







目录
在大数据和人工智能席卷全球的今天,我们的生活几乎被各种数据包围。大家都知道数据很重要,但有一种数据却常常被大家忽视,它就像是隐身在幕后,但却掌控全局的“数据超人”——它就是向量数据。向量数据是什么?向量数据库顾名思义就是存储向量的,它又有什么作用?今天我们就走进向量数据的世界,看看它到底是什么,能做些什么,为什么它在当今的人工智能时代如此重要。

如果你想学习Deepseek从入门到精通,一小时掌握,零基础本地部署+AI训练+私有化知识库部署,下面的视频或许会对你有所帮助
什么是向量?
首先,我们得搞清楚什么是向量。其实向量这个词并不复杂,别被数学课上的那些公式吓到了。简单来说,向量是一种可以表示方向和大小的数据结构。它可以是二维、三维,甚至是多维的。比如,我们在地图上定位一个位置,需要经纬度,这就是一个二维向量。而如果你在太空中飞行,那就得加上高度,变成三维向量。
然而,在计算机世界中,我们可以创建任意多维度的向量。比如,当你在看一部电影的时候,某个推荐算法可能会把电影的各种特征(如类型、演员、评分等)转换成一个高维向量。这个向量代表了电影的特性,让机器能更好地理解它。这种高维向量被用来进行各种运算、匹配,最终推荐给你最合适的内容。
什么是向量数据
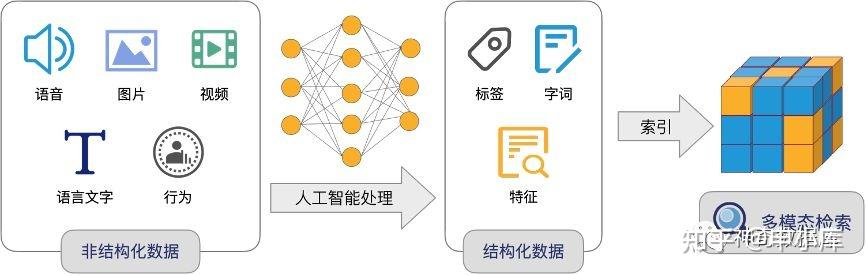
向量数据是一种数学表示,用一组有序的数值(通常是浮点数)表示一个对象或数据点。向量通常用于在多维空间中表示数据点的位置、特征或属性。
[0.12, 0.32, -0.5]在计算机视觉中,图像可以通过一组数值(即像素值)表示,这组数值构成一个向量。每个数值对应于图像中一个像素的颜色强度。例如,一个 8x8 的灰度图像可以表示为一个包含 64 个数值的向量。

在推荐系统中,用户和物品可以用向量表示,以捕捉其特征和属性。例如,用户可能对电影类型、导演、演员等方面有偏好,这些偏好可以用一个数值向量表示。通过计算用户向量与物品向量之间的相似度,可以实现个性化的推荐。
在自然语言处理中,词嵌入是一种将文本数据转换为向量数据的方法。例如,使用 Word2Vec 或 GloVe 算法,可以将单词表示为一个包含多个数值的向量。这些数值捕捉了单词的语义特征,使得相似含义的单词在向量空间中彼此靠近。
示例:假设有两个句子:
"这部电影很好看,值得一看。"
"这是一部非常精彩的电影,推荐观看。"将这两个句子转换为向量表示后,计算它们之间的余弦相似度。如果相似度较高,说明两句子在语义上相似;如果相似度较低,说明它们在语义上不相似。
从数学的角度看,向量是一个“有方向和大小的东西”,可以用数字坐标来描述。在计算机世界中,我们可以把向量简单地理解为一组“有意义的数字”,用来表示事物的特征。
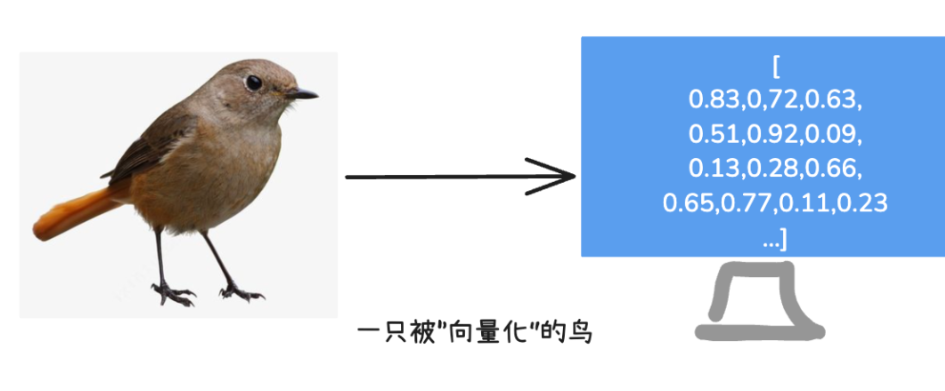
比如,我们要描述一只鸟,可以说:
“它有红色羽毛。它会唱歌。它的大小和手掌差不多。”
这些信息就可以被转化成向量,比如:
[红色: 0.913, 唱歌: 0.823, 大小: 0.534]
每个数字代表一项特性,这样鸟的特性就被数字化了。
无论是鸟、图片还是一句话,都可以用向量来描述。这种“通用的数字化语言”让计算机能理解复杂事物,也更利于AI中复杂的算法进行处理。
向量数据是什么?
要理解向量数据,得先从它的技术原理讲起。向量数据通常是数值化的,这意味着它们被表示为一组数字。
向量数据的结构
向量数据的典型结构是一个一维数组,其中的元素是数值(通常是浮点数)。这些数值表示对象或数据点在多维空间中的位置、特征或属性。向量数据的长度取决于所表示的特征维度。下面是一个简单的例子:
假设我们有三个水果:苹果、香蕉和葡萄。我们想用向量数据表示它们的颜色和大小特征。我们可以将颜色分为红、绿、蓝三个通道,将大小分为小、中、大三个类别。因此,我们可以用一个包含 6 个数值的向量表示每个水果的特征。
苹果(红色,中等大小):[1, 0, 0, 0, 1, 0]
香蕉(黄色,大):[0, 1, 0, 0, 0, 1]
葡萄(紫色,小):[0.5, 0, 0.5, 1, 0, 0]
在这个例子中,每个水果都被表示为一个 6 维向量。前三个数值表示颜色信息(红、绿、蓝通道),后三个数值表示大小信息(小、中、大)。
细心的你可能会发现,紫色的向量表示是 [0.5, 0, 0.5],没错,这代表紫色是由红色和蓝色组成。
这种数组结构是典型的向量数据表示。
向量数据的计算
有了向量数据,怎么用呢?这里面有没有一些通用的计算模式?
向量数据的结构非常简单,但针对不同的场景,衍生出了多种计算方法。
比如最常见的有向量相似度计算:衡量两个向量之间的相似程度。常用的相似度度量方法包括余弦相似度、欧几里得距离、曼哈顿距离等。
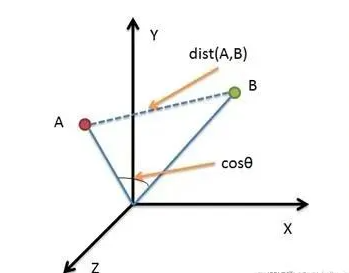
这种计算模式非常普及,在推荐系统中评估用户和物品的相似度,以及在自然语言处理中评估文本或单词的相似度时非常有用。
其他计算模式,还包括加权平均、向量内积、外积、矩阵乘法、池化、归一化等等,这里就不再一一赘述了。
每一种计算模式,都可以映射到数学理论中关于向量、矩阵运算,而背后的应用场景大多集中在计算机视觉、图像处理、文本处理、自然语言处理、神经网络等多模型通用人工智能领域。
向量数据的技术原理
要理解向量数据,得先从它的技术原理讲起。向量数据通常是数值化的,这意味着它们被表示为一组数字。例如,在自然语言处理(NLP)中,一个词可以被表示为一个300维的向量。每个数字代表这个词在一个特定语境下的某种特征。这种方法被称为词向量(Word Embedding)。
01、词向量
词向量是如何生成的呢?最经典的方法之一是Word2Vec,这是一种神经网络模型,可以学习词与词之间的关系。举个例子,它能够明白“国王”与“王后”的关系类似于“男人”与“女人”的关系。通过这种训练,模型能够把每个词映射到一个多维空间中,并用一个向量表示它们的意义。
如果我们每个词都是一位客人,那词向量就像是给每位客人一个身份证号,只不过这个身份证号不只是一个数字,而是一组数字。这组数字能帮我们把“词”的特点和它们之间的关系记录下来。
词向量是通过一种叫做“分布式表示”的方法,将每一个单词用一个向量(其实就是一个包含多维数值的列表)表示出来的。这样,我们可以用数学的方法来计算单词之间的关系。
比如:
有三个单词:”国王”、“王后”和“男人”。通过词向量,我们可以把这些词放到一个“空间”里,空间中的位置代表词语的意义。我们发现,“国王”和“王后”之间的差异(比如性别)其实和“男人”和“女人”之间的差异很类似。也就是说,如果我们用向量来表示这些单词的话:
“国王” = [0.7, 0.2, 0.9, ...]
“王后” = [0.6, 0.2, 0.8, ...]
“男人” = [0.5, 0.1, 0.9, ...]
“女人” = [0.4, 0.1, 0.8, ...]
那么我们可以发现,“国王” 减去 “男人” 的向量,跟 “王后” 减去 “女人” 的向量差不多——这就反映了“性别”这个关系。
如果用数学公式来写的话:
词向量(国王) - 词向量(男人) ≈ 词向量(王后) - 词向量(女人)
词向量就是把每个单词用一串数字表示出来,这样我们就可以用数学的方法来计算单词之间的相似度、关系等等。它的好处是,能让机器更好地理解我们人类的语言之间的那些微妙关系,哪怕这些关系很复杂。通过词向量,计算机不仅能知道“国王”和“王后”是近亲,还能知道“男人”与“女人”的关系有些类似。
02、词嵌入
这就像是在一个高维度的宇宙中,我们把每个词、每个概念都变成了宇宙中的一个星星。相似的星星会彼此靠近,而不相关的则会远离。比如,“猫”与“狗”之间的向量距离就比“猫”与“飞机”要近得多。
词向量就是把每个单词用一串数字表示出来,这样我们就可以用数学的方法来计算单词之间的相似度、关系等等。它的好处是,能让机器更好地理解我们人类的语言之间的那些微妙关系,哪怕这些关系很复杂。通过词向量,计算机不仅能知词嵌入(Word Embedding)其实是“词向量”的一种实现方式。它是把单词映射到一个高维的数学空间中,用一个向量来表示每个单词,就好像给每个单词分配了一个坐标。这种方法让机器可以用数学的方式去理解和处理语言。
这么说可能有点抽象,我们换种方式:
词嵌入就像是给每个单词找了一个“家”,这些“家”都住在一个巨大的多维空间里。在这个空间里,意思相近的单词就住得很近,比如“猫”和“狗”可能是邻居,因为它们都是宠物,而“飞机”住得远一些,因为它属于交通工具的范畴。
我们来举个例子,让它更容易理解:
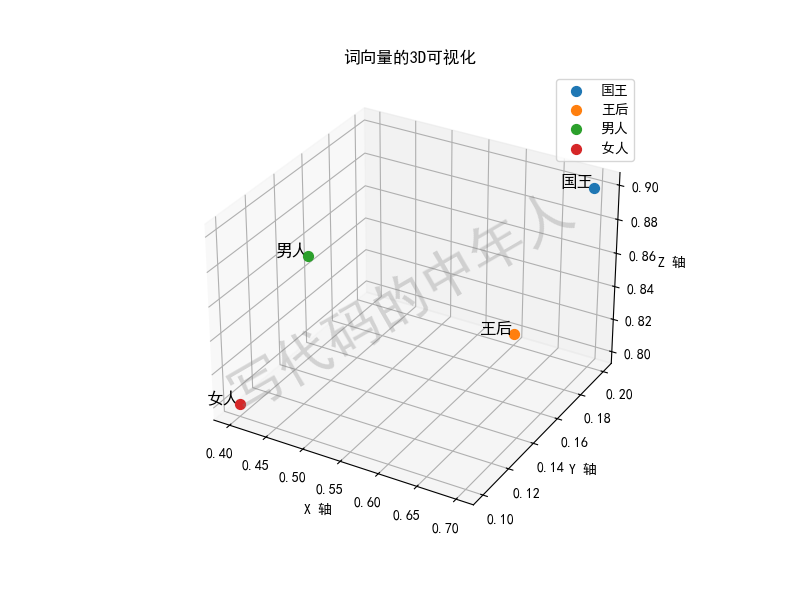
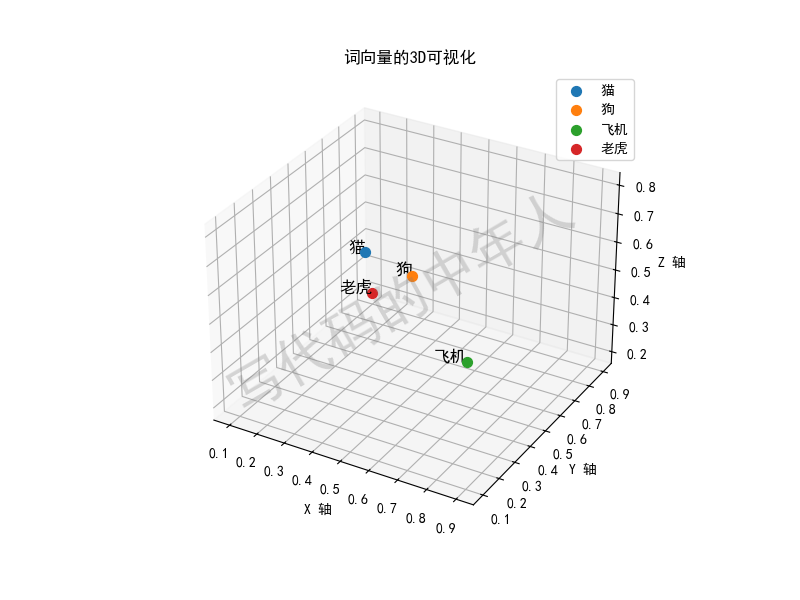
假设我们有以下几个词:“猫”、“狗”、“飞机”、“老虎”。我们用词嵌入的方法,把它们分别映射到一个三维空间(就像给每个词分配一个三维坐标):
“猫” = [0.5, 0.2, 0.8]
“狗” = [0.6, 0.3, 0.7]
“飞机” = [0.9, 0.1, 0.6]
“老虎” = [0.1, 0.9, 0.2]
在这个空间中,你可以看到“猫”和“狗”的坐标很接近,表示它们的意思也很接近。而“飞机”则离它们比较远,因为它们的含义差别很大。
03、向量距离与相似度
说到这里,我们就必须提到向量的另一个重要概念——向量距离。通过计算两个向量之间的距离,我们可以知道它们有多相似。最常用的方法之一是余弦相似度,它通过计算两个向量之间的夹角余弦值来评估它们的相似度。
如果两个向量的方向几乎一致,那么余弦相似度接近1,它们就很相似。反之,如果夹角接近90度(余弦值接近0),那么它们就几乎不相干。这种方法在推荐系统、图像识别、自然语言处理等领域中都有广泛应用。
04、向量距离和相似度是什么?
向量距离和相似度是用来衡量两个向量(比如词向量)之间的关系的。它们可以帮助我们判断两个单词在语义上有多相近或者多不同。
1. 向量距离:
向量距离可以理解为两个向量(两个词在向量空间中的位置)之间的“距离”。如果距离很短,那这两个向量代表的词语意思很相近;距离很长,则表示它们的意思相差很大。
2. 相似度:
相似度是用来衡量两个向量在多大程度上“朝向”同一个方向。它不关心两个向量之间的实际距离,而是看它们的方向是否一致。相似度通常用“余弦相似度”来衡量。
比如:
词向量的世界就像是一个地图。我们把猫、狗、飞机放在这个地图上:
猫和狗住得很近,它们在这个地图上的距离也很短;
猫和飞机之间的距离就很远。
这样,我们就可以说猫和狗之间的向量距离小,相似度高;而猫和飞机的距离大,相似度低。
向量距离的几种常用方法
欧氏距离(Euclidean Distance):
这是我们生活中最常见的距离概念。假如猫在坐标(1, 2),狗在坐标(2, 3),那么欧氏距离就是根据两点之间的直线距离计算出来的。距离越小,表示它们在语义上越接近。
曼哈顿距离(Manhattan Distance):
如果你在一座城市的街区之间穿行,那么你只能沿着街道直角行走,这就是曼哈顿距离的计算方式。它是计算两个向量之间横向和纵向距离的总和。
相似度的计算方法:余弦相似度
余弦相似度是用来衡量两个向量在多大程度上“朝着”同一个方向的。它计算的是向量之间夹角的余弦值。
如果两个向量的方向完全一致,那么余弦相似度就是1(表示完全相同)。
如果它们的方向完全相反,余弦相似度就是-1(表示完全不相同)。
如果它们的方向垂直,余弦相似度就是0(表示没有相似性)。
举个具体的例子:
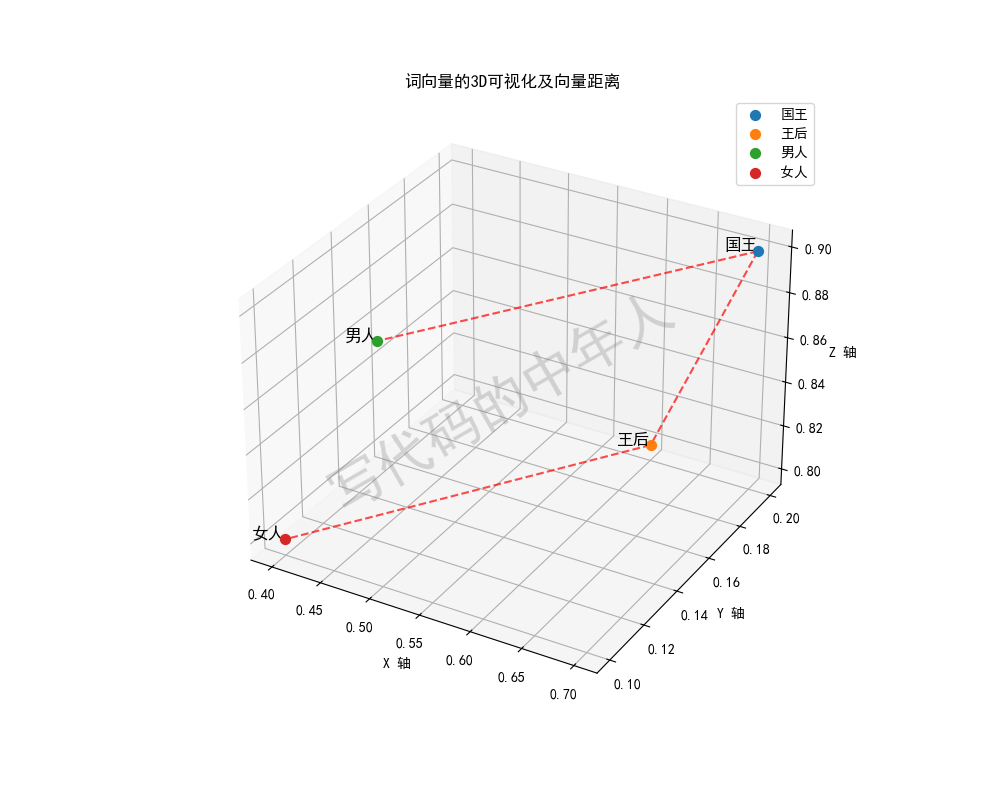
假如国王和王后的向量在一个多维空间中,它们的向量可能有这样的值:
“国王” = [0.5, 0.2, 0.9]
“王后” = [0.5, 0.3, 0.8]
我们可以用余弦相似度来计算它们之间的相似性。因为这两个词表示的含义比较相近,所以它们的余弦相似度会接近1。
向量距离:表示两个词之间的“远近”关系,距离越小,表示它们的意思越接近。
相似度:表示两个词在“朝向”上的一致性,用余弦相似度来计算时,值越接近1,表示它们越相似。
向量的存储
向量数据库
什么是向量数据库?
我们每天都会产生海量的数据,比如图片、视频、文本等等。传统的数据库在存储这些数据时,主要依赖于结构化数据的方式,就像是把每个物品放在一个有标签的盒子里。可是,当我们遇到一些复杂的数据,比如图像或自然语言文本时,这种方法就显得有些捉襟见肘了。
这时,向量数据库便应运而生!简单来说,向量数据库是专门为存储和检索高维数据(即向量)而设计的。它能将复杂的数据转换为向量表示,然后进行高效的存储和检索。
向量数据库的工作原理?
向量数据库的工作原理很简单。首先,它会将数据转换为向量表示(通过深度学习模型等技术),然后将这些向量存储在数据库中。当我们需要检索某个数据时,数据库会计算这个数据向量与存储向量之间的相似度(通常使用余弦相似度或欧氏距离等方法),最后返回最相似的结果。
一些流行的向量数据库包括:
FAISS(Facebook AI Similarity Search):高效的向量相似性搜索库,适用于大规模数据集。
Milvus:一个开源的、高性能的向量数据库,支持深度学习应用。
Pinecone:一个托管的向量数据库服务,专注于易于使用和高性能的向量搜索。
AI Agent 与向量数据库
AI Agent 和向量数据库之间的关系非常紧密,尤其是在构建和使用现代 AI 系统时。向量数据库在处理和存储高维向量的过程中,能够帮助 AI Agent 实现高效的数据搜索、匹配和分析。
1. 向量数据库的作用
存储高维向量:向量数据库专门设计用于存储和检索高维向量数据。对于 AI Agent 而言,当处理诸如文本、图像、音频等非结构化数据时,这些数据会被转化为高维向量表示(embedding)。
快速相似度搜索:向量数据库能够对高维向量执行高效的近似最近邻(ANN,Approximate Nearest Neighbor)搜索,使得 AI Agent 可以在大规模数据集中快速找到与输入向量最相似的项。这样可以加速推荐、问答系统以及其他需要相似性搜索的场景。
2. AI Agent 如何利用向量数据库
Embedding 生成与存储:AI Agent 可以使用深度学习模型(如 BERT、CLIP、DALL-E)将输入数据(如文本、图像)转化为嵌入向量(embedding),并将这些嵌入向量存储在向量数据库中。
语义检索:当用户提出查询时,AI Agent 会将查询转化为向量,并在向量数据库中进行相似度检索,以找到与查询最相关的条目。这适用于搜索引擎、问答系统、个性化推荐等。
知识存储与推理:AI Agent 可以将从文档、知识库中提取的特征向量存入向量数据库。随后,AI Agent 可以利用这些向量数据进行语义匹配,从而在需要时进行知识调用和推理。
支持向量数据的数据库
ChatGPT被誉为 AGI 领域的『iPhone时刻』,越来越多人关注自然语言处理与通用人工智能在自己领域内的应用。
向量是 AI 世界对世间万物的表示形式,随着大模型等AI技术的发展和普及,向量数据的存算需求一定会得到极大的释放。
现阶段,大量的向量数据可能还散落在各种文件中,并没有使用标准的向量数据库去存。
但未来,专业的事一定是要交给专业的人。有严谨的数学理论支撑的向量数据,也一定会逐渐下沉到标准的专业的向量数据库中,这样才能使得整个社会的IT成本更低,效率更高。
回顾过去,从2019年开始,一些通用的数据库,开始增加对向量数据库的支持,比如ElasticSearch、Redis、PostgreSQL。
Elasticsearch 本身是一个分布式全文搜索和分析引擎,但增加支持了dense_vector数据类型来存储稠密向量。通过使用内置的向量函数,如cosineSimilarity、dotProduct和l2norm等,可以实现一些基本的向量计算。
Redis 可通过一些扩展模块,如RedisAI和RediSearch,实现一定程度的向量数据处理和计算功能。RedisAI 偏深度学习模型,支持TensorFlow、PyTorch和ONNX运行时。RediSearch 偏全文检索,支持一些基本的文本相似度度量,如TF-IDF和Levenshtein距离等。
向量的应用
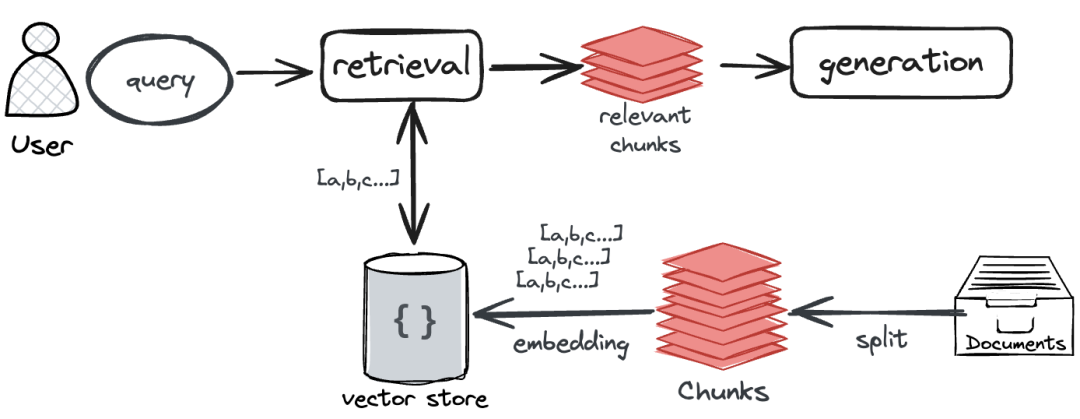
由于RAG应用是一种“边查边答”的应用,比如你问RAG应用:“C-RAG的基本原理是什么” 它需要检索出相关的资料段落(比如C-RAG论文),然后根据这些资料生成答案。
这时候,向量派上了用场:
首先把知识库里的文档分段转化成向量。 比如:
段落1:[0.1, 0.7, 0.2]
段落2:[0.9, 0.1, 0.4]
段落3:[0.3, 0.8, 0.2]
然后,把问题“C-RAG的基本原理是什么”转化成一个向量。 比如:
[0.2, 0.8, 0.1] (只是示例,真实的向量通常是几百甚至几千维的)。
接着,比较它与段落向量之间的“距离”(比如余弦相似度)。 模型就能判断哪个段落最相关。
最后,大模型就可以使用最相关的段落来回答问题。
好比你在图书馆找书时,根据书的分类和关键词找到了最合适的参考书。而RAG本质上不就是“看着参考书回答问题”吗?
当然,除了在RAG应用中外,向量其实是贯穿整个大模型推理过程的重要角色。在大模型的推理计算过程中,输入输出其实都是以向量形式来进行的。毕竟,数值计算才是计算机擅长的工作。
写在最后
向量有没有不足?
虽然向量很强大,但它也有一些不足:
高维计算成本高
向量通常是几百甚至几千维,计算相似性需要大量资源。
向量表达可能有误差
如果嵌入模型不好,生成的向量可能无法准确表达数据的特性。
向量数据库存储要求高
存储数百万甚至数十亿个高维向量,需要优化存储和检索效率。
向量是现代人工智能的核心工具,用数字化方式描述数据特性,让计算机能够理解和比较复杂信息。从大模型的推理到 RAG 技术的应用,向量技术无处不在,希望这篇文章让你对向量有了更加清晰的认识。
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
祝愿同学们未来前程似锦!!!



















 1164
1164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











