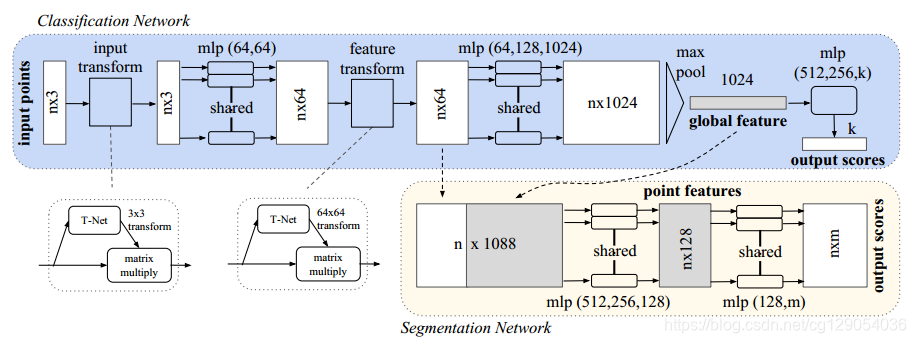
3D Object Detection with Point-based Methods:基于Point的方法大多数都是使用PointNet(https://arxiv.org/abs/1612.00593)网络进行点云特征学习,这使得网络能有更灵活的感受野进行点云特征学习,同时也保留了点云的原始数据信息。
这其中的代表论文是PointRCNN(https://arxiv.org/abs/1812.04244),这是一个两阶段的目标检测方案,第一阶段通过PointNet++网络将点云分为前景点和背景点,然后对每一个前景点生成一个候选方案,第二阶段对前景点及其候选方案进行进一步优化,生成最终的bounding box。
| PointNet | PointRCNN |
|---|---|
 |  |
1.2 点云3D目标检测开源库
这里引用PCDet作者之前分享的文章(https://zhuanlan.zhihu.com/p/152120636)。PCDet 3D目标检测框架的整体结构设计与优势为:
数据—模型分离的顶层代码框架设计思想:
与图像处理所不同,不同点云数据集中3D坐标定义与转换往往使研究者很是迷糊。因此,
PCDet定义了统一的规范化3D坐标表示贯穿整个数据处理与模型计算,从而将数据模块与模型处理模块完全分离,其优势体现在:
- 研究者在研发不同结构模型时,使用统一标准化的3D坐标系进行各种相关处理(比如计算
loss、RoI Pooling和模型后处理等),而无需理会不同数据集的坐标规定差异性;- 研究者在添加新数据集时,只需写少量代码将原始数据转化到标准化坐标定义下,
PCDet将自动进行数据增强并适配到各种模型中。PCDet数据—模型分离的顶层设计,使得研究者可以轻松适配各种模型到不同的点云3D目标检测数据集上,免去研发模型时迷失在3D坐标转换中的顾虑。
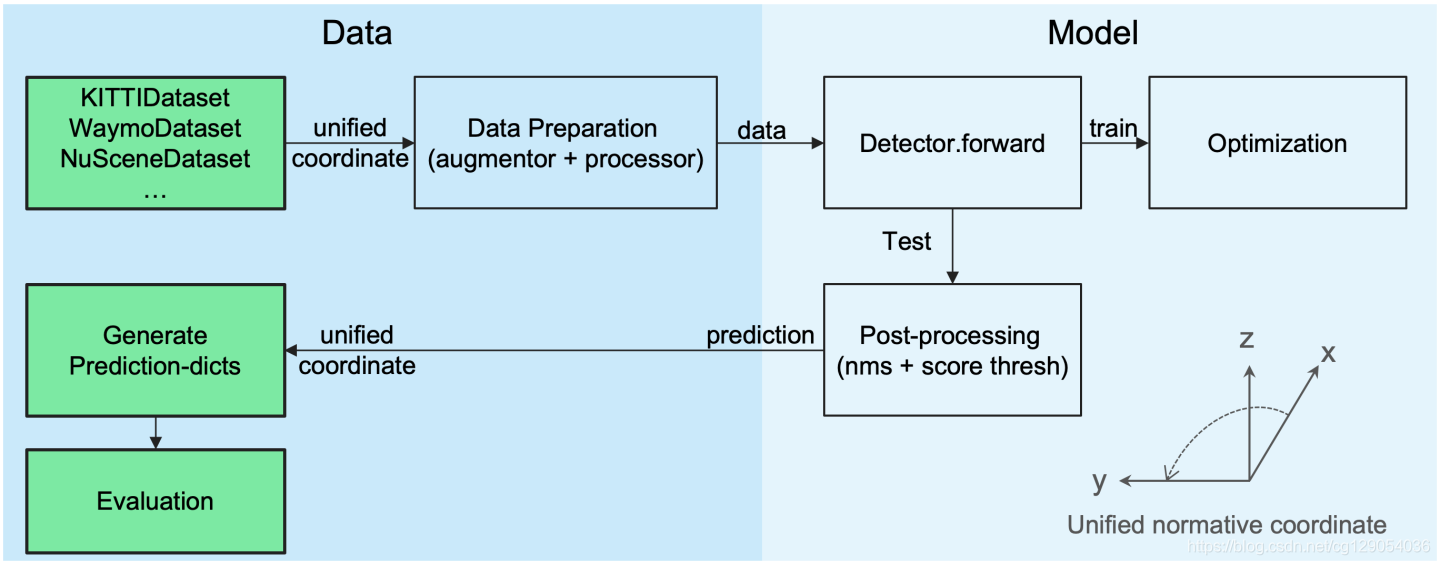 统一的3D目标检测坐标定义:
统一的3D目标检测坐标定义:
不同的点云数据集在坐标系以及3D框的定义上往往不一样(KITTI数据集中的camera和LiDAR两个坐标系经常让人混乱),因此在 PCDet 中采用了固定的统一点云坐标系,以及更规范的3D检测框定义,贯穿整个数据增强、处理、模型计算以及检测后处理过程。3D检测框的7维信息定义如下:
3D bounding box: (x, y, z, dx, dy, dz, heading)
其中,(x, y, z) 为物体3D框的几何中心位置,(dx, dy, dz)分别为物体3D框在heading角度为0时沿着x-y-z三个方向的长度,heading为物体在俯视图下的朝向角 (沿着x轴方向为0度角,逆时针x到y角度增加)。
基于 PCDet 所采用的标准化3D框定义,再也不用纠结到底是物体3D中心还是物体底部中心;再也不用纠结物体三维尺寸到底是l-w-h排列还是w-l-h排列;再也不用纠结heading 0度角到底是哪,到底是顺时针增加还是逆时针增加。
灵活全面的模块化模型拓扑设计:
基于下图所示的灵活且全面的模块化设计,在PCDet中搭建3D目标检测框架只需要写config文件将所需模块定义清楚,然后PCDet将自动根据模块间的拓扑顺序组合为3D目标检测框架,来进行训练和测试。
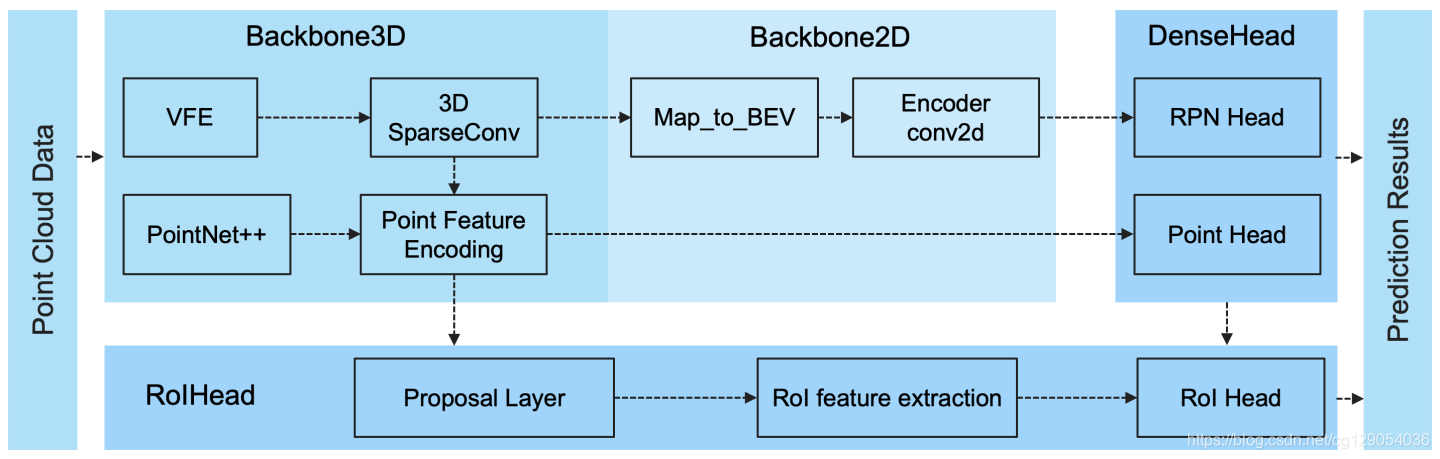 PCDet可以支持目前已有的绝大多数面向LiDAR点云的3D目标检测算法,包括
PCDet可以支持目前已有的绝大多数面向LiDAR点云的3D目标检测算法,包括voxel-based,point-based,point-voxel hybrid以及one-stage/two-stage等等3D目标检测算法。

2. PointPillars网络及工程概述
2.1 PointPillars工作原理
现在不妨先了解一下PointPillars是如何工作的。PointPillars整体思路是将3维的点云转成2维的伪图像,然后使用二维卷积网络进行端到端的目标检测,网络结构如下图所示。
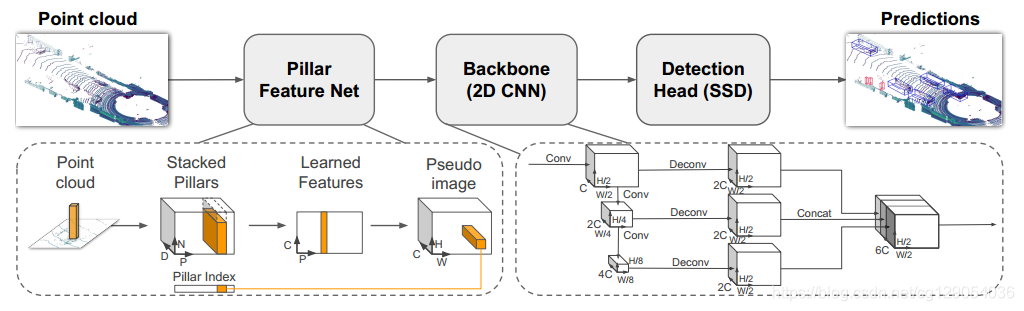 下面分别介绍
下面分别介绍PointPillars的三个子网络部分:
(1)Pillar Feature Net
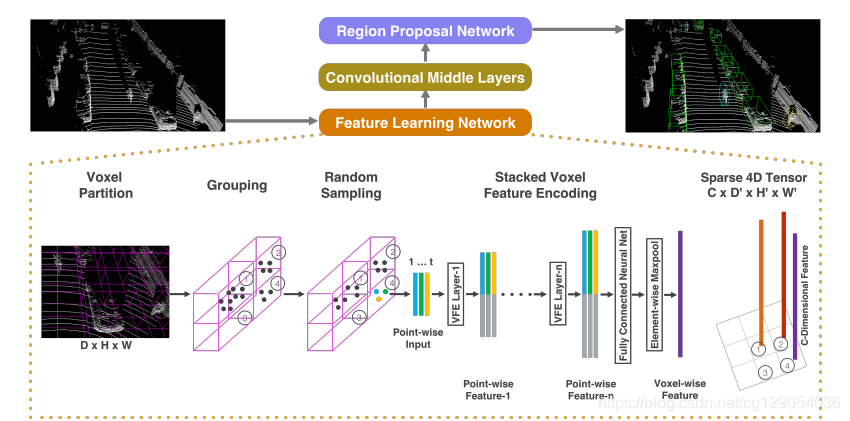
Feature Net主要是负责把点云数据处理成类似图像的数据。首先可以将x-y平面投影为一个大小为h x w的网格。每一个小网格表示为一个Pillar,这样就划分出h x w个Pillar。
原始的点云数据有(x,y,z,r)4个维度,r代表点云反射率,论文中将其扩展为9个维度(x, y, z, r, x_c, y_c, z_c, x_p, y_p),带c下标的是柱子中的点相对于柱子中心的偏移位置坐标,带p下标的是点相对于整个大网格中心的全局偏移位置坐标。于是就形成了维度为(D, P, N)的张量, 其中D=9(不过PCDet实现与论文稍有不同,PCDet扩展成D=10), N为每个Pillar的采样点数,P为非空的Pillar数目。
然后就是学习点云特征,用一个简化的PointNet从D维中学出C个channel来得到一个(C, P, N)的张量。在N这个维度上做max pooling operation,得到(C, P)的张量.最后得到(C,H,W)的伪图像.
(2)Backbone
包含两个子网络,一个是自上而下的下采样网络,另一个是上采样网络,具体网络结构可以看本文2.2节。
(3)Detection
检测头使用的是SSD的检测头,关于SSD算法细节可以参考《动手学深度学习》这本书(http://zh.d2l.ai/chapter_computer-vision/ssd.html)。
PointPillars工作原理就介绍这么多,下面将介绍PointPillar工程的整体结构。
2.2 PointPillar工程
参考PCDet,PointPillars各文件组织方式如下,这里暂时只需要对整个工程有个整体印象,后面将逐步完成各文件中的代码:
PCDet
├── data
│ ├── velodyne
│ │ │──000010.bin
├── doc
├── output
├── pcdet
│ ├── config.py
│ ├── datasets
│ │ ├── dataset.py
│ │ ├── __init__.py
│ │ ├── kitti
│ │ │ ├── kitti_dataset.py
│ │ │ └── __pycache__
│ │ │ └── kitti_dataset.cpython-36.pyc
│ │ └── __pycache__
│ │ ├── dataset.cpython-36.pyc
│ │ └── __init__.cpython-36.pyc
│ ├── models
│ │ ├── bbox_heads
│ │ │ ├── anchor_target_assigner.py
│ │ │ ├── __pycache__
│ │ │ │ ├── anchor_target_assigner.cpython-36.pyc
│ │ │ │ └── rpn_head.cpython-36.pyc
│ │ │ └── rpn_head.py
│ │ ├── detectors
│ │ │ ├── detector3d.py
│ │ │ ├── __init__.py
│ │ │ ├── pointpillar.py
│ │ │ └── __pycache__
│ │ │ ├── detector3d.cpython-36.pyc
│ │ │ ├── __init__.cpython-36.pyc
│ │ │ └── pointpillar.cpython-36.pyc
│ │ ├── __init__.py
│ │ ├── model_utils
│ │ │ ├── __init__.py
│ │ │ ├── __pycache__
│ │ │ │ ├── __init__.cpython-36.pyc
│ │ │ │ └── pytorch_utils.cpython-36.pyc
│ │ │ └── pytorch_utils.py
│ │ ├── __pycache__
│ │ │ └── __init__.cpython-36.pyc
│ │ ├── rpn
│ │ │ ├── pillar_scatter.py
│ │ │ └── __pycache__
│ │ │ └── pillar_scatter.cpython-36.pyc
│ │ └── vfe
│ │ ├── __init__.py
│ │ ├── __pycache__
│ │ │ ├── __init__.cpython-36.pyc
│ │ │ └── vfe_utils.cpython-36.pyc
│ │ └── vfe_utils.py
│ ├── ops
│ │ ├── iou3d_nms
│ │ │ ├── build
│ │ │ │ ├── lib.linux-x86_64-3.6
│ │ │ │ │ └── iou3d_nms_cuda.cpython-36m-x86_64-linux-gnu.so
│ │ │ │ └── temp.linux-x86_64-3.6
│ │ │ │ └── src
│ │ │ │ ├── iou3d_nms_kernel.o
│ │ │ │ └── iou3d_nms.o
│ │ │ ├── iou3d_nms_cuda.cpython-36m-x86_64-linux-gnu.so
│ │ │ ├── iou3d_nms.egg-info
│ │ │ │ ├── dependency_links.txt
│ │ │ │ ├── PKG-INFO
│ │ │ │ ├── SOURCES.txt
│ │ │ │ └── top_level.txt
│ │ │ ├── iou3d_nms_utils.py
│ │ │ ├── __pycache__
│ │ │ │ └── iou3d_nms_utils.cpython-36.pyc
│ │ │ ├── setup.py
│ │ │ └── src
│ │ │ ├── iou3d_nms.cpp
│ │ │ └── iou3d_nms_kernel.cu
│ │ └── roiaware_pool3d
│ │ ├── build
│ │ │ ├── lib.linux-x86_64-3.6
│ │ │ │ └── roiaware_pool3d_cuda.cpython-36m-x86_64-linux-gnu.so
│ │ │ └── temp.linux-x86_64-3.6
│ │ │ └── src
│ │ │ ├── roiaware_pool3d_kernel.o
│ │ │ └── roiaware_pool3d.o
│ │ ├── __pycache__
│ │ │ └── roiaware_pool3d_utils.cpython-36.pyc
│ │ ├── roiaware_pool3d_cuda.cpython-36m-x86_64-linux-gnu.so
│ │ ├── roiaware_pool3d.egg-info
│ │ │ ├── dependency_links.txt
│ │ │ ├── PKG-INFO
│ │ │ ├── SOURCES.txt
│ │ │ └── top_level.txt
│ │ ├── roiaware_pool3d_utils.py
│ │ ├── setup.py
│ │ └── src
│ │ ├── roiaware_pool3d.cpp
│ │ └── roiaware_pool3d_kernel.cu
│ ├── __pycache__
│ │ └── config.cpython-36.pyc
│ └── utils
│ ├── box_coder_utils.py
│ ├── box_utils.py
│ ├── common_utils.py
│ └── __pycache__
│ ├── box_coder_utils.cpython-36.pyc
│ ├── box_utils.cpython-36.pyc
│ └── common_utils.cpython-36.pyc
└── tools
├── pointpillar.pth
├── pointpillar.yaml
├── test.py
└── test.sh
下面给出PointPillars的网络结构,主要由3部分组成,网路结构相对也是比较简单的,这可能也是PointPillars为何是KITTI数据集上运算速度最快的原因。

下面是网络的具体结构:
PointPillar(
(vfe): PillarFeatureNetOld2(
(pfn_layers): ModuleList(
(0): PFNLayer(
(linear): Linear(in_features=10, out_features=64, bias=False)
(norm): BatchNorm1d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
)
)
)
(rpn_net): PointPillarsScatter()
(rpn_head): RPNV2(
(blocks): ModuleList(
(0): Sequential(
(0): ZeroPad2d(padding=(1, 1, 1, 1), value=0.0)
(1): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), bias=False)
(2): BatchNorm2d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(3): ReLU()
(4): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(5): BatchNorm2d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(6): ReLU()
(7): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(8): BatchNorm2d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(9): ReLU()
(10): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(11): BatchNorm2d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(12): ReLU()
)
(1): Sequential(
(0): ZeroPad2d(padding=(1, 1, 1, 1), value=0.0)
(1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), bias=False)
(2): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(3): ReLU()
(4): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(5): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(6): ReLU()
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(8): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(9): ReLU()
(10): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(11): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(12): ReLU()
(13): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(14): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(15): ReLU()
(16): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(17): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(18): ReLU()
)
(2): Sequential(
(0): ZeroPad2d(padding=(1, 1, 1, 1), value=0.0)
(1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), bias=False)
(2): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(3): ReLU()
(4): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(5): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(6): ReLU()
(7): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(8): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(9): ReLU()
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(11): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(12): ReLU()
(13): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(14): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(15): ReLU()
(16): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(17): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(18): ReLU()
)
)
(deblocks): ModuleList(
(0): Sequential(
(0): ConvTranspose2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU()
)
(1): Sequential(
(0): ConvTranspose2d(128, 128, kernel_size=(2, 2), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU()
)
(2): Sequential(
(0): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(4, 4), bias=False)
(1): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True)
(2): ReLU()
)
)
(conv_cls): Conv2d(384, 18, kernel_size=(1, 1), stride=(1, 1))
(conv_box): Conv2d(384, 42, kernel_size=(1, 1), stride=(1, 1))
(conv_dir_cls): Conv2d(384, 12, kernel_size=(1, 1), stride=(1, 1))
)
)
最后,我们看一下PointPillar.yaml配置文件,配置文件存储着网络具体参数,以及训练和测试参数,这在后面的代码编写时会多次用到:
CLASS_NAMES: ['Car', 'Pedestrian', 'Cyclist']
DATA_CONFIG:
DATASET: 'KittiDataset'
DATA_DIR: 'data'
FOV_POINTS_ONLY: True
NUM_POINT_FEATURES: {
'total': 4,
'use': 4
}
POINT_CLOUD_RANGE: [0, -39.68, -3, 69.12, 39.68, 1]
MASK_POINTS_BY_RANGE: True
TRAIN:
INFO_PATH: [
data/kitti_infos_train.pkl
]
SHUFFLE_POINTS: True
MAX_NUMBER_OF_VOXELS: 16000
TEST:
INFO_PATH: [
data/kitti_infos_val.pkl
]
SHUFFLE_POINTS: False
MAX_NUMBER_OF_VOXELS: 40000
AUGMENTATION:
NOISE_PER_OBJECT:
ENABLED: True
GT_LOC_NOISE_STD: [1.0, 1.0, 0.1]
GT_ROT_UNIFORM_NOISE: [-0.78539816, 0.78539816]
NOISE_GLOBAL_SCENE:
ENABLED: True
GLOBAL_ROT_UNIFORM_NOISE: [-0.78539816, 0.78539816]
GLOBAL_SCALING_UNIFORM_NOISE: [0.95, 1.05]
DB_SAMPLER:
ENABLED: True
DB_INFO_PATH: [
data/kitti/kitti_dbinfos_train.pkl
]
PREPARE:
filter_by_difficulty: [-1]
filter_by_min_points: ['Car:5', 'Pedestrian:5', 'Cyclist:5']
RATE: 1.0
SAMPLE_GROUPS: ['Car:15','Pedestrian:10', 'Cyclist:10']
USE_ROAD_PLANE: True
VOXEL_GENERATOR:
MAX_POINTS_PER_VOXEL: 32
VOXEL_SIZE: [0.16, 0.16, 4]
MODEL:
NAME: PointPillar
VFE:
NAME: PillarFeatureNetOld2
ARGS: {
'use_norm': True,
'num_filters': [64],
'with_distance': False,
}
RPN:
PARAMS_FIXED: False # DO NOT USE THIS
BACKBONE:
NAME: PointPillarsScatter
ARGS: {}
RPN_HEAD:
NAME: RPNV2
DOWNSAMPLE_FACTOR: 8
ARGS: {
'use_norm': True,
'concat_input': False,
'num_input_features': 64,
'layer_nums': [3, 5, 5],
'layer_strides': [2, 2, 2],
'num_filters': [64, 128, 256],
'upsample_strides': [1, 2, 4],
'num_upsample_filters': [128, 128, 128],
'encode_background_as_zeros': True,
'use_direction_classifier': True,
'num_direction_bins': 2,
'dir_offset': 0.78539,
'dir_limit_offset': 0.0,
'use_binary_dir_classifier': False
}
TARGET_CONFIG:
DOWNSAMPLED_FACTOR: 2
BOX_CODER: ResidualCoder
REGION_SIMILARITY_FN: nearest_iou_similarity
SAMPLE_POS_FRACTION: -1.0
SAMPLE_SIZE: 512
ANCHOR_GENERATOR: [
{'anchor_range': [0, -40.0, -1.78, 70.4, 40.0, -1.78],
'sizes': [[1.6, 3.9, 1.56]],
'rotations': [0, 1.57],
'matched_threshold': 0.6,
'unmatched_threshold': 0.45,
'class_name': 'Car'},
{'anchor_range': [0, -40, -0.6, 70.4, 40, -0.6],
'sizes': [[0.6, 0.8, 1.73]],
'rotations': [0, 1.57],
'matched_threshold': 0.5,
'unmatched_threshold': 0.35,
'class_name': 'Pedestrian'},
{'anchor_range': [0, -40, -0.6, 70.4, 40, -0.6],
'sizes': [[0.6, 1.76, 1.73]],
'rotations': [0, 1.57],
'matched_threshold': 0.5,
'unmatched_threshold': 0.35,
'class_name': 'Cyclist'},
]
RCNN:
ENABLED: False
LOSSES:
RPN_REG_LOSS: smooth-l1
LOSS_WEIGHTS: {
'rpn_cls_weight': 1.0,
'rpn_loc_weight': 2.0,
'rpn_dir_weight': 0.2,
'code_weights': [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
}
TRAIN:
SPLIT: train
OPTIMIZATION:
OPTIMIZER: adam_onecycle
LR: 0.003
WEIGHT_DECAY: 0.01
MOMENTUM: 0.9
MOMS: [0.95, 0.85]
PCT_START: 0.4
DIV_FACTOR: 10
DECAY_STEP_LIST: [35, 45]
LR_DECAY: 0.1
LR_CLIP: 0.0000001
LR_WARMUP: False
WARMUP_EPOCH: 1
GRAD_NORM_CLIP: 10
TEST:
SPLIT: val
NMS_TYPE: nms_gpu
MULTI_CLASSES_NMS: False
NMS_THRESH: 0.01
SCORE_THRESH: 0.1
USE_RAW_SCORE: True
NMS_PRE_MAXSIZE_LAST: 4096
NMS_POST_MAXSIZE_LAST: 500
RECALL_THRESH_LIST: [0.5, 0.7]
EVAL_METRIC: kitti
BOX_FILTER: {
'USE_IMAGE_AREA_FILTER': True,
'LIMIT_RANGE': [0, -40, -3.0, 70.4, 40, 3.0]
}
我们也可以看看本工程的代码量,总共有2280行代码,其中对于CUDA和C++部分,我们使用PCDet工程中提供的代码,将重点放在Python代码的编写部分。
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
Python 22 399 875 1183
CUDA 2 156 72 525
C++ 2 92 47 226
Markdown 1 34 0 199
YAML 1 26 0 146
Bourne Shell 1 0 0 1
-------------------------------------------------------------------------------
SUM: 29 707 994 2280
-------------------------------------------------------------------------------
总结:本文首先对3D目标检测研究现状进行了概述,然后介绍了PCDet3D目标检测库,最后对要实现的PointPillars工作原理及其工程进行了介绍。在下一篇文章中我们将开始从头编写代码,一步一步实现3D检测模型。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









