










Learning Spatiotemporal Features with 3D Convolutional Networks
摘要
提出了一个简单但有效的学习时空特征的方法,利用在大规模监督视频数据集上训练得到的深度三维卷积网络(3D ConvNets)学习。
贡献主要有三个方面:
- 对比2D卷积网络,3D卷积网络更适合学习时空特征。
- 对3D卷积网络来说,在所有层都用3×3×3的小卷积效果最好。
- 将由一个简单的线性分类器学习到的特征命名为C3D(Convolutional 3D),在4个不同基准上效果比最新的方法好,并且在另2个基准上和现在最好的方法效果不分轩轾。
并且,特征非常紧密:在UCF101数据集上只用了10维就达到52.8%的准确率,并且因为ConvNets的推理速度快,C3D计算效率很高。C3D不仅概念简单,也易于训练和使用。
引言
为了对抗信息爆炸,需要理解和分析视频。目前计算机视觉研究者在视频分析的不同问题,例如行为识别,异常事件检测,行为理解等方面,都做了很多工作,针对具体的问题进行具体的分析,但是,没有通用的视频描述符来以同样的方式处理大量视频任务。
一个有效的视频描述符具有4个属性:
- 通用性。描述符要能够表示不同类型的视频,同时还要具有区分度。例如,互联网上的视频有关于地貌的,有关于自然风光的,有关于运动的,电视剧的,电影的,宠物的,食物的等等。
- 紧凑性。紧凑的描述符能够帮助处理,存储,在不同大小的目标域中检索数以百万计的视频。
- 高效性。描述符要能够在现实系统中每分钟处理成千视频。
- 易实施性。即使用简单的模型(例如线性分类器),描述符也要能够很好地运行。
深度学习图像领域,各种各样的预训练卷积网络模型用于提取图像特征。这些特征是网络最后几个全连接层的激活值,在迁移学习任务中表现良好。但是,这些机遇图片的深度特征不能直接用于视频,因为缺少运动模型。于是提出C3D。通过实验,用简单线性分类器学习到的特征在多种视频分析任务中都能有很好的效果。虽然之前3D卷积网络被提出过牡丹石C3D在大量监督训练数据集合现代深度框架前提下,在不同类型的视频分析任务中,取得的效果是最好的。3D卷积玩过提取到的特征概括了视频中的目标物体的信息,场景信息和运动信息,使得不用去finetune模型就能解决不同的视频分析任务。C3D拥有有效的视频描述符应具有的4个属性,通用性,紧凑型,高效性和易实施性。贡献总结如下:
- 实验证明3D卷积网络是好的特征学习器,能够同时学到对外观和运动进行建模。
- 实验发现在了解的有限框架内,所有层使用3×3×3卷积核效果是最好的。
- 所提出的基于简单的线性模型提取特征的方法,在4个不同的视频分析任务和6个不同的基准上表现出来的效果比现在最好的方法好(或是接近)。

表1展示了C3D和目前最好的方法比较结果。通过表格结果,可见C3D除了在Sports-1M和UCF101两个基准上,比之前表现效果最好的一些方法结果还要好。在UCF101上,放上了两个方法得到的结果,85.2这个结果只使用了RGB帧作为输入,90.4这个结果使用了所有可能的特征(光流,提高后的密集轨迹)。
相关工作
计算机视觉领域针对视频的研究历史已经有几十年了,提出了很多问题,例如行为识别,异常检测,视频检索,运动检测等。这些工作里相当大部分都是与视频表示有关的。作者提到了本文之前的很多工作,着重说了iDT方法,这是目前最好的人工设计特征。iDT描述符说明时间信号处理和空间信号处理是不同的。和将Harris边角检测器拓展到3D不同,它从视频帧中密集采样的特征点开始,并利用光流跟踪它们。对于每一个跟踪器边角,沿着轨迹提取不同的手工设计特征。但是,iDT计算量很大。
随着深度学习应用到图片特征学习中,很多学者进行了很多尝试,但在训练上仍然是计算密集型,并且难以扩展到大规模数据集的测试中。3D卷积针对人类行为识别和医学图像分割而提出。限制玻尔兹曼机器也使用3D卷积学习时空特征。与此文最相关的是3D卷积方法。此方法使用人类检测器和头部跟踪在视频中分割人类受试者。分割过的视频作为3个卷积层的3D卷积网络的输入对行为进行分类。相比之下,本文方法将整个视频的帧作为输入,不依赖于任何预处理,因此容易扩展到大型数据集中。本方法与Karpathy、Simonyan和Zisserman等人的方法有相似之处,因为要使用全帧来训练卷积网络。然而,这些方法建立在仅使用2D卷积和2D池化操作(Slow Fusion模型除外)的基础上,然而本文模型在网络中的所有层中传播时间信息来执行3D卷积和3D池化。同时发现逐步池化空间和时间信息,建立更深层次的网络可以取得最佳效果。
用3D卷积网络学习特征
本部分阐述了3D卷积网络的基本操作细节,分析了3D卷积网络的不同结构,并阐述了如何在大规模数据及上针对特征学习进行训练。
3D卷积和池化
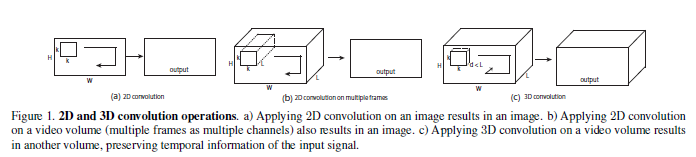
与2D卷积网络相对比,3D卷积网络能够更好地对时间信息进行建模,因为有3D卷积和3D池化操作。在3D卷积网络中,卷积和池化操作是在时空上执行的,但是2D卷积网络只在空间上执行。图1阐述了这种不同。应用在一张图片上的2D卷积会输出一张图片,应用在多张图片(将它们视作不同通道)上的2D卷积输出也是一张图片。因此,2D卷积网络在每次卷积运算后就会丢失输入信号的时间信息。只有3D卷积才能保留输入信号的时间信息,最后得到一个输出卷。在2D和3D池化操作上也有相同的现象。在双流结构中,尽管时间网络将多帧作为输入,但因为是2D卷积,在第一次卷积层后,时间信息就完全消失了。[18]的融合模型使用2D卷积,大部分网络在第一层卷积层后就丢失了输入的时间信号,只有慢融合[18]模型在第一个3卷积层中使用了3D卷积和平均池化,作者坚信这是慢融合模型取得的效果比[18]中研究的其他网络效果好的原因。遗憾的是,慢融合仍然在第三个卷积层后丢失了所有时间信息。
作者通过经验去尝试找到一个良好的3D卷积网络架构。因为在大规模视频数据集上训练深度网络是非常耗时的,所以首先在中型数据集UCF101上进行实验,去寻找最好的架构。后来在一个大规模的数据集中,用少量网络实验验证了发现。根据在2D卷积网络中的发现,具有更深的结构的3×3卷积核的小视野域取得的效果更好。因此,针对架构搜寻研究,固定空间感受野大小为3×3,仅改变时间3D卷积核的深度。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









