







1. CH2-kNN(1)
2. CH2-kNN(2)
3. CH2-kNN(3)
4. CH3-决策树(1)
5. CH3-决策树(2)
6. CH3-决策树(3)
7. CH4-朴素贝叶斯(1)
8. CH4-朴素贝叶斯(2)
9. CH5-Logistic回归(1)
10. CH5-Logistic回归(2)
======== No More ========
这一篇是两个朴素贝叶斯的实例。分别是:
(1)过滤垃圾邮件
(2)从个人广告中获取区域倾向
----------------------------------------------------------------------------------------------------------------------------------------
实例:使用朴素贝叶斯过滤垃圾邮件
总的来说,就是拿到文本后,首先进行分词(切分文本),形成词向量。然后调用上一篇博客里的trainNB0(),来训练样本。利用classifyNB()函数,以及一个新写的测试函数,来测试分类器。
上篇博客里简单提到了“分词”。我们的例子的英文的文本,分词比较容易。但是仍然会有一些问题,比如我们想把标点符号、空字符串给去掉。另外,我们想把字母通通转换为大写/小写,以便后来的统计。
我们可以用正则表达式(regular expression,简称regex)来匹配各种字符串模式。python里面有个包,叫做re,提供了各种正则表达式匹配、搜索、替换的API,用起来很方便。正则表达式的写法、re这个包的用法都可以在这篇东西里找到,觉得挺不错的。
假如我们现在有一个字符串,str = 'This book is the best book on Python or M.L I have ever liad eyes upon.' 然后要去标点、去空格、全变小写。
def textParse(bigString):
import re
listOfTokens = re.split(r'\W*', bigString)
return [tok.lower() for tok in listOfTokens if len(tok) > 0]就可以用这个函数。\W 表示非单词字符,就是除了26个字母和10个阿拉伯数字之外的字符。*表示0或多个。re.split(r'\W*', bigString)意思就是在所有连续的非单词字符组成的字符串处,把bigString“切分开”,就是其间不论有多少空格、换行符什么,通通一刀切。然后过滤掉单词长度为0的字符串(空串),再把所有字母变成小写。

好,现在我们开始对一封封的邮件下手。
首先上面那个代码改动一小点:因为各种原因,我们把长度小于3的字符串去掉。
然后我们看下数据集。有两个文件夹,一个叫“ham”,包含了25封平常的邮件;另一个叫“spam”,包含了各种25封垃圾邮件。我们选一封spam来看一下:

妥妥的就是一推销的啊!
上代码。
def textParse(bigString):
import re
listOfTokens = re.split(r'\W*', bigString)
return [tok.lower() for tok in listOfTokens if len(tok) > 2] #这里改动了字符串长度下限
def spamTest():
docList=[]; classList = []; fullText =[]
for i in range(1,26):
#读取垃圾邮件
wordList = textParse(open('email/spam/%d.txt' % i).read()) #把每封邮件中的内容转成字符串,然后拆分成单词装入List
docList.append(wordList)
classList.append(1) #垃圾邮件的标签是1
#读取正常邮件
wordList = textParse(open('email/ham/%d.txt' % i).read())
docList.append(wordList)
classList.append(0) #正常邮件的标签是0
vocabList = createVocabList(docList) #创建词汇表
trainingSet = range(50); #训练集
testSet=[] #测试集
# 随机从训练集中的50条数据中选取10条作为测试集
for i in range(10):
randIndex = int(random.uniform(0, len(trainingSet)))
testSet.append(trainingSet[randIndex])
del(trainingSet[randIndex])
trainMat=[]; trainClasses = [] #训练集矩阵;训练集标签
for docIndex in trainingSet:
trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex])) #将训练集中的每一条数据,转化为词向量
trainClasses.append(classList[docIndex])
p0V, p1V, pSpam = trainNB0(array(trainMat),array(trainClasses)) #开始训练
#用10条测试数据,测试分类器的准确性
errorCount = 0
for docIndex in testSet:
wordVector = bagOfWords2VecMN(vocabList, docList[docIndex])
if classifyNB(array(wordVector),p0V,p1V,pSpam) != classList[docIndex]:
errorCount += 1
print "classification error",docList[docIndex] #打印输出错判的那条数据
print 'the error rate is: ',float(errorCount)/len(testSet) #错误率首先,读取一共50封邮件,每一封拆成一个个单词放入一个wordList,再把wordList放入docList。前25封标为垃圾邮件,后25封标为正常邮件。
然后,创建词汇表(用的是createVocabList函数,代码在上一篇博客)。再把50条数据随机选10条当做测试集,40条当做训练集。
然后,拿训练集进行训练。训练函数是trainNB0,代码在上一篇博客。
要注意的是转换成词向量的时候,用的是bagOfWords2VecMN函数,即词带模型。这个模型统计的是单词的出现次数。
最后用测试集进行测试,输出错判的数据,以及最终的错误率。
运行结果:
spamTest()

由于测试集是随机选取的,所以多次测试,结果会不一样。
其实选取测试集的方法还可以小小地改动一下,就是前25条和后25条各随机选5条作为测试数据。
另外提一下,这种随机选择数据的一部分作为训练集,而剩余部分作为测试集的过程成为存留交叉验证(hold-out cross calidation)
----------------------------------------------------------------------------------------------------------------------------------------
实例:适用朴素贝叶斯分类器从个人广告中获取区域倾向
很好。介绍这个实例的背景之前,首先介绍两个东西。
一个是RSS(Really Simple Syndication,简易信息聚合)。它是一种消息来源格式规范,用以聚合经常发布更新数据的网站,例如博客文章、新闻、音频或视频的网摘。RSS文件包含全文或是节录的文字,再加上发布者所订阅之网摘数据和授权的元数据。把新闻标题、摘要(Feed)、内容按照用户的要求,“送”到用户的桌面就是RSS的目的。
也就是说,RSS是一种格式,这种格式的文件以比较规范的形式(当然肉眼读起来还是比较费劲)存储了网页上的信息,例如会包括一条条帖子的内容、帖子的作者、发布的时间等等。可以利用各种各样的RSS阅读器去抓取、解析里面的信息。
感觉这个过程有一点类似于爬虫,只不过RSS文件一般都是网站官方制作而成的,目的就是方便用户订阅、获取网站里面的信息(如新闻、帖子什么的),用RSS阅读器爬取、解析RSS文件是受到网站官方欢迎的。爬虫的话,就有点“非法”的意味了。按我的理解,爬虫是把网页以HTML文档的方式截取下来,然后根据自己的需求,解析HTML文档,把里面自己想要的内容给“抠”出来(顺便推荐一个HTML解析器,beautifulsoup)。爬虫行为一般是不受网站官方欢迎的,不然你以为网站里的验证码是干什么的?就是用来防网络数据采集程序的。
好了又扯远了。说到RSS阅读器,这里推荐的是谷歌家的feedparser,是个Python包,一装就能用。
第二个要介绍的是我们要获取数据的网站,美国的Craigslist(克雷格列表)。按百度的介绍,它是个“巨大无比的网上分类广告加BBS的组合,虽然看上去颇为乏味,可是却是美国人最喜欢的网站之一。有人在这里卖掉自己的旧车,有人在这里租到中意的房子,有人在这里找到工作,还有人在这里找到女朋友。”
然而重点是,这个网站提供RSS文件。
比如我们随便找一个主题:women seeking men,在网址后面加上?format=rss,就可以得到该网页的RSS文件了,看一眼:

很好。我们用feedparser给它parse试一下。
import feedparser
rss_doc = feedparser.parse('https://newyork.craigslist.org/search/w4m?format=rss')
print len(rss_doc['entries'])
for entry in rss_doc['entries']:
print entry['summary_detail']['value']
feedparser.parse返回的是个字典。rss_doc['entries']是所有帖子,它是个List,里面每一条entry是一条帖子。每个entry又是个字典,entry['summary_detail']是帖子详情, 它也是个字典。就是帖子的内容了。
可以看到里面有25条帖子,然后把帖子的内容打印出来了...
现在可以介绍这个小项目的背景了。Craigslist这个网站是分地区的,比如纽约(New York,美国东部)和旧金山(San Francisco,美国西部)。我们从这两个地区的Ctaigslist里面选取一些帖子,通过分析这些帖子里的征婚广告信息,来比较这两个城市的人们在广告用词上是否存在差异。如果确实存在差异,那么两个地区的人各自常用的词是哪些?
先上代码。
def calcMostFreq(vocabList, fullText): #从fullText中找出最高频的前30个单词
import operator
freqDict = {}
for token in vocabList: #统计词汇表里所有单词的出现次数
freqDict[token]=fullText.count(token)
sortedFreq = sorted(freqDict.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedFreq[:30] #返回字典
def localWords(feed1,feed0): #两份RSS文件分别经feedparser解析,得到2个字典
docList=[] #一条条帖子组成的List, 帖子拆成了单词
classList = [] #标签列表
fullText =[] #所有帖子的所有单词组成的List
# entries条目包含多个帖子,miNLen记录帖子数少的数目,怕越界
minLen = min(len(feed1['entries']), len(feed0['entries']))
for i in range(minLen):
wordList = textParse(feed1['entries'][i]['summary']) #取出帖子内容,并拆成词
docList.append(wordList) #['12','34'].append(['56','78']) ==> [ ['12','34'], ['56','78'] ]
fullText.extend(wordList) #['12','34'].extend(['56','78']) ==> ['12','34','56','78']
classList.append(1) #纽约的标签是1
wordList = textParse(feed0['entries'][i]['summary'])
docList.append(wordList)
fullText.extend(wordList)
classList.append(0) #旧金山的标签是0
vocabList = createVocabList(docList) #创建词汇表
# 从fulltext中找出最高频的30个单词,并从vocabList中去除它们
top30Words = calcMostFreq(vocabList, fullText)
for (word, count) in top30Words:
if word in vocabList:
vocabList.remove(word)
trainingSet = range(2*minLen); testSet=[] #创建训练集、测试集
for i in range(minLen / 10 ): #随机选取10%的数据,建立测试集
randIndex = int(random.uniform(0,len(trainingSet)))
testSet.append(trainingSet[randIndex])
del(trainingSet[randIndex])
trainMat=[]; trainClasses = []
for docIndex in trainingSet:
trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex])) #将训练集中的每一条数据,转化为词向量
trainClasses.append(classList[docIndex])
p0V,p1V,pSpam = trainNB0(array(trainMat),array(trainClasses)) #开始训练
# 用测试数据,测试分类器的准确性
errorCount = 0
for docIndex in testSet:
wordVector = bagOfWords2VecMN(vocabList, docList[docIndex])
if classifyNB(array(wordVector),p0V,p1V,pSpam) != classList[docIndex]:
errorCount += 1
print 'the error rate is: ',float(errorCount)/len(testSet)
return vocabList,p0V,p1V我们构建的这个分类器的作用是给出一条帖子,判断(猜测)它是来自哪个地区的。New York是1,San Francisco是0.
这份代码思路和上面那个垃圾邮件的代码没什么区别,都是先把文本拆成词,然后构建训练数据集、测试数据及,最后训练、测试,看错误率。
只不过,这里面,调用了calcMostFreq函数把全文(所有帖子加在一起)中找出最高频的30个单词,并从词汇表里去掉了。去掉的原因,是因为这些词一般都是“虚词”,只是起一些辅助性的作用,比如中文里的“在、的、是、和、了”之类的。它们对表征帖子的来源区域并没有很大的帮助。但更好的方法是人工把这些词列出来,然后在文档里面找到并且去掉,而不是统计高频词。而且这样从经验上看会使错误率降低。这里有一份英文的停用词表。
看下运行效果:
import feedparser
feeds_ny = feedparser.parse('https://newyork.craigslist.org/search/stp?format=rss') #纽约
feeds_sf = feedparser.parse('https://sfbay.craigslist.org/search/stp?format=rss') #旧金山
print len(feeds_ny['entries']), len(feeds_sf['entries'])
localWords(feeds_ny, feeds_sf)
这个错误率当然是会上下波动的,毕竟测试即使随机采样的,而且!训练集实在是太小了,可以看到两份RSS文件各自才爬取了25个帖子。
有时候这个错误率高的离谱,但这个并不是什么问题,因为,我们关注的是单词概率而不是实际分类。
下面我们来比较一下两个地区的用词倾向。先上代码。
def getTopWords(feeds_ny, feeds_sf):
vocabList,p0V,p1V=localWords(feeds_ny, feeds_sf)
topNY=[]; topSF=[]
for i in range(len(p0V)):
if p1V[i] > -6.0 : topNY.append((vocabList[i],p1V[i]))
if p0V[i] > -6.0 : topSF.append((vocabList[i],p0V[i]))
sortedNY = sorted(topNY, key=lambda pair: pair[1], reverse=True)
print "NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**"
for (word, prob) in sortedNY:
print word
sortedSF = sorted(topSF, key=lambda pair: pair[1], reverse=True)
print "SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**"
for (word, prob) in sortedSF:
print word代码很简单,就是把纽约和旧金山的RSS文件解析以后,调用locaWords()函数里面,构建分类器,获得每个词出现的概率,p1V和p0V。然后只留下概率(的对数)>-6.0的单词,排序后从高到低输出。看下效果:
feeds_ny = feedparser.parse('https://newyork.craigslist.org/search/stp?format=rss')
feeds_sf = feedparser.parse('https://sfbay.craigslist.org/search/stp?format=rss')
getTopWords(feeds_ny, feeds_sf)
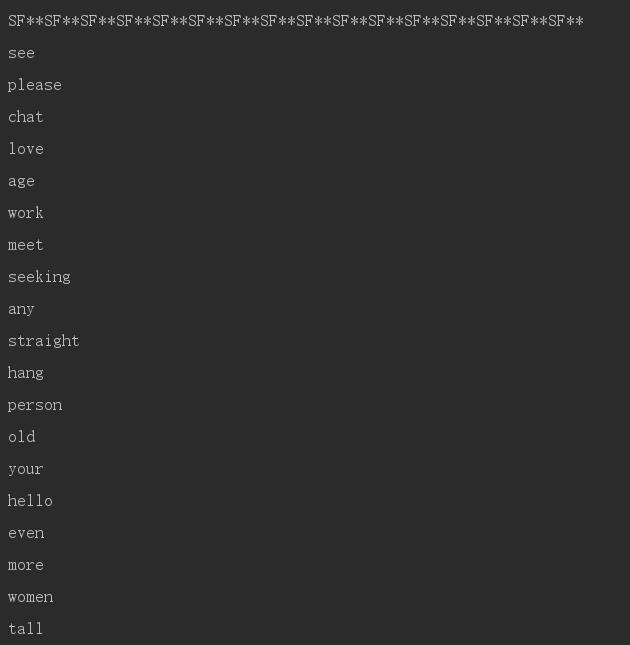
是的,里面包含了不少停用词。所以一开始处理的时候如果把他们去掉,效果肯定会提升,即找出更多能够表征区域用词习惯的单词。














 626
626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









