






先掌握pytorch,学好pytorch, 才能学好人工智能
线性层,
也叫全连接层(Fully Connected Layer),是神经网络中的一种基本层,通常用于处理一维数据(即向量)。在多层感知机(MLP)和卷积神经网络(CNN)中,线性层通常位于网络的最后,用于将前面层的特征映射到输出空间。
功能
线性层的主要功能是将输入数据通过线性变换映射到新的空间。具体来说,它通过以下公式计算输出: output=Wx+b 其中:
- x 是输入向量。
- W 是权重矩阵。
- b 是偏置向量。
- output 是线性层的输出。
以下是对其详细的介绍:
一、工作原理
- 线性组合:线性层的每个神经元都与上一层的所有神经元相连,通过对输入进行加权求和来实现线性组合。具体来说,对于一个输入向量
x,线性层的输出y可以表示为y = Wx + b,其中W是权重矩阵,b是偏置向量。 - 权重矩阵和偏置向量:权重矩阵
W决定了输入特征之间的线性关系,不同的权重值会对不同的输入特征赋予不同的重要性。偏置向量b则允许模型在没有输入的情况下也能产生一个非零的输出,增加了模型的灵活性。 - 维度变换:线性层可以改变输入数据的维度。例如,如果输入是一个形状为
(batch_size, input_dim)的张量,而线性层的输出维度为output_dim,那么权重矩阵W的形状将是(input_dim, output_dim),偏置向量b的形状将是(output_dim)。经过线性层的变换后,输出张量的形状将变为(batch_size, output_dim)。
二、作用和意义
- 特征提取和转换:线性层可以学习到输入数据的不同特征表示,通过调整权重矩阵和偏置向量,可以将输入数据映射到不同的特征空间,从而提取出有用的信息。例如,在图像分类任务中,线性层可以将图像的像素值映射到不同的类别空间,实现对图像的分类。
- 模型的复杂性和表达能力:增加线性层的数量和大小可以增加模型的复杂性和表达能力。更多的线性层可以学习到更复杂的函数关系,从而提高模型的性能。然而,过多的线性层也可能导致过拟合,需要通过适当的正则化方法来避免。
- 与其他层的结合:线性层通常与其他层(如激活函数层、卷积层、池化层等)结合使用,构建更复杂的神经网络结构。例如,在卷积神经网络中,线性层通常在卷积层和池化层之后使用,将提取到的特征映射到最终的输出空间。
三、示例代码(使用 PyTorch)
以下是一个使用 PyTorch 构建线性层的简单示例:
import torch
import torch.nn as nn
# 创建一个随机输入张量,形状为 (batch_size, input_dim)
input_tensor = torch.ones(1,5) # 1 个样本,每个样本有 5 个特征
print("输入张量形状:", input_tensor.shape,'\n',input_tensor)
# 创建一个线性层,输入维度为 5,输出维度为 10
linear_layer = nn.Linear(in_features=5, out_features=10)
linear_layer.weight.data = torch.eye(10,5)
linear_layer.bias.data.fill_(0.0)
# 进行线性变换
output_tensor = linear_layer(input_tensor)
print(linear_layer.weight.data)
print("输出张量形状:", output_tensor.shape,'\n',output_tensor)输入张量形状: torch.Size([1, 5]) tensor([[1., 1., 1., 1., 1.]]) tensor([[1., 0., 0., 0., 0.], [0., 1., 0., 0., 0.], [0., 0., 1., 0., 0.], [0., 0., 0., 1., 0.], [0., 0., 0., 0., 1.], [0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.], [0., 0., 0., 0., 0.]]) 输出张量形状: torch.Size([1, 10]) tensor([[1., 1., 1., 1., 1., 0., 0., 0., 0., 0.]], grad_fn=<AddmmBackward0>)
在这个示例中,我们首先创建了一个随机输入张量,然后使用nn.Linear创建了一个线性层,并对输入张量进行线性变换。输出张量的形状将是(10, 10),因为输入张量的形状是(10, 5),线性层的输出维度是 10。
激活函数层
-
激活函数层的作用
- 激活函数层是神经网络中的重要组成部分,它为神经网络引入非线性特性。如果没有激活函数,神经网络就只是简单的线性组合,无法处理复杂的非线性关系。常见的激活函数包括 Sigmoid、Tanh、ReLU(Rectified Linear Unit)及其变种等。
-
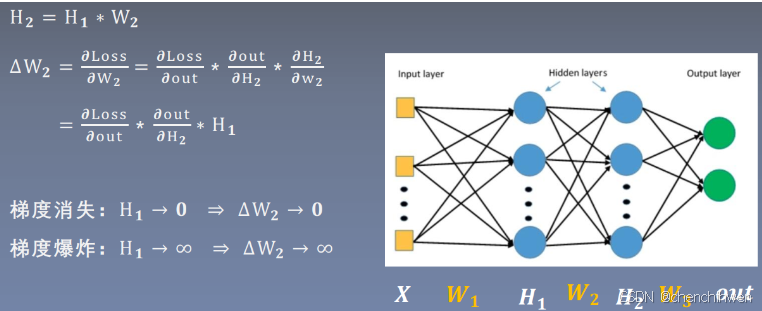
梯度消失(Vanishing Gradient)
- 现象描述
- 在深度神经网络中,梯度消失是指在反向传播过程中,靠近输入层的梯度变得非常小,几乎趋近于零。这使得靠近输入层的权重更新非常缓慢,导致训练过程难以收敛到最优解。
- 产生原因(与激活函数相关)
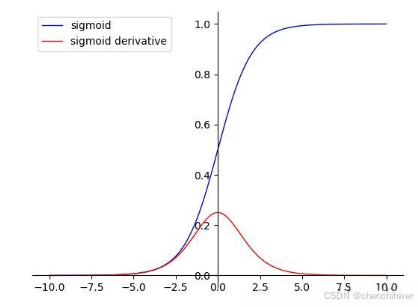
- Sigmoid 激活函数:Sigmoid 函数的表达式为,其导数为。当的绝对值较大时,趋近于或者,此时趋近于。在深度神经网络中,经过多层的链式法则计算梯度,由于每层的梯度都小于,多个小于的数相乘会使得梯度迅速趋近于。
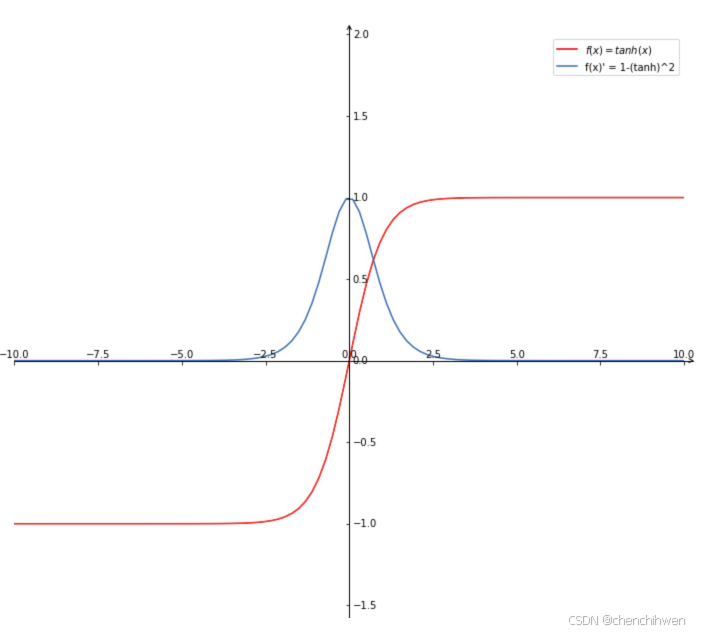
- Tanh 激活函数:Tanh 函数的表达式为,其导数为。当的绝对值较大时,也趋近于,同样在深度神经网络中会导致梯度消失的问题。
- 现象描述
-
梯度爆炸(Exploding Gradient)
- 现象描述
- 与梯度消失相反,梯度爆炸是指在反向传播过程中,梯度的值变得非常大,导致权重更新过大,可能会使网络的权重在训练过程中出现数值溢出的情况,使训练过程不稳定甚至无法收敛。
- 产生原因(与激活函数相关)
- 在一些情况下,如果初始化权重过大,再加上激活函数的导数在某些区间较大,经过多层的链式法则计算梯度时,多个较大的数相乘会导致梯度爆炸。例如,如果使用不恰当的初始化方法,在某些网络结构中可能会使梯度迅速增大。不过,常见的激活函数如 ReLU 等在正常初始化情况下不太容易直接导致梯度爆炸,更多是与网络结构(如递归神经网络中的长时依赖问题)、初始化方法以及优化算法等因素共同作用导致的。
- 在一些情况下,如果初始化权重过大,再加上激活函数的导数在某些区间较大,经过多层的链式法则计算梯度时,多个较大的数相乘会导致梯度爆炸。例如,如果使用不恰当的初始化方法,在某些网络结构中可能会使梯度迅速增大。不过,常见的激活函数如 ReLU 等在正常初始化情况下不太容易直接导致梯度爆炸,更多是与网络结构(如递归神经网络中的长时依赖问题)、初始化方法以及优化算法等因素共同作用导致的。
- 现象描述
二、解决梯度消失和梯度爆炸的方法
梯度消失和梯度爆炸是深度学习中常见的问题,通常与激活函数的选择和权重初始化有关。以下是一些解决这些问题的方法:
-
梯度剪切:通过设置一个梯度剪切阈值,在更新梯度时,如果梯度超过这个阈值,就将其强制限制在这个范围内,这可以防止梯度爆炸。
-
权重正则化:使用L1或L2正则化来约束网络权重,防止权重过大,从而限制梯度爆炸的发生。
-
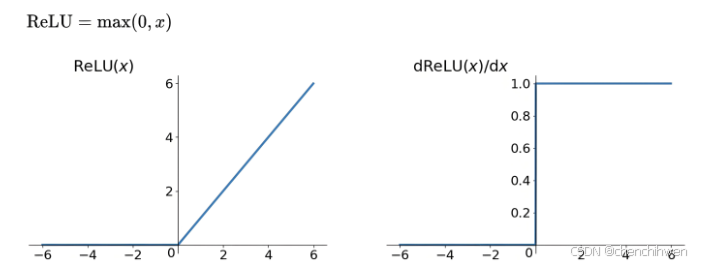
激活函数:更换激活函数,如使用ReLU代替Sigmoid或Tanh,因为ReLU在正区域的导数为1,不会出现梯度消失问题。
-
Batch Normalization:通过在每一层的输出上进行规范化操作,使输出值更接近标准正态分布,这有助于防止梯度消失和梯度爆炸。
-
残差结构:在神经网络中使用残差连接,可以帮助梯度更有效地传播,从而缓解梯度消失问题。
-
梯度归一化:在优化算法中,如梯度下降,使用梯度归一化来防止梯度爆炸。
-
权重初始化:使用合适的权重初始化策略,如Xavier/Glorot初始化或He初始化,有助于缓解梯度爆炸问题。
-
Leaky ReLU:使用Leaky ReLU激活函数,它允许负值有一定的梯度,可以避免ReLU的神经元死亡问题。
Leaky ReLU(带泄漏的修正线性单元)是 ReLU(Rectified Linear Unit)激活函数的一种变体,主要用于解决 ReLU 在负半轴上梯度为 0 的问题。对于输入值x,Leaky ReLU 的计算公式为:,其中alpha是一个很小的常数(通常左右)。 -
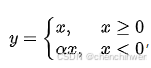
-
ELU系列函数:使用ELU或PReLU等激活函数,它们对负值有一定的输出,可以缓解梯度消失问题。PReLU(Parametric Rectified Linear Unit)是 ReLU 的一种变体。对于输入值,PReLU 的计算公式为,这里的alpha是一个可学习的参数,而不像 LeakyReLU 中的是预先设定好的固定值。
PReLU 在一些深度神经网络中表现良好,尤其是在图像识别、语音识别等任务中。它能够在一定程度上提高模型的表达能力和泛化能力,因为它可以根据不同的数据自动调整激活函数在负半轴的特性,从而更好地捕捉数据中的非线性关系。不过,由于需要学习额外的参数,可能会增加一些计算成本和模型的复杂度,但在很多情况下,这种权衡是值得的。
import torch import torch.nn as nn # 创建PReLU激活函数 prelu = nn.PReLU() # 随机生成输入张量 input_tensor = torch.randn(10, 5) output_tensor = prelu(input_tensor) print(output_tensor) -
梯度检查:在训练过程中定期检查梯度值,以确保它们没有变得过大或过小

















 1406
1406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









