







 C3D网络利用3D卷积有效保留并学习时空特征,优于2D卷积在网络流中处理时间信息。通过在Sports-1M数据集上训练,C3D在行为识别等多个领域展现优秀性能。
C3D网络利用3D卷积有效保留并学习时空特征,优于2D卷积在网络流中处理时间信息。通过在Sports-1M数据集上训练,C3D在行为识别等多个领域展现优秀性能。
3D卷积和池化
观点:
1)只有3D卷积才能保留输入信号的时间信息,相同的现象适用于2D和3D池化.
2)虽然以前一些时间流网络采用多个帧作为输入,但是由于2D卷积,在第一卷积层之后,时间信息完全消失了。
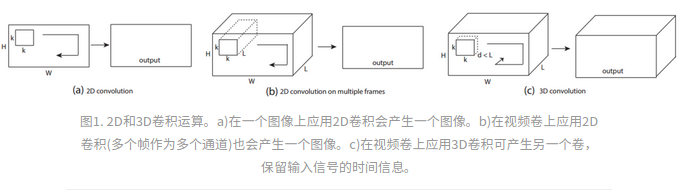
2D与3D卷积之间的区别:
1)a)和b)分别为2D卷积用于单通道图像和多通道图像的情况(此处多通道图像可以指同一张图片的3个颜色通道,也指多张堆叠在一起的图片,即一小段视频),对于一个滤波器,输出为一张二维的特征图,多通道的信息被完全压缩了。
2)c)中的3D卷积的输出仍然为3D的特征图。
· 3D ConvNets比2D ConvNets更适用于时空特征的学习;
· 对于3D ConvNet而言,在所有层使用3×3×3的小卷积核效果最好;
网络的输入输出
输入:一个clip
输出:类别
clip的尺寸:c×l×h×w,分别为通道数,单个clip中帧的数量,每帧的高和宽。
帧分辨率h×w:128×171(大约UCF101分辨率的一半)
clip长度l:16.视频被分成一个个16帧的clip,且无重叠
故clip尺寸为3×16×128×171
网络结构
一共包含5个卷积层,每层的卷积核数量为64,128,256,256,256。在时间和空间上都进行合适的padding操作,并且步长选为一,这样就能够保证卷积前后clip的尺寸不变。
pooling层:第一层上的pooling操作采用1×2×2的kernel size,1代表深度。意图是想尽量保留运动信息不要过早融合。之后的pooling操作均采用2×2×2的kernel size。
超参探索
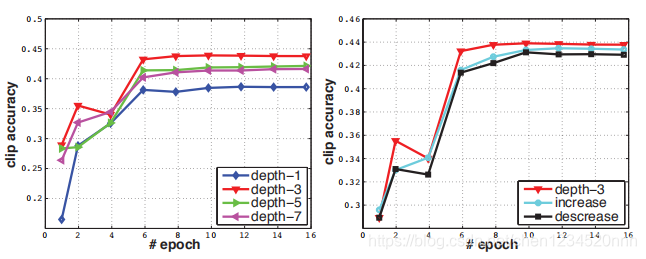
其实本文的目的之一也是研究如何融合运动信息。但是本文只探索卷积核时间维度的最佳大小,而保持其它设置不变。这里从两个方向进行尝试:
1. 均匀时间深度:即所有卷积层都用同样尺寸卷积核;
即对于第一种,我们尝试四个网络,分别用depth值为1,3,5,7的卷积核,深度为d的网络成为depth-d网络。
2. 变化时间深度:对第二种,尝试两个网络,第一种卷积核increasing,各层卷积核深度为3,3,5,5,,7,第二种卷积核decreasing,为7,5,5,3,3。
所有这些网络在经过最后一个池化层后输出信息尺寸一样(因为有padding)。由实验结果(下图)发现3×3×3的卷积核效果最佳,并且好于2D卷积(depth=1就是2D卷积)
网络整体描述
当面对大型数据集的时候,可以加深网络深度,但卷积核依旧使用3×3×3。从现在开始,正式叫这个网络为C3D。整体介绍一下这个网络的配置:

1)所有3D卷积滤波器均为3×3×3,步长为1×1×1。
2)为了保持早期的时间信息设置pool1核大小为1×2×2、步长1×2×2,其余所有3D池化层均为2×2×2,步长为2×2×2。
3)每个全连接层有4096个输出单元。
基于3D卷积操作,作者设计了如上图所示的C3D network结构:
· 共有8次卷积操作,4次池化操作。
· 其中卷积核的大小均为3×3×3,步长为1×1×1。
· 池化核的大小为2×2×2,步长为2×2×2;但第一层池化除外,pool1层卷积大小和步长均为1×2×2,这是为了不过早缩减时序上的长度。最终网络在经过两次全连接层和softmax层后就得到了最终的输出结果。网络的输入尺寸为3×16×112×112,即一次输入16帧图像。
数据集:
为了学习时空特征,我们在Sports-1M数据集上训练C3D,这是目前最大的视频分类基准。数据集由110万个体育视频组成。 每个视频属于487个运动类别之一。 与UCF101相比,Sports-1M具有5倍的类别和100倍的视频数量。
训练
在 Sports-1M数据集上训练。
1)从每个视频中随机抽取5个clip,每个clip占2秒,每个clip被resize为128×127.
2)训练时又把每个输入片段裁剪为16×112×112 的16帧图。
3)对于空间和时间抖动。 我们也以50%的概率水平翻转它们。训练由SGD完成,batch size为30。初始学习率为0.003,每150K次迭代除以2。优化在1.9M迭代(约13epochs)停止。除了从头开始训练C3D外,我们还从在I380K上预先训练的模型中对C3D网进行了微调。
实验结果
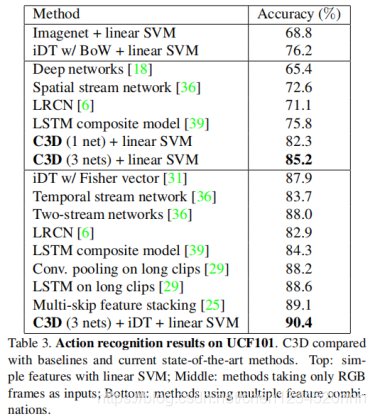
作者将C3D在行为识别、动作相似度标注、场景与物体识别这三个方向的数据库上进行了测试,均取得了不错的效果。以下结果均为当时情况下的比较(2015年)。
运行时间分析
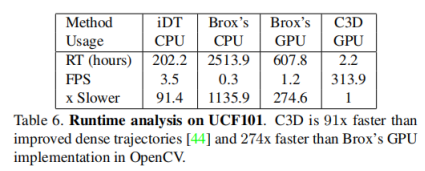
1)光流计算(GPU版本)现在的速度可以达到20-25fps;
2)表中C3D的速度应该是在视频帧无重叠的情况下获得的。将一段16帧的视频作为一个输入,则C3D一秒可以处理约42个输入(显卡为1080, batch size选为50),换算成无重叠情况下的fps为672。可见C3D的速度还是非常快的。
总结
C3D使用3D CNN构造了一个效果不错的网络结构,对于基于视频的问题均可以用来提取特征。可以将其全连接层去掉,将前面的卷积层放入自己的模型中,就像使用预训练好的VGG模型一样。

















 1798
1798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









