







 本文深入探讨了RNN的长期依赖问题,重点介绍了LSTM(长短期记忆网络)的结构,包括忘记门、保存门和生成门。通过相关公式解析了LSTM如何有效地处理序列数据,并提供了单层单向、单层双向和多层双向LSTM的模型代码示例。
本文深入探讨了RNN的长期依赖问题,重点介绍了LSTM(长短期记忆网络)的结构,包括忘记门、保存门和生成门。通过相关公式解析了LSTM如何有效地处理序列数据,并提供了单层单向、单层双向和多层双向LSTM的模型代码示例。
一句话,有时候单独拎出来难以理解,而放在整篇文章中,我们则容易通过联系上下文理解。
什么叫联系上下文理解,就是把前文信息联系结合到当前语句上,这也是RNN的关键。
基本概念:维基百科
RNN(Recurrent Neural Networks)
Rnn本质是一个循环神经网络结构,将其展开,会得到一个序列结构,上一次的输出会作为下一次的输入(即前面的输入将会对后面的输入产生影响)。
这种链式的特征揭示了 RNN 本质上和序列相关,因而很适合处理语音,文本,这种序列数据。
基本概念:维基百科
长期依赖问题
RNN关键点是能够连接先前的信息到当前任务上,如通过前文推断当前语句含义。但是,当相关信息和当前语句间隔过大时候,RNN将难以学习到远距离信息。

LSTM结构
LSTM的主要结构在于使用了三个门过滤掉不需要的记忆,提取需要的记忆,产生新的记忆。让我们围绕这三个门进行进一步分析。
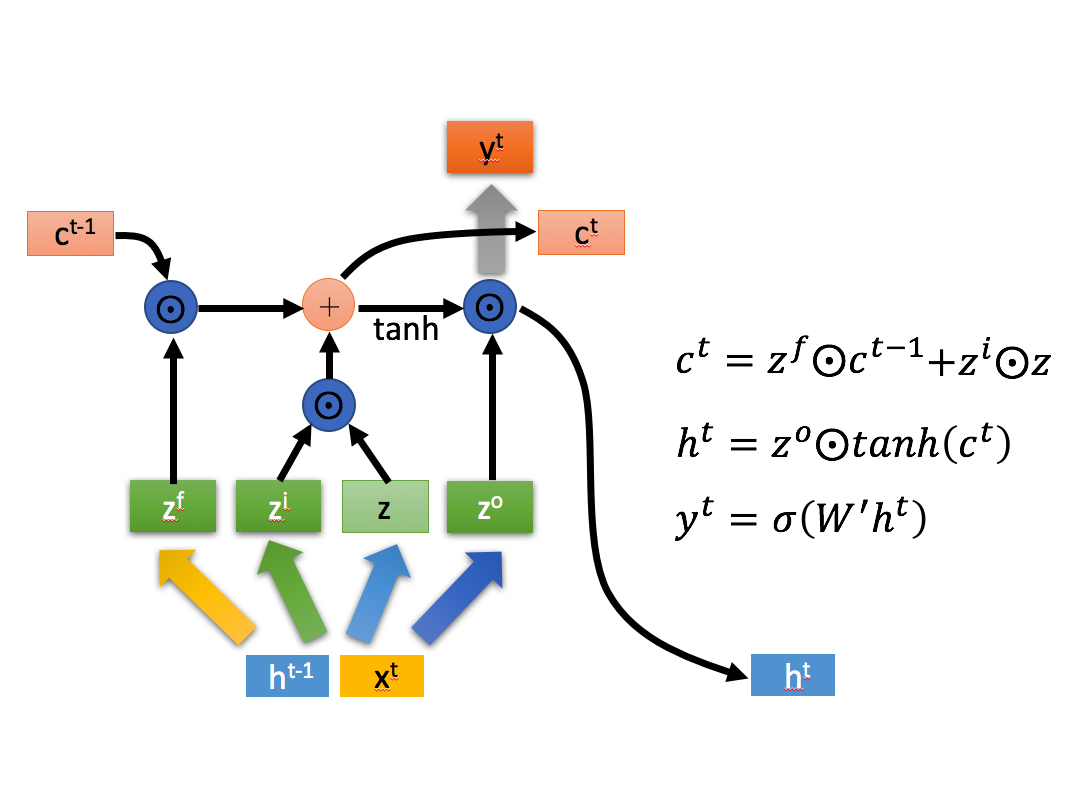
相关公式:

LSTM:忘记门
Lstm的第一步是决定要从单元格状态丢弃什么信息

忘记门主要将前信息与现信息做线性分类,采用sigmoid将值控制在[0,1]之间,将值与前状态相乘,这样就可以确定哪些状态被留下来,哪些被遗忘。
保存门

保持门具有两个分支,一个分支与遗忘门相似(参数不同),同样将值控制在[0,1]之间;另一个分支使用的是tanh激活函数,将值控制在[-1,1]之间,这样做是为了选择出需要的信息,两相乘后提取出现信息状态。
生成门


最后将前2个门的结构相加,便得到了最后产生的信息:C
而生成门的主要是为了生成最后的结果,同样的方法处理后,将前面得到的C进行tanh激活函数处理(主要为了保证数据大小的一致性),两者相乘得到最后结果。
结论
综上所述,我总结出一个新的理解方式:
可以看到LSTM的输入为:状态0,信息0(由前输出和输入组成)LSTM输出:状态1,信息1.
- 状态1 = 分类遗忘(状态0) + 分类提取(信息0)
- 信息1 = 分类提取(状态1)
分类器:sigmoid 数据标准化:tanh
LSTM 模型代码解释:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM,Embedding,Dense,Flatten,Bidirectional,Dropout
from config import vocabulary,embedding_dim,word_num,state_dim
#单层单向模型
def Lstm_model():
model = Sequential()
#Embedding函数表示将向量化,嵌入特征。
#vocabulary:字典中词的数量
#embedding_dim:嵌入向量的维度
#input_length:一句话的长度
model.add(Embedding(vocabulary,embedding_dim,input_length=word_num))
#model.add(LSTM(state_dim,return_sequences=False))
model.add(LSTM(state_dim,return_sequences=True))
model.add(Flatten())
model.add(Dense(1,activation=‘sigmoid’))
model.summary()
return model
#单层双向模型
def Bi_Lstm():
model = Sequential()
model.add(Embedding(vocabulary,embedding_dim,input_length=word_num))
model.add(Bidirectional(LSTM(state_dim,recurrent_dropout=0.1)))
model.add(Dropout(0.25))
model.add(Dense(64))
model.add(Dropout(0.3))#选择性失效
model.add(Dense(1,activation=‘sigmoid’))
model.summary()
return model
#多层双向模型
def Stacked_Lstm():
model = Sequential()
model.add(Embedding(vocabulary,embedding_dim,input_length=word_num))
model.add(Bidirectional(LSTM(state_dim, return_sequences=True)))
model.add(Bidirectional(LSTM(state_dim, return_sequences=False)))
model.add(Dense(1,activation=‘sigmoid’))
model.summary()
return model
if name == ‘main’:
#model = Lstm_model()
model = Stacked_Lstm()
#model = Bi_Lstm()

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









