







前言:
前面对参数进行估计,但是估计出来有不同的参数,
这个参数是否有效,从下面几个给出了答案
在逻辑回归,通过不同的样本 Train 得到不同的权重系数
可以对权重系数进行归一化,然后通过求各个维度的权限系数的分布函数
对所有维度的分布函数进行乘积。
综合得到概率最高的权重系数组合
目录
1: 无偏性(数学期望)
2: 有效性(方差)
3: 均方误差
4: 相合性(大数定理)
一 无偏性
参数的估计量
如果 ,则称
为
的无偏估计
例 1 :
则 为
的无偏估计
例2 均匀分布 ,
为未知参数,
2.1 的矩估计是无偏估计
证明:
总体矩:
参数估计:
样本矩替代总体矩
参数估计:
所以是无偏估计
2.2 极大似然估计是无偏的吗?
该值要最大,要最小,其最小值为
不是无偏估计,但是当n趋近无穷的时候,是无偏估计,所以是渐进无偏估计。
二 有效性
如果在无偏性的基础上,参数估计的方差小,则其更有效
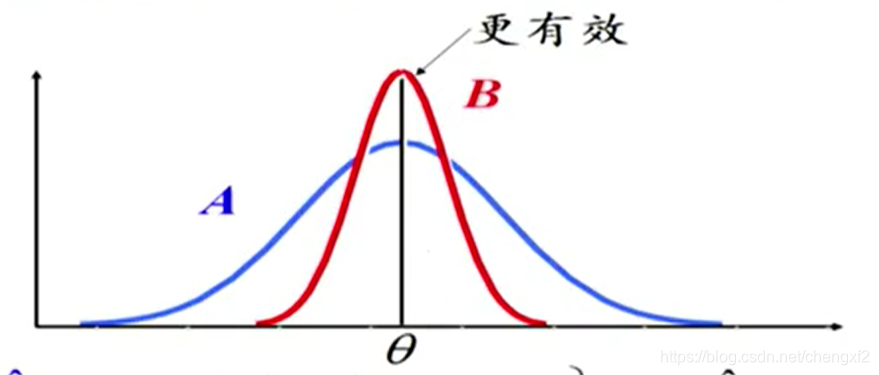
总体 为样本,
试问哪个参数更有效
其中
所以
似然估计更有效
三 均方误差
是
的点估计,方差存在。
如果是无偏估计
相对于之前的,它不需要是无偏性的
应用: 梯度下降中的损失函数
例子: 样本方差和样本二阶中心矩
分别作为正态总体
进行评估
解:
因为 ,所以MSE
因为
所以
因为
所以
因为
所以
综合得到
所以均方误差 优于
,但是如果样本容量小的时候
由于偏差大,选择
四 相合性
设参数为参数
的估计量
如果, 则成为相合估计
原理: 切比雪夫不等式
4.1 例: 总体 为样本,
求证都是相合估计
证明:
1 因为 ,所以
为相合估计
2
根据切比雪夫不等式,当n趋近无穷的时候,为相合估计

















 5109
5109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









