






将原始数据随机分为两组,一组做为训练集,一组做为验证集,利用训练集训练分类器,然后利用验证集验证模型,记录最后的分类准确率为此Hold-OutMethod下分类器的性能指标.此种方法的好处的处理简单,只需随机把原始数据分为两组即可,其实严格意义来说Hold-Out Method并不能算是CV,因为这种方法没有达到交叉的思想,由于是随机的将原始数据分组,所以最后验证集分类准确率的高低与原始数据的分组有很大的关系,所以这种方法得到的结果其实并不具有说服性.
a.每一回合中几乎所有的样本皆用于训练模型,因此最接近原始样本的分布,这样评估所得的结果比较可靠。
b.实验过程中没有随机因素会影响实验数据,确保实验过程是可以被复制的。
但LOO-CV的缺点则是计算成本高,因为需要建立的模型数量与原始数据样本数量相同,当原始数据样本数量相当多时,LOO-CV在实作上便有困难几乎就是不显示,除非每次训练分类器得到模型的速度很快,或是可以用并行化计算减少计算所需的时间.
4) Jackknife(刀切法)
是有Maurice Quenouille (1949)提出的一种再抽样方法,其原始动机是降低估计的偏差, 作为一种通用的假设检验和置信区间计算的方法。
Jackknife类似于“Leave one out”的交叉验证方法。令X=(X1,X2,…,Xn)为观测到的样本,定义第i个Jackknife样本为丢掉第i个样本后的剩余样本即
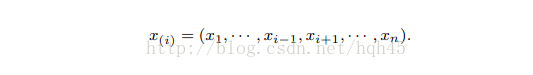
由此生成的Jackknife样本集之间的差异很小,每两个Jackknife样本中只有两个单个的原始样本不同。
Jackknife不适合的场合
统计函数不是平滑函数:数据小的变化会带来统计量的一个大的变化如极值、中值。如对数据X=(10,27,31,40,46,50,52,104,146)的中值得到的结果为48,48,48,48,45,43,43,43,43,偶数个数的中值为最中间两个数的平均值。
Jackknife与Bootstrap自助法的联系
Efron1979年文章指出了自助法与刀切法的关系。首先,自助法通过经验分布函数构建了自助法世界,将不适定的估计概率分布的问题转化为从给定样本集中重采样。第二,自助法可以解决不光滑参数的问题。遇到不光滑(Smooth)参数估计时,刀切法会失效,而自助法可以有效地给出中位数的估计。第三,将自助法估计用泰勒公式展开,可以得到刀切法是自助法方法的一阶近似。第四,对于线性统计量的估计方差这个问题,刀切法或者自助法会得到同样的结果。但在非线性统计量的方差估计问题上,刀切法严重依赖于统计量线性的拟合程度,所以远不如自助法有效。
对交叉验证这个问题,一直以来,不明白是怎么回事。近期看材料,涉及到了这个问题,写的通俗易懂,有种恍然大悟的感觉。下面,我写下对这个问题的理解。
我们以K折交叉验证(k-folded cross validation)来说明它的具体步骤。
A1,A2,A3,A4,A5,A6,A7,A8,A9}{A1,A2,A3,A4,A5,A6,A7,A8,A9}
为了简化,取k=10。在原始数据A的基础上,我们随机抽取一组观测,构成一个数据子集(容量固定),记为A1
重复以上过程10次,我们就会获得一个数据子集集合 {A1,A2,A3,A4,A5,A6,A7,A8,A9,A10}。
接下来,我们首先对模型M
进行交叉验证,如下,

在{A2,A3,A4,A5,A6,A7,A8,A9,A10}基础上构建模型M1,并对数据集A1进行验证,将预测值与真值进行比较,在某一评价标准下,计算一个得分a1,1
.
在{A1,A3,A4,A5,A6,A7,A8,A9,A10}
基础上构建模型M1,并对数据集A2进行验证,将预测值与真值进行比较,在同一评价标准下,计算一个得分a1,2
.
……
在{A1,A2,A3,A4,A5,A6,A7,A8,A9}
基础上构建模型,并对数据集A10进行验证,将预测值与真值进行比较,在同一评价标准下,计算一个得分a1,10
.
a1=a1,1+a1,2+…+a1,10/10
作为模型M1的综合得分。
{A2,A3,A4,A5,A6,A7,A8,A9,A1对每个模型都这样过一遍,最后得到了每个模型的一个得分,按照得分,我们就可以选择最合理的模型。
将数据打成好多份,交叉验证模型,很有点bootstrap的意思,bootstrap的思想渗透到了统计学的各个领域了已经。
除了K折交叉验证,另外两种交叉验证为Hold Out 验证和留一验证:
Hold验证:常识来说,Holdout 验证并非一种交叉验证,因为数据并没有交叉使用。 随机从最初的样本中选出部分,形成交叉验证数据,而剩余的就当做训练数据。 一般来说,少于原本样本三分之一的数据被选做验证数据。
留一验证: 正如名称所建议, 留一验证(LOOCV)意指只使用原本样本中的一项来当做验证资料, 而剩余的则留下来当做训练资料。 这个步骤一直持续到每个样本都被当做一次验证资料。 事实上,这等同于 K-fold 交叉验证是一样的,其中K为原本样本个数。
一、训练集 vs. 测试集
在模式识别(pattern recognition)与机器学习(machine learning)的相关研究中,经常会将数据集(dataset)分为训练集(training set)跟测试集(testing set)这两个子集,前者用以建立模型(model),后者则用来评估该模型对未知样本进行预测时的精确度,正规的说法是泛化能力(generalization ability)。怎么将完整的数据集分为训练集跟测试集,必须遵守如下要点:
1、只有训练集才可以用在模型的训练过程中,测试集则必须在模型完成之后才被用来评估模型优劣的依据。
2、训练集中样本数量必须够多,一般至少大于总样本数的50%。
3、两组子集必须从完整集合中均匀取样。
其中最后一点特别重要,均匀取样的目的是希望减少训练集/测试集与完整集合之间的偏差(bias),但却也不易做到。一般的作法是随机取样,当样本数量足 够时,便可达到均匀取样的效果,然而随机也正是此作法的盲点,也是经常是可以在数据上做手脚的地方。举例来说,当辨识率不理想时,便重新取样一组训练集/ 测试集,直到测试集的识别率满意为止,但严格来说这样便算是作弊了。
二、交叉验证(Cross Validation)
交叉验证(Cross Validation)是用来验证分类器的性能一种统计分析方法,基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集 (training set),另一部分做为验证集(validation set),首先用训练集对分类器进行训练,在利用验证集来测试训练得到的模型(model),以此来做为评价分类器的性能指标。常见的交叉验证方法如下:
1、Hold-Out Method
将原始数据随机分为两组,一组做为训练集,一组做为验证集,利用训练集训练分类器,然后利用验证集验证模型,记录最后的分类准确率为此分类器的性能指标。 此种方法的好处的处理简单,只需随机把原始数据分为两组即可,其实严格意义来说Hold-Out Method并不能算是CV,因为这种方法没有达到交叉的思想,由于是随机的将原始数据分组,所以最后验证集分类准确率的高低与原始数据的分组有很大的关 系,所以这种方法得到的结果其实并不具有说服性。
2、Double Cross Validation(2-fold Cross Validation,记为2-CV)
做法是将数据集分成两个相等大小的子集,进行两回合的分类器训练。在第一回合中,一个子集作为training set,另一个便作为testing set;在第二回合中,则将training set与testing set对换后,再次训练分类器,而其中我们比较关心的是两次testing sets的辨识率。不过在实务上2-CV并不常用,主要原因是training set样本数太少,通常不足以代表母体样本的分布,导致testing阶段辨识率容易出现明显落差。此外,2-CV中分子集的变异度大,往往无法达到“实 验过程必须可以被复制”的要求。
3、K-fold Cross Validation(K-折交叉验证,记为K-CV)
将原始数据分成K组(一般是均分),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,用这K个模型最终的验证 集的分类准确率的平均数作为此K-CV下分类器的性能指标。K一般大于等于2,实际操作时一般从3开始取,只有在原始数据集合数据量小的时候才会尝试取 2。K-CV可以有效的避免过学习以及欠学习状态的发生,最后得到的结果也比较具有说服性。
4、Leave-One-Out Cross Validation(记为LOO-CV)
如果设原始数据有N个样本,那么LOO-CV就是N-CV,即每个样本单独作为验证集,其余的N-1个样本作为训练集,所以LOO-CV会得到N个模 型,用这N个模型最终的验证集的分类准确率的平均数作为此下LOO-CV分类器的性能指标。相比于前面的K-CV,LOO-CV有两个明显的优点:
(1)每一回合中几乎所有的样本皆用于训练模型,因此最接近原始样本的分布,这样评估所得的结果比较可靠。
(2)实验过程中没有随机因素会影响实验数据,确保实验过程是可以被复制的。
但LOO-CV的缺点则是计算成本高,因为需要建立的模型数量与原始数据样本数量相同,当原始数据样本数量相当多时,LOO-CV在实作上便有困难几乎就是不显示,除非每次训练分类器得到模型的速度很快,或是可以用并行化计算减少计算所需的时间。
三、使用Cross-Validation时常犯的错误
由于实验室许多研究都有用到 evolutionary algorithms(EA)与 classifiers,所使用的 fitness function 中通常都有用到 classifier 的辨识率,然而把cross-validation 用错的案例还不少。前面说过,只有 training data 才可以用于 model 的建构,所以只有 training data 的辨识率才可以用在 fitness function 中。而 EA 是训练过程用来调整 model 最佳参数的方法,所以只有在 EA结束演化后,model 参数已经固定了,这时候才可以使用 test data。那 EA 跟 cross-validation 要如何搭配呢?Cross-validation 的本质是用来估测(estimate)某个 classification method 对一组 dataset 的 generalization error,不是用来设计 classifier 的方法,所以 cross-validation 不能用在 EA的 fitness function 中,因为与 fitness function 有关的样本都属于 training set,那试问哪些样本才是 test set 呢?如果某个 fitness function 中用了cross-validation 的 training 或 test 辨识率,那么这样的实验方法已经不能称为 cross-validation 了。
EA 与 k-CV 正确的搭配方法,是将 dataset 分成 k 等份的 subsets 后,每次取 1份 subset 作为 test set,其余 k-1 份作为 training set,并且将该组 training set 套用到 EA 的 fitness function 计算中(至于该 training set 如何进一步利用则没有限制)。因此,正确的 k-CV 会进行共 k 次的 EA 演化,建立 k 个classifiers。而 k-CV 的 test 辨识率,则是 k 组 test sets 对应到 EA 训练所得的 k 个 classifiers 辨识率之平均值。
原文地址:https://www.cnblogs.com/sddai/p/5696834.html















 4915
4915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









