







联邦学习的数据攻击
文章目录
数据攻击类型
常见横向联邦学习攻击方式包含三类:
成员推理[1]:攻击方对于给定样本,判断是否在模型训练集。
属性推断[2]:攻击方对于给定样本属性,判断是否出现在t轮训练。
特征推理:通过观测部分持有方数据信息还原目标样本原始数据。
特征推理
梯度恢复
1)DLG攻击[3]
任务:通过神经网络中的梯度信息去反推原始数据和标签。
方法:随机生成一份和真数据同样大小的假输入样本和假的标签,然后把这些假样本和假标签输入到现有的模型当中,然后得到假的模型梯度。方法的目标是生成与原模型相同梯度的假梯度,这样在假样本和假标签就和真实的样本标签一致
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g2V8G1qx-1625824202252)(/Users/chenxiaolin/Library/Application Support/typora-user-images/image-20210709172942169.png)]](https://i-blog.csdnimg.cn/blog_migrate/f971b22297ff40d25445b9fa2c56c222.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-clOKzo2B-1625824202253)(/Users/chenxiaolin/Library/Application Support/typora-user-images/image-20210709173037879.png)]](https://i-blog.csdnimg.cn/blog_migrate/a3ee1cde1d63300ee155bab52123e877.png)
算法:![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zlQ9XPxI-1625824202254)(/Users/chenxiaolin/Library/Application Support/typora-user-images/image-20210709173327815.png)]](https://i-blog.csdnimg.cn/blog_migrate/404496c006a96de45aa0ce61d0ac31f2.png)
实验结果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kcUDHiCt-1625824202255)(/Users/chenxiaolin/Library/Application Support/typora-user-images/image-20210709173448285.png)]](https://i-blog.csdnimg.cn/blog_migrate/8c5212f7ad6dd78fcc66c42c5bc1768d.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-blXvNxWl-1625824202256)(/Users/chenxiaolin/Library/Application Support/typora-user-images/image-20210709173736715.png)]](https://i-blog.csdnimg.cn/blog_migrate/4618fb24db7c950adb80a9740b231450.png)
缺陷:
(1)实验数据恢复条件苛刻,size=32*32,batch=1
(2)要求拿到模型结果,实际场景中是难以满足这样要求的
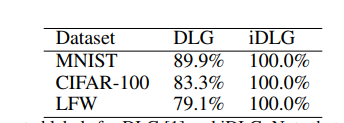
2)iDLG[4]
改进:当使用非负的激活函数时,例如ReLU和Sigmoid,他们激活函数输出的符号是相同的。因此,我们可以简单地识别出其对应的梯度为负值的ground truth标签。

算法:
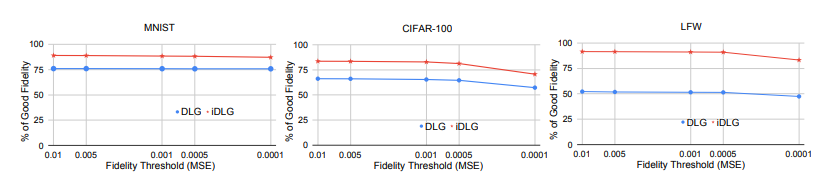
实验结果对比:
由于引入标签反向传播规律,因此标签恢复率达到100%。(传输数据的信息泄漏)
3)GradInversion[5]
任务:批量梯度恢复
目标形式:
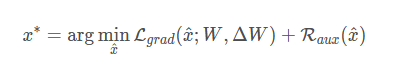
其中 L g r a d L_{grad} Lgrad的目的是使得对可能的输入产生的梯度值与原模型的梯度值一致
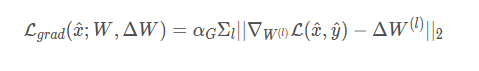
正则项包括真实性正则项与组一致性正则项
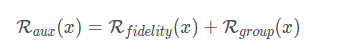
真实性正则项
图像的先验性约束,借鉴Deepinversion对图像的自然优化
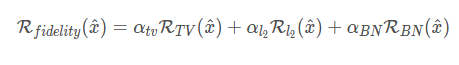
前两项为图像方差与L2范数,第三项是BN先验。
组一致性正则项
不同的随机种子进行图像的还原,会产生不同程度上的偏移

采用不同的随机种子生成,然后对这些结果进行融合
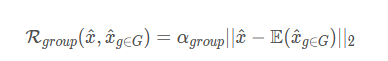
实验结果:
误差项的消融实验
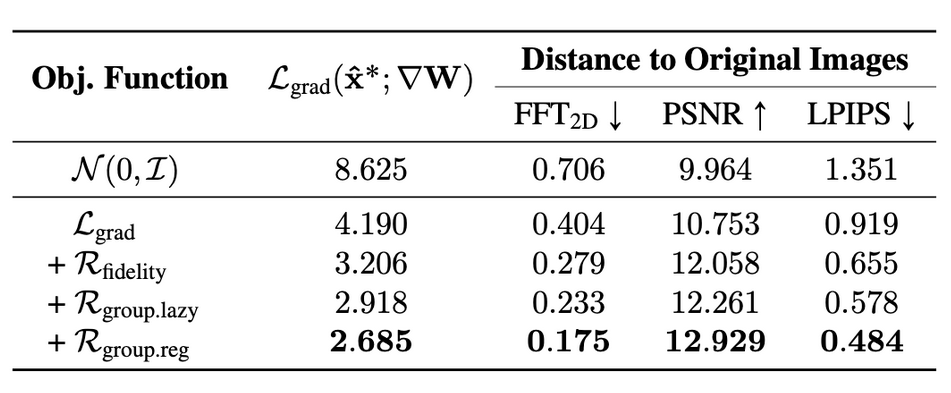
添加真实性以及组一致性,的确会使得图片质量上升,对齐的增益也是存在的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FtNJYlDH-1630293395149)(https://gitee.com/xiaobai201812/csdn_image/raw/master/imh/1629878685000.png)]
梯度反聚合[6]
横向场景中,多设备间进行梯度聚合
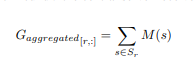

任务:通过聚合的梯度进行反向求解原始梯度,即
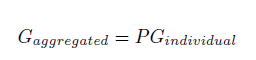
该问题等价于进行矩阵分解,其中p是01矩阵;可以通过求解下列问题进行:
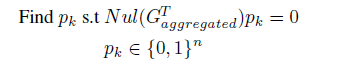
特别地,在联邦场景中,聚合方在多轮通信中可以观察到每个物理机进行聚合的总数,得到下列问题:
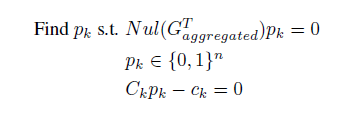
考虑更新过程中的迭代误差,优化目标为:
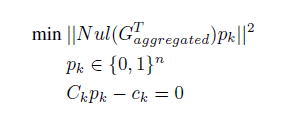
算法如下:

纵向场景下的特征推理攻击方式[7]
任务:对预测模型通过特征攻击的方式还原对方样本。
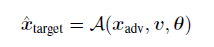
其中target是特征攻击的目标放;adv作为攻击一方,由标签持有方和其他的数据特征持有方组成, θ \theta θ是模型参数,而 v v v是模型预测输出值。
二分类逻辑回归
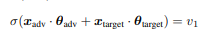
如果 d t a r g e t = 1 d_{target}=1 dtarget=1,显然方程有精确解。
多分类逻辑回归
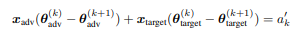
如果 d t a r g e t < = c − 1 d_{target}<=c-1 dtarget<=c−1,可以通过逆运算形式进行求解。
如果 d t a r g e t > = c d_{target}>=c dtarget>=c,那么有无穷解,取pseudo逆,得到范数最小解。
实验结果:
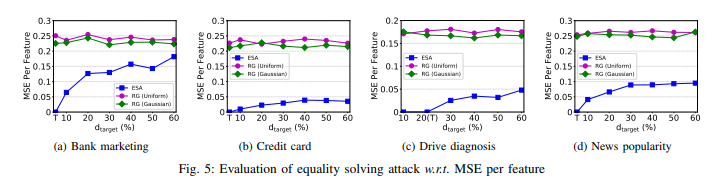
决策树模型
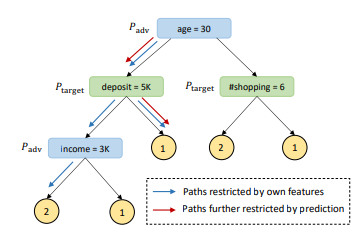
算法如下:
通过攻击方的分裂信息以及标签信息,限制分裂方向,确定推理样本的分裂路径。

示例:
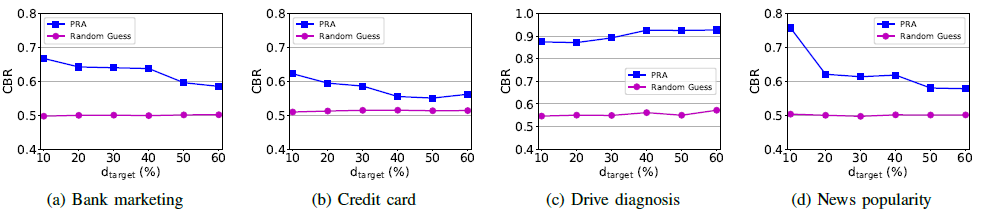
实验结果:
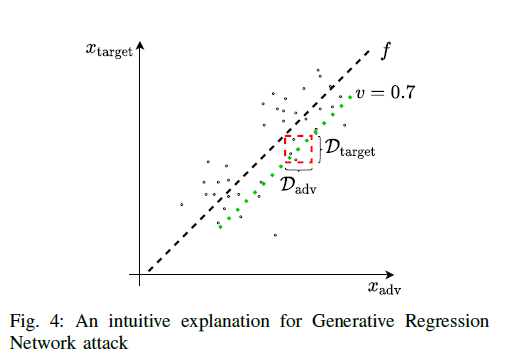
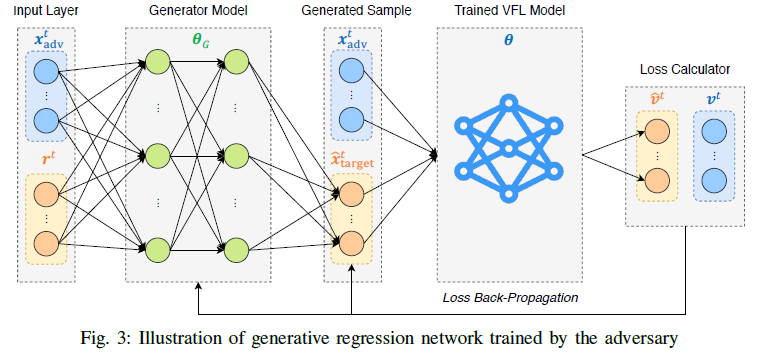
神经网或逻辑回归模型(GRN Attack)
如果是一个线性模型,横纵坐标分别表示已知的攻击方特征与目标特征, f f f表示分类器平面,那么根据 f f f与输出值v可以确定点在绿色直线上,再根据攻击方特征,可以较好准确率地推出目标特征地预测值。
输入攻击方特征 x a d v t x_{adv}^t xadvt和随机向量 r t r^t rt,通过全连接层生成模型,产生目标特征的预测值,并在与攻击方特征拼接后,输入到训练好的垂直联邦学习模型中,计算与ground truth预测值的差值,反向传播到输入层与生成模型中,进行参数更新。
对于像随机森林,可以通过近似神经网替代图中VFL的方式进行,从而实现梯度的反向传播。
实验结果:
随目标特征数的增加,变化如下:
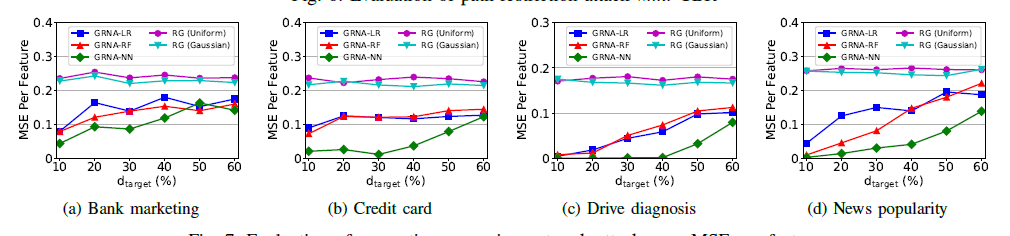
对应不同的GRN输入下,与原始数据恢复的误差如下:

对于随机森林,正确分支的比例CBR(correct branching rate):
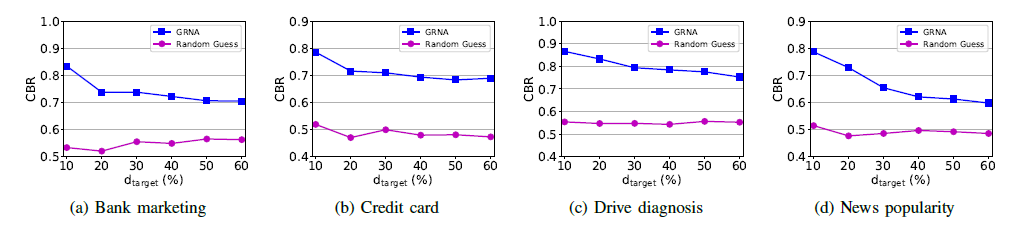

















 1087
1087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









