







一 下载eclipse和JDK
eclipse-jee-mars-2-win32-x86_64.zip
jdk-7u51-windows-x64.exe
工作目录建立在如下目录
F:\Hadoop\workspace
二 创建maven项目mapreduce
三 编辑pom.xml
进入http://www.mvnrepository.com/网站,寻找依赖
1 搜索hadoop
针对hadoop-common
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
针对hadoop-hdfs
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.4</version>
</dependency>
针对hadoop-mapreduce-client-common
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.7.4</version>
</dependency>
针对hadoop-mapreduce-client-core
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.4</version>
</dependency>
2 pom.xml配置如下
<project xmlns="http://maven.apache.org/POM/4.0.0"; xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance";
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0http://maven.apache.org/xsd/maven-4.0.0.xsd";>
<modelVersion>4.0.0</modelVersion>
<groupId>com.cakin</groupId>
<artifactId>mapreduce</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>mapreduce</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.7.0_51</version>
<scope>system</scope>
<systemPath>D:/Program/Java/jdk1.7.0_51/lib/tools.jar</systemPath>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
四 MapReduce代码编写
1 Mapper类编写
package com.cakin.mapreduce.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* map阶段的业务逻辑处理就写在map()方法中
* maptask会对每一行输入数据调用一次我们自定义的map()方法
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key,Text value,Context context) throws IOException, InterruptedException{
//将maptask传递给我们的文本内容先转换成string
String line=value.toString();
//按照空格行切割单词
String[] words=line.split(" ");
//将单词输出为<单词,1>
for(String word:words) {
//将单词作为key,将次数1作为Value,以便于后续的数据分发,可以根据单词分发,以便于相同单词会到相同的reduce task
context.write(new Text(word),new IntWritable(1));
}
}
}
2 Reduce类编写
package com.cakin.mapreduce.wc;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* KEYIN,VALUE对应mapper输出的KEYOUT,VALUEOUT
* KEYOUT,VALUEOUT是自定义的reduce逻辑处理结果的输出数据类型
* @author
*/
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
* <angel,1> <angel,1> <angel,1> <angel,1> <angel,1>
* <hello,1> <hello,1> <hello,1> <hello,1> <hello,1> <hello,1>
* <banana,1> <banana,1> <banana,1> <banana,1> <banana,1> <banana,1>
* 入参key:是一组单词的kv对应的key,将相同单词的一组传递,如此时key是hello,那么参数二是一个迭代器,一组数
* @throws InterruptedException
* @throws IOException
*/
@Override
protected void reduce(Text key,Iterable<IntWritable> values ,Context context) throws IOException, InterruptedException {
int count=0;
/**
Iterator<IntWritable> iterator=values.iterator();
while(iterator.hasNext()) {
count+=iterator.next().get();
}
*/
for(IntWritable value:values) {
count+=value.get();
}
context.write(key, new IntWritable(count));
}
}
3 Driver编写
package com.cakin.mapreduce.wc;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 相当于一个yarn集群的客户端
* 需要在此封装我们mr程序的相关运行参数,指定jar包,最后交给yarn
*/
public class WordcountDriver {
public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {
Configuration conf=new Configuration();
/*
* 集群中节点都有配置文件
conf.set("mapreduce.framework.name.", "yarn");
conf.set("yarn.resourcemanager.hostname", "mini1");
*/
Job job=Job.getInstance(conf);
//jar包在哪里,现在在客户端,传递参数
//任意运行,类加载器知道这个类的路径,就可以知道jar包所在的本地路径
job.setJarByClass(WordcountDriver.class);
//指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
//指定mapper输出数据的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//指定最终输出的数据kv类型
job.setOutputKeyClass(Text.class);
job.setOutputKeyClass(IntWritable.class);
//指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//将job中配置的相关参数及job所用的java类在的jar包,提交给yarn去运行
//提交之后,此时客户端代码就执行完毕,退出
//job.submit();
//等集群返回结果在退出
boolean res=job.waitForCompletion(true);
System.exit(res?0:1);
//类似于shell中的$?
}
}
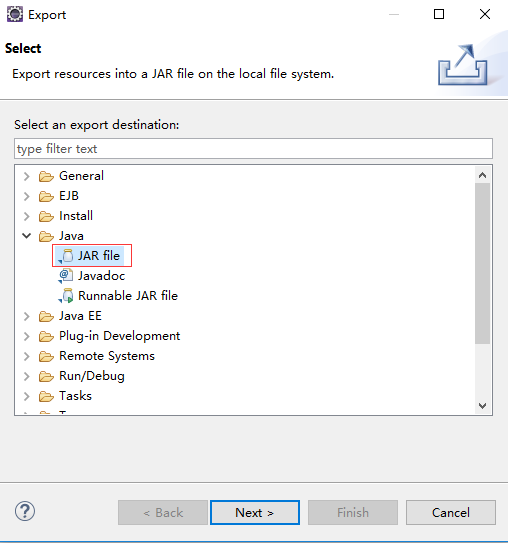
五 打包方法
第一步
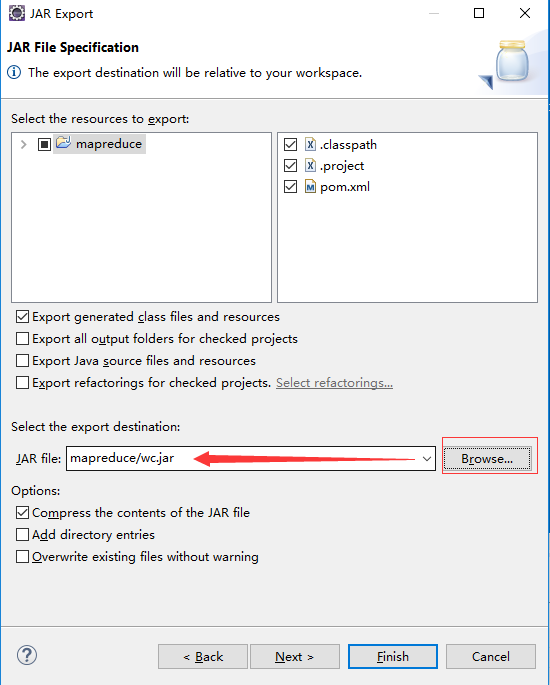
第二步
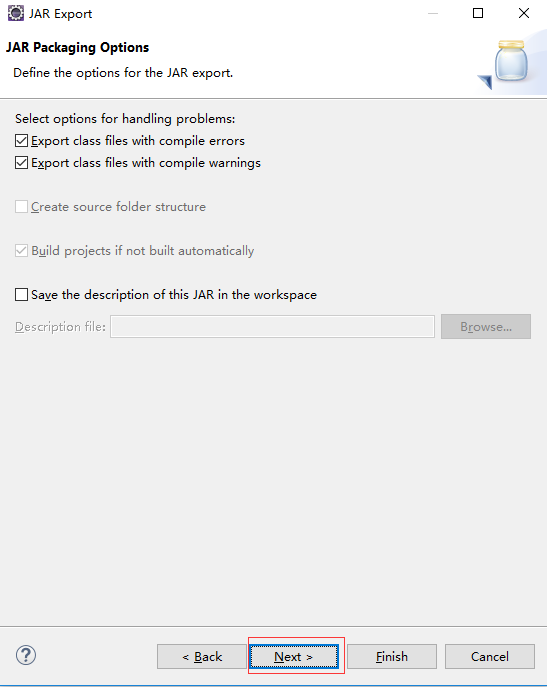
第三步
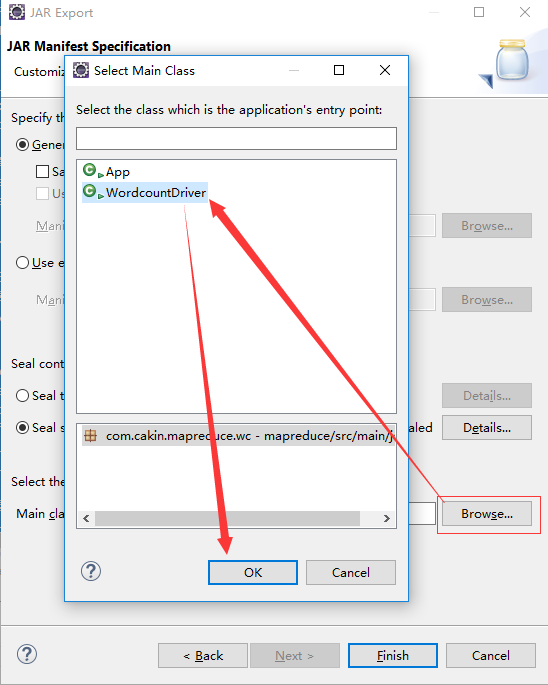
第四步
第五步
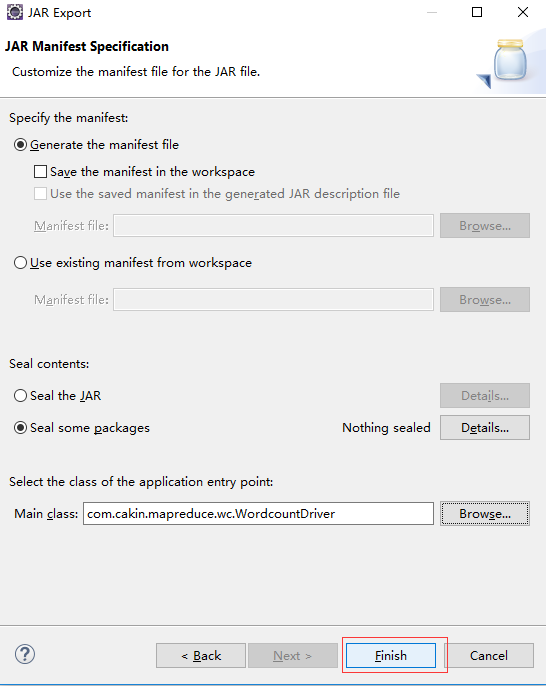
完成上面步骤后,在F:\Hadoop\workspace\mapreduce目录下会生成wc.jar文件
六 启动hadoop
[root@localhost sbin]# ./start-dfs.sh
Starting namenodes on [localhost]
localhost: \S
localhost: Kernel \r on an \m
localhost: starting namenode, logging to /opt/hadoop-2.7.4/logs/hadoop-root-namenode-localhost.localdomain.out
The authenticity of host '127.0.0.1 (127.0.0.1)' can't be established.
ECDSA key fingerprint is e8:13:79:55:21:e3:40:67:f2:fd:5d:76:ab:4a:88:86.
Are you sure you want to continue connecting (yes/no)? yes
127.0.0.1: Warning: Permanently added '127.0.0.1' (ECDSA) to the list of known hosts.
127.0.0.1: \S
127.0.0.1: Kernel \r on an \m
127.0.0.1: starting datanode, logging to /opt/hadoop-2.7.4/logs/hadoop-root-datanode-localhost.localdomain.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: \S
0.0.0.0: Kernel \r on an \m
0.0.0.0: starting secondarynamenode, logging to /opt/hadoop-2.7.4/logs/hadoop-root-secondarynamenode-localhost.localdomain.out
[root@localhost sbin]# jps
3394 NameNode
3514 DataNode
3674 SecondaryNameNode
3791 Jps
七 上传数据文件到HDFS
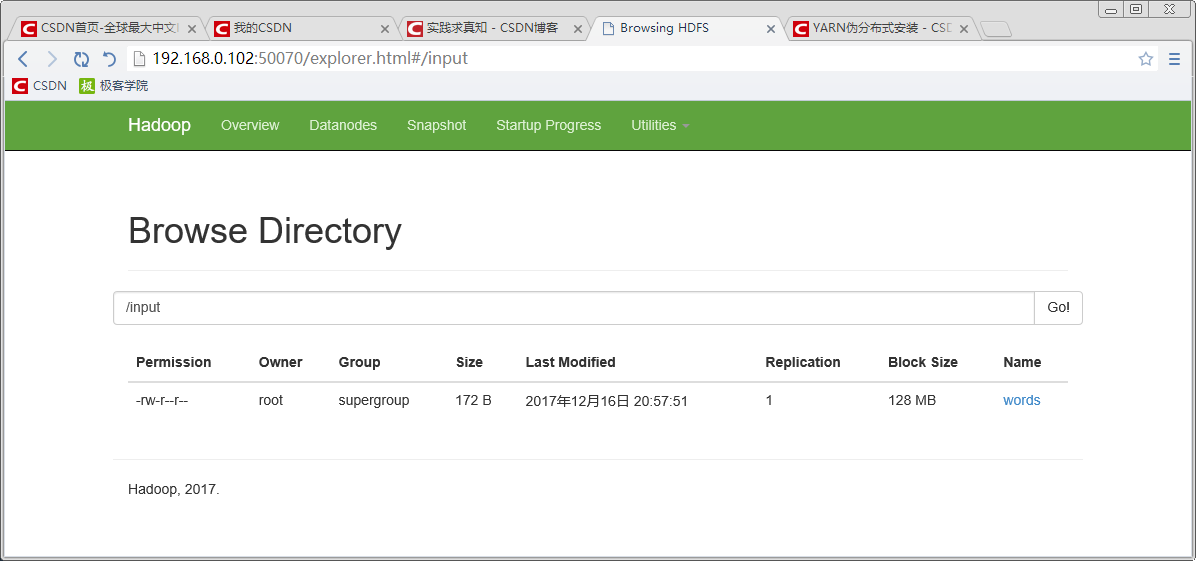
八 启动YARN
[root@localhost sbin]# ./start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop-2.7.4/logs/yarn-root-resourcemanager-localhost.localdomain.out
127.0.0.1: \S
127.0.0.1: Kernel \r on an \m
127.0.0.1: starting nodemanager, logging to /opt/hadoop-2.7.4/logs/yarn-root-nodemanager-localhost.localdomain.out
[root@localhost sbin]# jps
3394 NameNode
4423 ResourceManager
4520 NodeManager
3514 DataNode
3674 SecondaryNameNode
4671 Jps
九 上传程序文件
[root@localhost ~]# mkdir jar
[root@localhost ~]# cd jar
[root@localhost jar]# ls
wc.jar
十 运行程序
[root@localhost hadoop-2.7.4]# bin/yarn jar /root/jar/wc.jar /input /output
17/12/16 21:09:14 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
17/12/16 21:09:15 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
17/12/16 21:09:17 INFO input.FileInputFormat: Total input paths to process : 1
17/12/16 21:09:17 INFO mapreduce.JobSubmitter: number of splits:1
17/12/16 21:09:17 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1513429346141_0001
17/12/16 21:09:18 INFO impl.YarnClientImpl: Submitted application application_1513429346141_0001
17/12/16 21:09:18 INFO mapreduce.Job: The url to track the job: http://localhost:8088/proxy/application_1513429346141_0001/
17/12/16 21:09:18 INFO mapreduce.Job: Running job: job_1513429346141_0001
17/12/16 21:09:42 INFO mapreduce.Job: Job job_1513429346141_0001 running in uber mode : false
17/12/16 21:09:42 INFO mapreduce.Job: map 0% reduce 0%
17/12/16 21:10:02 INFO mapreduce.Job: map 100% reduce 0%
17/12/16 21:10:21 INFO mapreduce.Job: map 100% reduce 100%
17/12/16 21:10:24 INFO mapreduce.Job: Job job_1513429346141_0001 completed successfully
17/12/16 21:10:24 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=370
FILE: Number of bytes written=241931
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=270
HDFS: Number of bytes written=220
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=21560
Total time spent by all reduces in occupied slots (ms)=10084
Total time spent by all map tasks (ms)=21560
Total time spent by all reduce tasks (ms)=10084
Total vcore-milliseconds taken by all map tasks=21560
Total vcore-milliseconds taken by all reduce tasks=10084
Total megabyte-milliseconds taken by all map tasks=22077440
Total megabyte-milliseconds taken by all reduce tasks=10326016
Map-Reduce Framework
Map input records=4
Map output records=32
Map output bytes=300
Map output materialized bytes=370
Input split bytes=98
Combine input records=0
Combine output records=0
Reduce input groups=30
Reduce shuffle bytes=370
Reduce input records=32
Reduce output records=30
Spilled Records=64
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=204
CPU time spent (ms)=1300
Physical memory (bytes) snapshot=272658432
Virtual memory (bytes) snapshot=4160684032
Total committed heap usage (bytes)=139169792
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=172
File Output Format Counters
Bytes Written=220
十一 查看结果
[root@localhost hadoop-2.7.4]# hdfs dfs -cat /output/part-r-00000
1
78 1
ai 1
daokc 1
dfksdhlsd 1
dkhgf 1
docke 1
docker 1
erhejd 1
fdjk 1
fdskre 1
fjdk 1
fjdks 1
fjksl 1
fsd 1
go 1
haddop 1
hello 3
hi 1
hki 1
jfdk 1
scalw 1
sd 1
sdkf 1
sdkfj 1
sdl 1
sstem 1
woekd 1
yfdskt 1
yuihej 1
十二 参考

















 523
523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









