






介绍
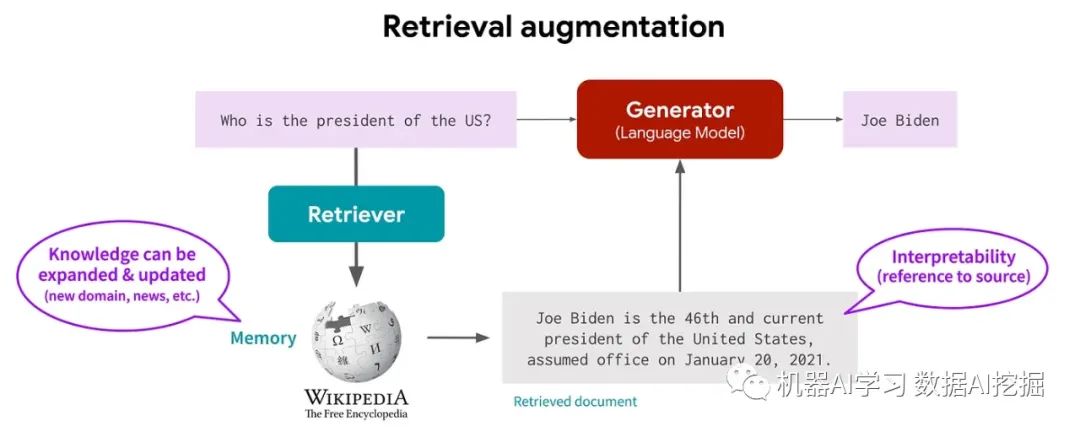
RAG(Retrieval Augmented Generation)是一种突破知识限制、整合外部数据并增强上下文理解的方法。
由于其高效地整合外部数据而无需持续微调,RAG的受欢迎程度正在飙升。
让我们来探索RAG如何克服LLM的挑战!
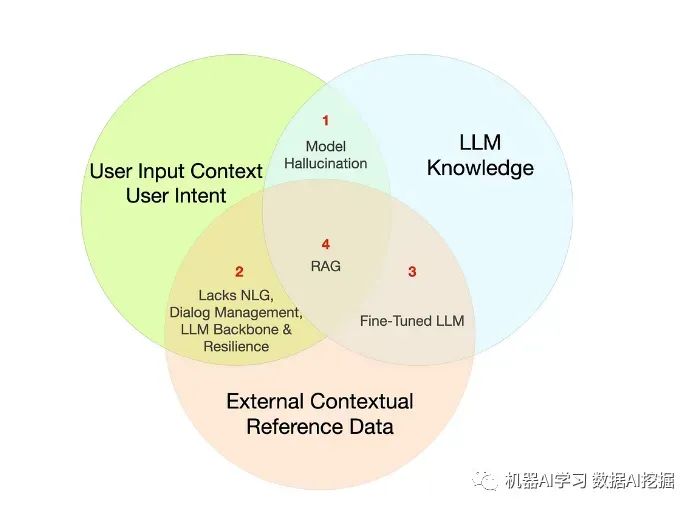
LLM知识限制大型语言模型面临与知识的准确度和时效性相关的几个挑战。其中两个常见问题是幻觉和知识断裂。
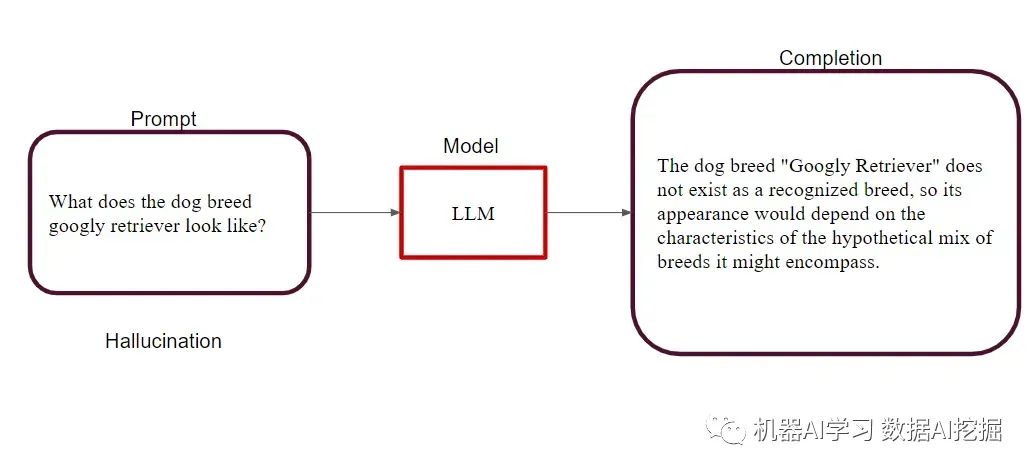
幻觉:当模型自信地产生一个错误响应时发生。例如,如果一个模型声称“googly retriever”是一种真实的狗品种,那么这就是一种幻觉,可能导致误导性的信息。
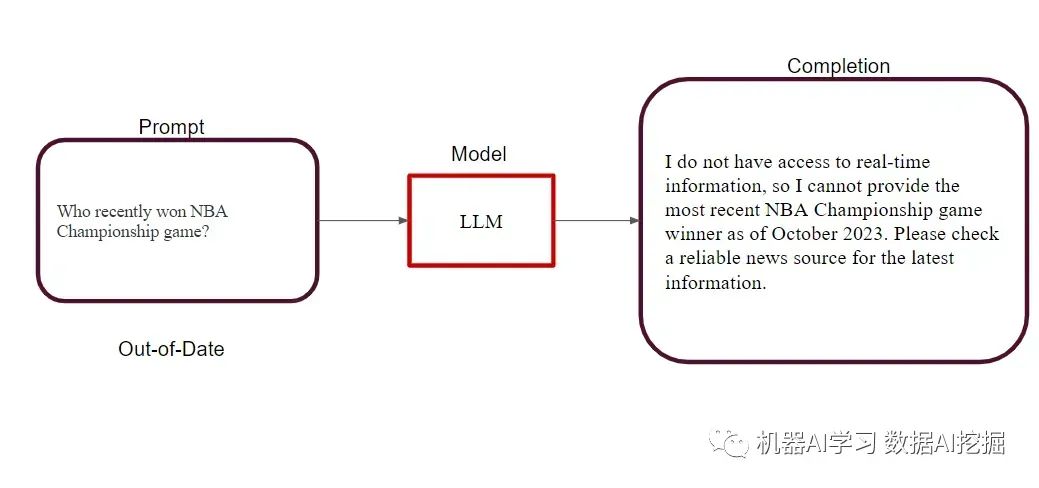
知识断裂:当LLM返回的信息根据模型的训练数据已经过时时发生。每个基础模型都有一个知识断裂,意味着其知识仅限于训练时可用的数据。例如,如果您询问模型关于最近一次NBA总冠军的获胜者,它可能会提供过时的信息。
RAG提供了一种缓解这些挑战的技术。它使您能够为模型提供访问外部数据源的权限,通过引入事实上下文来减轻幻觉,并通过整合最新信息来克服知识断裂。
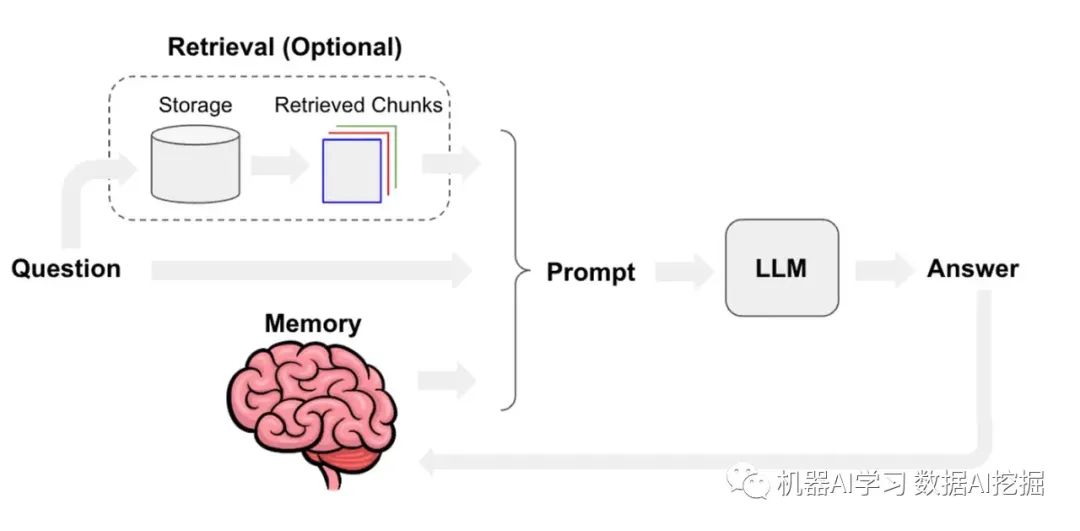
Retrieval-Augmented Generation(RAG)Retrieval-Augmented Generation(RAG)是一个多功能框架,使大型语言模型(LLMs)能够访问其训练数据之外的外部数据。RAG不局限于单个实现,它适应不同的任务和数据格式的多种方法。
它使LLM能够在运行时利用外部数据源,包括知识库、文档、数据库和互联网。这对于使用外部数据增强语言模型非常有价值,填补了其训练数据中未涵盖的知识差距。
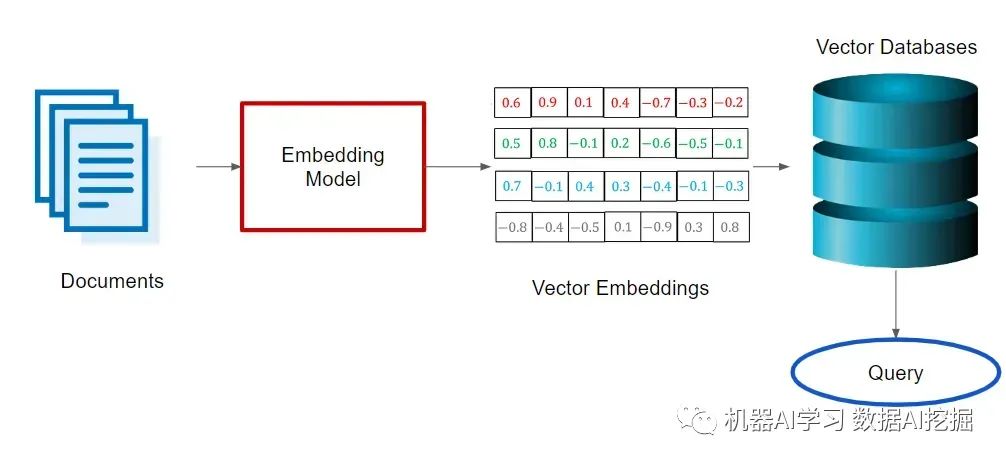
为了高效地从文档中检索信息,一种常见的做法是使用捕获语义意义的嵌入向量将它们索引到向量数据库中。此外,对大型文档进行分块以提高相关性并减少噪声,最终通过提供特定的上下文信息来增强模型的响应。
RAG框架
RAG框架中有两个关键模型:
RAG-序列模型:该模型利用相同的检索到的文档生成完整的序列。它将检索到的文档视为单个潜在变量,通过对前K个进行近似处理,通过边缘化得到序列到序列的概率。在此方法中,使用检索器检索前K个文档,生成器计算每个文档的输出序列概率。然后通过边缘化将这些概率组合起来。RAG-标记模型:在此模型中,可以为每个目标标记绘制不同的潜在文档,使生成器在产生答案时可以选择多个文档的内容。类似于RAG-序列模型,它检索前K个文档,然后为每个文档生成下一个输出标记的分布。对于每个输出标记重复此过程,并进行相应的边缘化处理。

此外,RAG还可以用于序列分类任务,将目标类别视为单个序列目标。在这种情况下,RAG-Sequence和RAG-Token模型变得等效。
RAG的组件检索器:检索器(DPR)根据查询和文档索引检索相关文档。检索组件基于密集段落检索(DPR),并采用具有从BERT派生的密集和查询表示的双编码器架构。使用最大内积搜索(MIPS)算法选择具有最高先验概率的前K个文档。生成器:基于BART-large的生成器组件负责生成序列。它通过简单地连接输入和检索到的内容来结合它们。
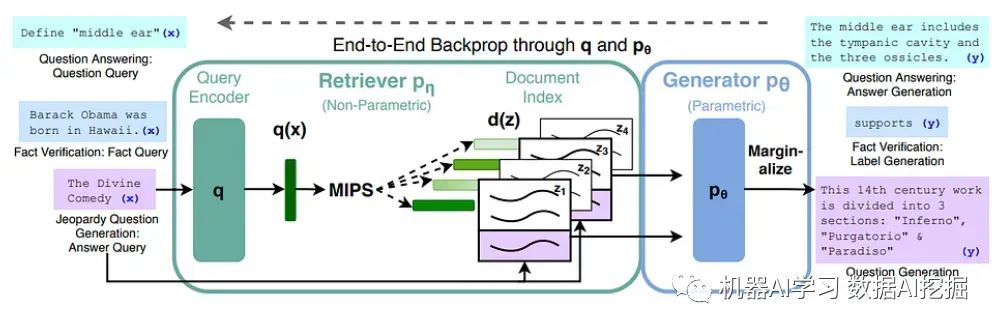
训练阶段在训练过程中,检索器和生成器共同进行训练,而无需直接监督要检索哪个文档。训练目标最小化每个目标的负边际对数似然。
解码阶段在解码阶段,RAG-Sequence和RAG-Token模型需要不同的方法。RAG-Token使用标准的自回归序列生成和束搜索解码器。相比之下,RAG-Sequence对每个文档运行束搜索,并使用生成器概率对假设进行评分。对于较长的输出序列,采用高效的解码方法以避免过多的前向传递。
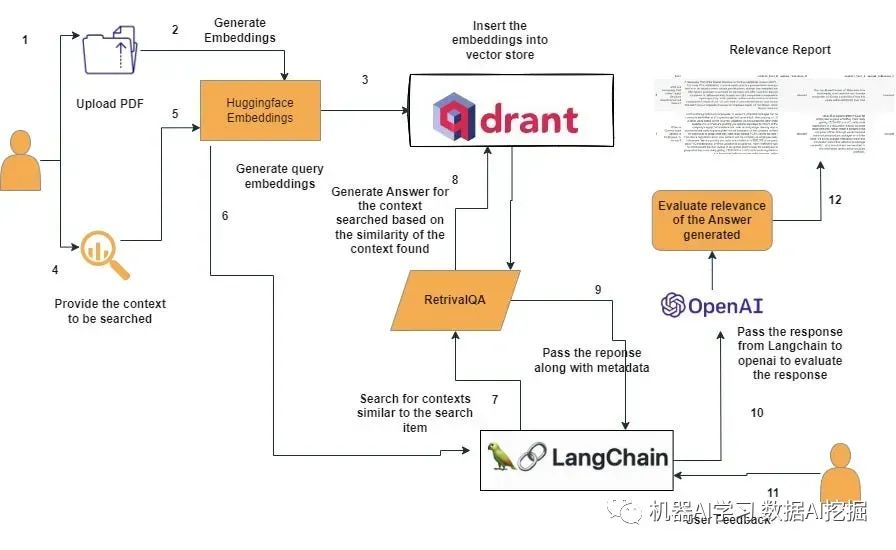
RAG的实施和编排实施RAG工作流程可能很复杂,涉及从接受用户提示到查询数据库、分块文档以及协调整个流程的多个步骤。
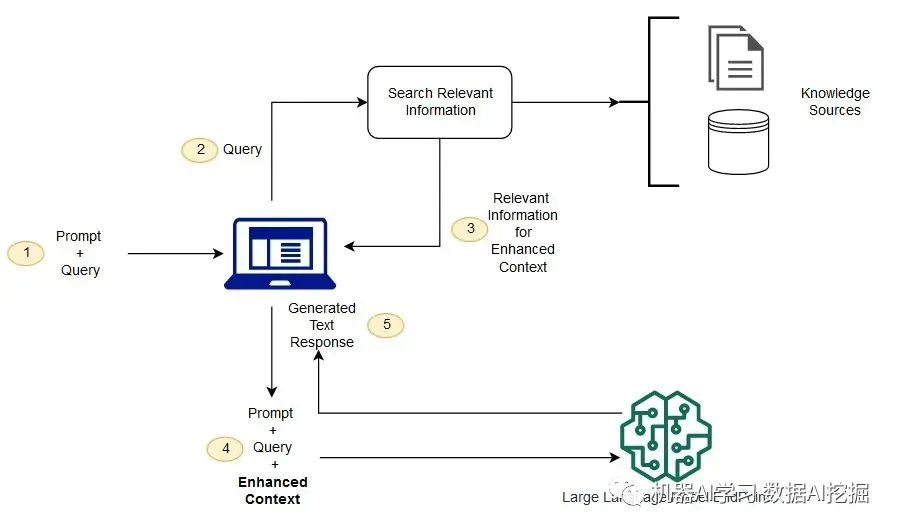
像LangChain这样的框架通过提供与LLMs和RAG等增强技术一起工作的模块化组件来简化此过程。LangChain包括用于各种输入格式的文档加载器、用于拆分文档的文档转换器以及其他组件,以简化基于LLM的应用程序的开发。
使用LangChain的RAG工作流程LangChain是一个全面的自然语言处理平台,在使RAG模型易于访问和高效方面发挥着关键作用。以下是LangChain如何适应RAG工作流程的方式。
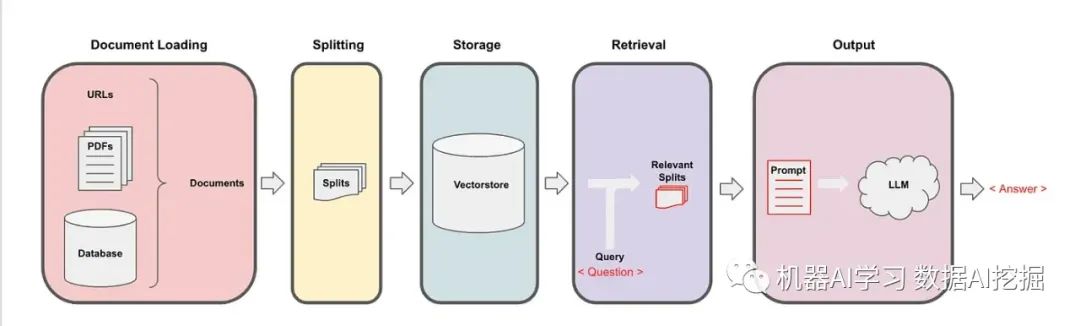
文档加载器和转换器LangChain提供了各种文档加载器,可以从各种来源获取文档,包括私有S3存储桶和公共网站。这些文档可以是各种类型,如HTML、PDF或代码。文档转换器组件负责准备这些文档以进行检索,包括将大型文档拆分为更小、更易于管理的块。
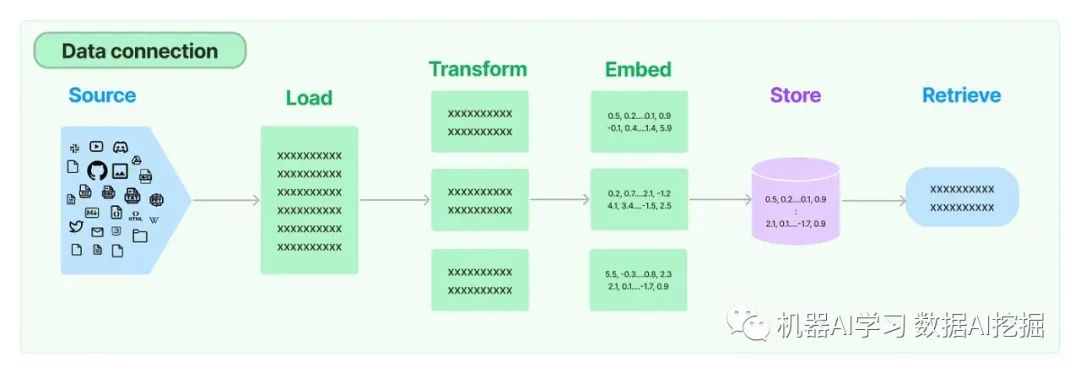
文本嵌入模型LangChain中的文本嵌入模型旨在与各种文本嵌入提供商和方法进行接口,包括OpenAI、Cohere和Hugging Face。这些模型创建了文本的向量表示形式,捕捉其语义含义。这种向量化使得相似文本的高效检索成为可能。
向量存储随着嵌入技术的出现,需要高效的数据库来存储和搜索这些嵌入。LangChain提供了与超过50个不同的向量存储的集成,使您可以轻松选择最适合您需求的一个。
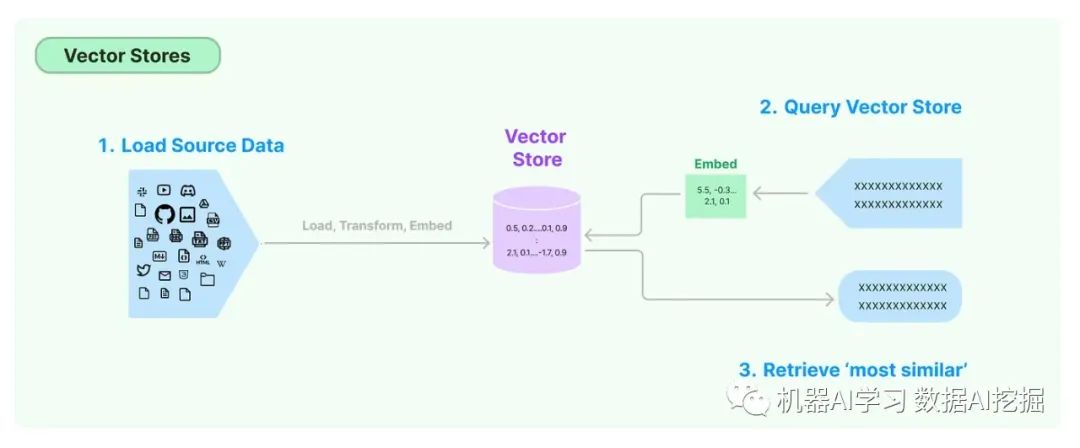
检索器LangChain中的检索器提供了检索与查询相关的文档的接口。这些检索器可以使用向量存储作为其骨干,但还支持其他类型的检索器。LangChain的检索器提供了自定义检索算法的灵活性,范围从简单的语义搜索到提高性能的高级方法。
缓存嵌入LangChain的“缓存嵌入”功能允许将嵌入存储或临时缓存,减少了重新计算的需求,并提高了整体性能。
与Hugging Face的集成Hugging Face是一个领先的基于变压器模型的平台,提供预训练模型,包括RAG中使用的模型。LangChain与Hugging Face的模型无缝集成,使您能够针对特定任务进行微调和调整。
结论
检索增强生成(RAG)模型代表了大型语言模型领域的突破性进展。
LangChain和类似的框架使得RAG和其他增强技术更容易实施,能够快速开发利用LLMs的潜力的应用程序。
这些技术之间的协同作用为知识密集型语言任务领域的创新开辟了令人兴奋的可能性。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 3285
3285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









