






一、任务价绍
- 使用结合W4A16量化与kv cache量化的
internlm2_5-7b-chat模型封装本地API并与大模型进行一次对话,作业截图需包括显存占用情况与大模型回复,参考4.1 API开发(优秀学员必做) - 使用Function call功能让大模型完成一次简单的"加"与"乘"函数调用,作业截图需包括大模型回复的工具调用情况,参考4.2 Function call(选做)
二、根据教程,搭建环境
Tutorial/docs/L2/LMDeploy/readme.md at camp3 · InternLM/Tutorial · GitHub
2.1、InternStudio环境获取模型
mkdir /root/models
ln -s /root/share/new_models//Shanghai_AI_Laboratory/internlm2_5-7b-chat /root/models
ln -s /root/share/new_models/OpenGVLab/InternVL2-26B /root/models
2.2、LMDeploy验证启动模型文件
lmdeploy chat /root/models/internlm2_5-7b-chat请帮我生成大禹治水的小故事

2.3、占显存说明

由上文可知InternLM2.5 7B模型为bf16,LMDpeloy推理精度为bf16的7B模型权重需要占用14GB显存;如下图所示,lmdeploy默认设置cache-max-entry-count为0.8,即kv cache占用剩余显存的80%;
此时对于24GB的显卡,即30%A100,权重占用14GB显存,剩余显存24-14=10GB,因此kv cache占用10GB*0.8=8GB,加上原来的权重14GB,总共占用14+8=22GB。
而对于40GB的显卡,即50%A100,权重占用14GB,剩余显存40-14=26GB,因此kv cache占用26GB*0.8=20.8GB,加上原来的权重14GB,总共占用34.8GB。
实际加载模型后,其他项也会占用部分显存,因此剩余显存比理论偏低,实际占用会略高于22GB和34.8GB。

此外,如果想要实现显存资源的监控,我们也可以新开一个终端输入如下两条指令的任意一条,查看命令输入时的显存占用情况。
nvidia-smi
studio-smi
注释:实验室提供的环境为虚拟化的显存,nvidia-smi是NVIDIA GPU驱动程序的一部分,用于显示NVIDIA GPU的当前状态,故当前环境只能看80GB单卡 A100 显存使用情况,无法观测虚拟化后30%或50%A100等的显存情况。针对于此,实验室提供了studio-smi 命令工具,能够观测到虚拟化后的显存使用情况。
三、LMDeploy与InternLM2.5
3.1 使用LMDeploy API部署,可以参考
书生大模型实战营--L1关卡-8G 显存玩转书生大模型 Demo CSDN
3.2 使用LMDeploy Lite进行部署
随着模型变得越来越大,我们需要一些大模型压缩技术来降低模型部署的成本,并提升模型的推理性能。LMDeploy 提供了权重量化和 k/v cache两种策略。
3.2.1 设置最大kv cache缓存大小
kv cache是一种缓存技术,通过存储键值对的形式来复用计算结果,以达到提高性能和降低内存消耗的目的。在大规模训练和推理中,kv cache可以显著减少重复计算量,从而提升模型的推理速度。理想情况下,kv cache全部存储于显存,以加快访存速度。
模型在运行时,占用的显存可大致分为三部分:模型参数本身占用的显存、kv cache占用的显存,以及中间运算结果占用的显存。LMDeploy的kv cache管理器可以通过设置--cache-max-entry-count参数,控制kv缓存占用剩余显存的最大比例。默认的比例为0.8。
首先我们先来回顾一下InternLM2.5正常运行时占用显存。

占用了23GB,那么试一试执行以下命令,再来观看占用显存情况。
lmdeploy chat /root/models/internlm2_5-7b-chat --cache-max-entry-count 0.4
稍待片刻,观测显存占用情况,可以看到减少了约4GB的显存。

让我们计算一下4GB显存的减少缘何而来,
对于修改kv cache默认占用之前,即如2.2 LMDeploy验证启动模型文件所示直接启动模型的显存占用情况(23GB):
1、在 BF16 精度下,7B模型权重占用14GB:70×10^9 parameters×2 Bytes/parameter=14GB
2、kv cache占用8GB:剩余显存24-14=10GB,kv cache默认占用80%,即10*0.8=8GB
3、其他项1GB
是故23GB=权重占用14GB+kv cache占用8GB+其它项1GB
对于修改kv cache占用之后的显存占用情况(19GB):
1、与上述声明一致,在 BF16 精度下,7B模型权重占用14GB
2、kv cache占用4GB:剩余显存24-14=10GB,kv cache修改为占用40%,即10*0.4=4GB
3、其他项1GB
是故19GB=权重占用14GB+kv cache占用4GB+其它项1GB
而此刻减少的4GB显存占用就是从10GB*0.8-10GB*0.4=4GB,这里计算得来
3.2.2 设置在线 kv cache int4/int8 量化
自 v0.4.0 起,LMDeploy 支持在线 kv cache int4/int8 量化,量化方式为 per-head per-token 的非对称量化。此外,通过 LMDeploy 应用 kv 量化非常简单,只需要设定 quant_policy 和cache-max-entry-count参数。目前,LMDeploy 规定 qant_policy=4 表示 kv int4 量化,quant_policy=8 表示 kv int8 量化。
我们通过3.1 LMDeploy API部署InternLM2.5的实践为例,输入以下指令,启动API服务器
lmdeploy serve api_server \
/root/models/internlm2_5-7b-chat \
--model-format hf \
--quant-policy 4 \
--cache-max-entry-count 0.4\
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
稍待片刻,显示如下即代表服务启动成功。

设置缓存,api部署的结果和hf部署的结果是一致的,显存占用19G

由于都使用BF16精度下的internlm2.5 7B模型,故剩余显存均为10GB,且 cache-max-entry-count 均为0.4,这意味着LMDeploy将分配40%的剩余显存用于kv cache,即10GB*0.4=4GB。但quant-policy 设置为4时,意味着使用int4精度进行量化。因此,LMDeploy将会使用int4精度提前开辟4GB的kv cache。
相比使用BF16精度的kv cache,int4的Cache可以在相同4GB的显存下只需要4位来存储一个数值,而BF16需要16位。这意味着int4的Cache可以存储的元素数量是BF16的四倍。
3.2.3 W4A16 模型量化和部署
准确说,模型量化是一种优化技术,旨在减少机器学习模型的大小并提高其推理速度。量化通过将模型的权重和激活从高精度(如16位浮点数)转换为低精度(如8位整数、4位整数、甚至二值网络)来实现。
那么标题中的W4A16又是什么意思呢?
- W4:这通常表示权重量化为4位整数(int4)。这意味着模型中的权重参数将从它们原始的浮点表示(例如FP32、BF16或FP16,Internlm2.5精度为BF16)转换为4位的整数表示。这样做可以显著减少模型的大小。
- A16:这表示激活(或输入/输出)仍然保持在16位浮点数(例如FP16或BF16)。激活是在神经网络中传播的数据,通常在每层运算之后产生。
因此,W4A16的量化配置意味着:
- 权重被量化为4位整数。
- 激活保持为16位浮点数。
让我们回到LMDeploy,在最新的版本中,LMDeploy使用的是AWQ算法,能够实现模型的4bit权重量化。输入以下指令,执行量化工作。(本步骤耗时较长,请耐心等待)
lmdeploy lite auto_awq \
/root/models/internlm2_5-7b-chat \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 2048 \
--w-bits 4 \
--w-group-size 128 \
--batch-size 1 \
--search-scale False \
--work-dir /root/models/internlm2_5-7b-chat-w4a16-4bit
命令解释:
lmdeploy lite auto_awq:lite这是LMDeploy的命令,用于启动量化过程,而auto_awq代表自动权重量化(auto-weight-quantization)。/root/models/internlm2_5-7b-chat: 模型文件的路径。--calib-dataset 'ptb': 这个参数指定了一个校准数据集,这里使用的是’ptb’(Penn Treebank,一个常用的语言模型数据集)。--calib-samples 128: 这指定了用于校准的样本数量—128个样本--calib-seqlen 2048: 这指定了校准过程中使用的序列长度—1024--w-bits 4: 这表示权重(weights)的位数将被量化为4位。--work-dir /root/models/internlm2_5-7b-chat-w4a16-4bit: 这是工作目录的路径,用于存储量化后的模型和中间结果。
等终端输出如下时,说明正在推理中,稍待片刻。

等待推理完成,便可以直接在你设置的目标文件夹看到对应的模型文件。
那么推理后的模型和原本的模型区别在哪里呢?最明显的两点是模型文件大小以及占据显存大小。
我们可以输入如下指令查看在当前目录中显示所有子目录的大小。

原文件大小:

一经对比即可发觉,15G对4.9G,优势在我。
那么显存占用情况对比呢?输入以下指令启动量化后的模型。
lmdeploy chat /root/models/internlm2_5-7b-chat-w4a16-4bit/ --model-format awq
稍待片刻,我们直接观测右上角的显存占用情况。

可以发现,相比较于原先的23GB显存占用,W4A16量化后的模型少了约2GB的显存占用。
让我们计算一下2GB显存的减少缘何而来。
对于W4A16量化之前,即如LMDeploy验证启动模型文件所示直接启动模型的显存占用情况(23GB):
1、在 BF16 精度下,7B模型权重占用14GB:70×10^9 parameters×2 Bytes/parameter=14GB
2、kv cache占用8GB:剩余显存24-14=10GB,kv cache默认占用80%,即10*0.8=8GB
3、其他项1GB
是故23GB=权重占用14GB+kv cache占用8GB+其它项1GB
而对于W4A16量化之后的显存占用情况(20.9GB):
1、在 int4 精度下,7B模型权重占用3.5GB:14/4=3.5GB
注释:
bfloat16是16位的浮点数格式,占用2字节(16位)的存储空间。int4是4位的整数格式,占用0.5字节(4位)的存储空间。因此,从bfloat16到int4的转换理论上可以将模型权重的大小减少到原来的1/4,即7B个int4参数仅占用3.5GB的显存。
2、kv cache占用16.4GB:剩余显存24-3.5=20.5GB,kv cache默认占用80%,即20.5*0.8=16.4GB
3、其他项1GB
是故20.9GB=权重占用3.5GB+kv cache占用16.4GB+其它项1GB
3.2.4 W4A16 量化+ KV cache+KV cache 量化
输入以下指令,让我们同时启用量化后的模型、设定kv cache占用和kv cache int4量化。
lmdeploy serve api_server \
/root/models/internlm2_5-7b-chat-w4a16-4bit/ \
--model-format awq \
--quant-policy 4 \
--cache-max-entry-count 0.4\
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
此时显存占用13.9GB。

点击显示/隐藏显存占用情况的计算细节让我们来计算一下此刻的显存占用情况(13.9GB):
1、在 int4 精度下,7B模型权重占用3.5GB:14/4=3.5GB
2、kv cache占用16.4GB:剩余显存24-3.5=20.5GB,kv cache占用40%,即20.5*0.4=8.2GB
3、其他项2.2GB
是故13.9GB=权重占用3.5GB+kv cache占用8.2GB+其它项2.2GB
想要更极限且保证正常工作的量化设置的话,各位小伙伴可以之后自行探索,本次实践教学便止步于此了。
四、LMDeploy与InternVL2
本次实践选用InternVL2-26B进行演示,其实就根本来说作为一款VLM和上述的InternLM2.5在操作上并无本质区别,仅是多出了"图片输入"这一额外步骤,但作为量化部署进阶实践,选用InternVL2-26B目的是带领大家体验一下LMDeploy的量化部署可以做到何种程度。
4.1 LMDeploy Lite
InternVL2-26B需要约70+GB显存,但是为了让我们能够在30%A100上运行,需要先进行量化操作,这也是量化本身的意义所在——即降低模型部署成本。
4.1.1 W4A16 模型量化和部署
针对InternVL系列模型,让我们先进入conda环境,并输入以下指令,执行模型的量化工作。(本步骤耗时较长,请耐心等待)
conda activate lmdeploy
lmdeploy lite auto_awq \
/root/models/InternVL2-26B \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 2048 \
--w-bits 4 \
--w-group-size 128 \
--batch-size 1 \
--search-scale False \
--work-dir /root/models/InternVL2-26B-w4a16-4bit
等终端输出如下时,说明正在推理中,稍待片刻。

4.1.2 W4A16 量化+ KV cache+KV cache 量化
输入以下指令,让我们启用量化后的模型。
lmdeploy serve api_server \
/root/models/InternVL2-26B-w4a16-4bit \
--model-format awq \
--quant-policy 4 \
--cache-max-entry-count 0.1\
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
启动后观测显存占用情况,此时只需要约23.8GB的显存,已经是一张30%A100即可部署的模型了。

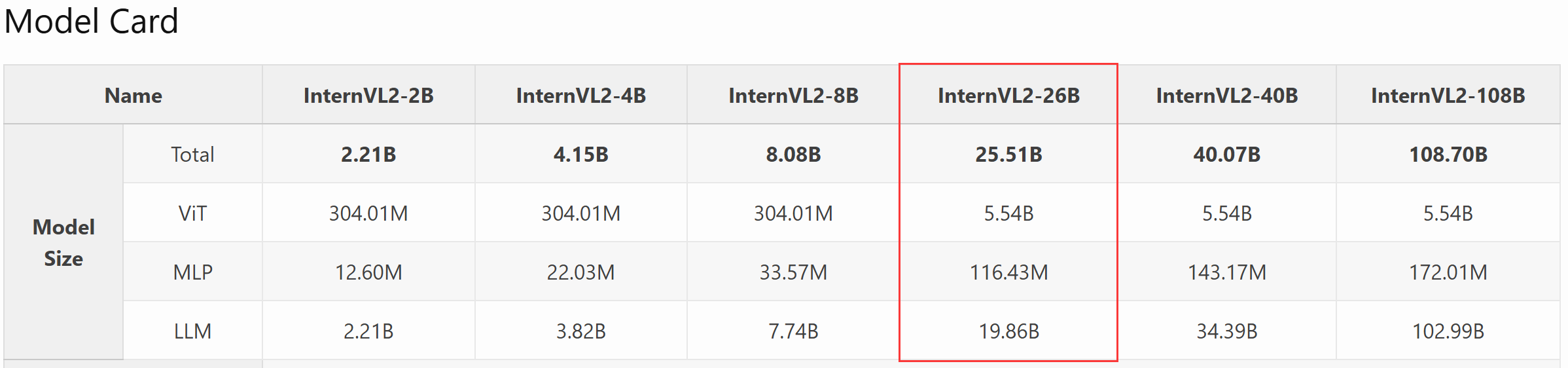
根据InternVL2介绍,InternVL2 26B是由一个6B的ViT、一个100M的MLP以及一个19.86B的internlm组成的。
4.2 LMDeploy API部署InternVL2
具体封装操作与之前大同小异,仅仅在数个指令细节上作调整,故本章节大部分操作与LMDeploy API部署InternLM2.5中几近完全一样,同学们可自行"依葫芦画瓢",以下教程仅做参考。
通过以下命令启动API服务器,部署InternVL2模型
lmdeploy serve api_server \
/root/models/InternVL2-26B-w4a16-4bit/ \
--model-format awq \
--quant-policy 4 \
--cache-max-entry-count 0.6 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
以下为Gradio网页形式连接成功后对话截图。

五、LMDeploy之FastAPI与Function call
之前在启动API服务器与LMDeploy API部署InternVL2均是借助FastAPI封装一个API出来让LMDeploy自行进行访问,在这一章节中我们将依托于LMDeploy封装出来的API进行更加灵活更具DIY的开发。
5.1 API开发
conda activate lmdeploy
lmdeploy serve api_server \
/root/models/internlm2_5-7b-chat-w4a16-4bit \
--model-format awq \
--cache-max-entry-count 0.4 \
--quant-policy 4 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
测试API

5.2 Function call
关于Function call,即函数调用功能,它允许开发者在调用模型时,详细说明函数的作用,并使模型能够智能地根据用户的提问来输入参数并执行函数。完成调用后,模型会将函数的输出结果作为回答用户问题的依据。
首先让我们进入创建好的conda环境并启动API服务器。
lmdeploy serve api_server \
/root/models/internlm2_5-7b-chat \
--model-format hf \
--quant-policy 0 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1目前LMDeploy在0.5.3版本中支持了对InternLM2, InternLM2.5和llama3.1这三个模型,故我们选用InternLM2.5 封装API。
让我们使用一个简单的例子作为演示。输入如下指令,新建internlm2_5_func.py。
测试1、


测试2、
















 735
735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









