






导读: 本文将简要介绍推荐模型的发展历史,现状,和下一步的研究趋势。并重点介绍针对embedding数据的模型训练及优化。主要包含以下几大部分内容:
- CTR预测模型(CTR Models)
- 连续值处理(Continuous Feature)
- 交叉特征建模(Interaction Modelling)
- 大Embedding模型训练(Distributed Training)
- 总结和展望
01
CTR预测模型(CTR Models)
1. 推荐模型的发展
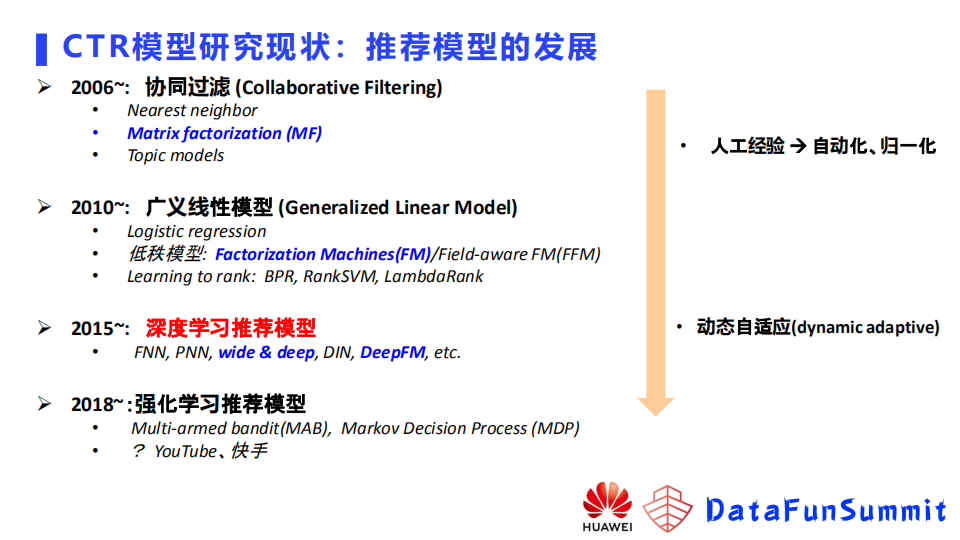
首先简要介绍下推荐模型的发展。以06年为起点,在06年时,更多的是以协同过滤(Collaborative Filtering)的方法来做推荐,还包括最近邻方法(Nearest neighbor),矩阵分解(Matrix factorization - MF)的方法,以及主题模型(Topic models)的方法。
10年以后,很多公司开始在业务中引入使用广义线性模型(Generalized Linear Model)这一系列的模型,包括逻辑回归(Logistic regression)、低秩模型如因子分解机FM(Factorization Machines)、基于域信息的因子分解机FFM (Field-aware Factorization Machine),以及一些learning to rank 的方法,如BPR, RankSVM,lambda Rank等。
15年以后,CNN在视觉任务取得了一些突破性的进展,深度学习模型在业界得到了很大的关注,很多模型被提出。例如大家熟知的FNN、PNN、DIN、谷歌提出的wide&deep,以及华为的deepFM等等。
18年以后,研究开始倾向于向强化学习这一类推荐模型发展。18年之前已经有像多臂老虎机这种方法在使用,但是AlphaGo击败围棋世界冠军这次事件引起了业界极大关注,推荐任务的研究也开始转向基于强化学习的推荐模型
整体的发展趋势就是模型逐渐从人工经验向自动化,深度模型的归一化,越来越聚焦到某一类模型,期望引入自适应模型来解决业务问题。
2. 推荐系统中的核心问题
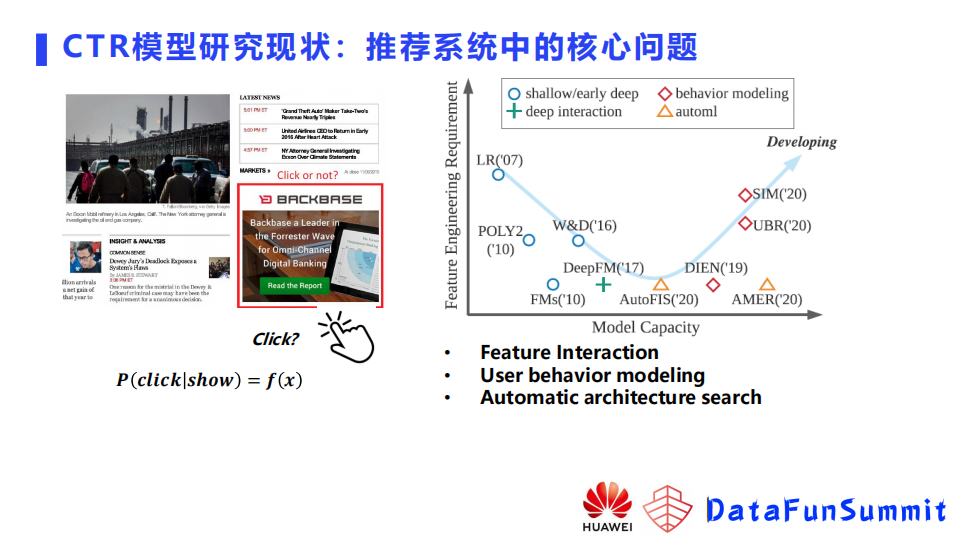
点击率预测模型是推荐系统中的核心问题。举个例子,如上图所示是一个网页,网页上有一些内容,也有一些位置留给广告,广告对于一个网站是比较大的收入来源。展示什么广告给用户,就需要预测用户在特定页面点击广告的概率,点击率预测就是执行这样一个任务。预测的准确与否决定了整个推荐系统或者说广告系统的收益以及用户体验。
在2021年IJCAI上面有这样一篇Survey论文,是上海交通大学张伟楠老师和华为诺亚实验实的联合工作,将深度学习时代的点击率预测模型分为了三类:
- 第一类就是基于组合特征挖掘的模型;
- 第二类针对用户行为的模型;
- 第三类是自动架构搜索的模型。
① 用户行为挖掘
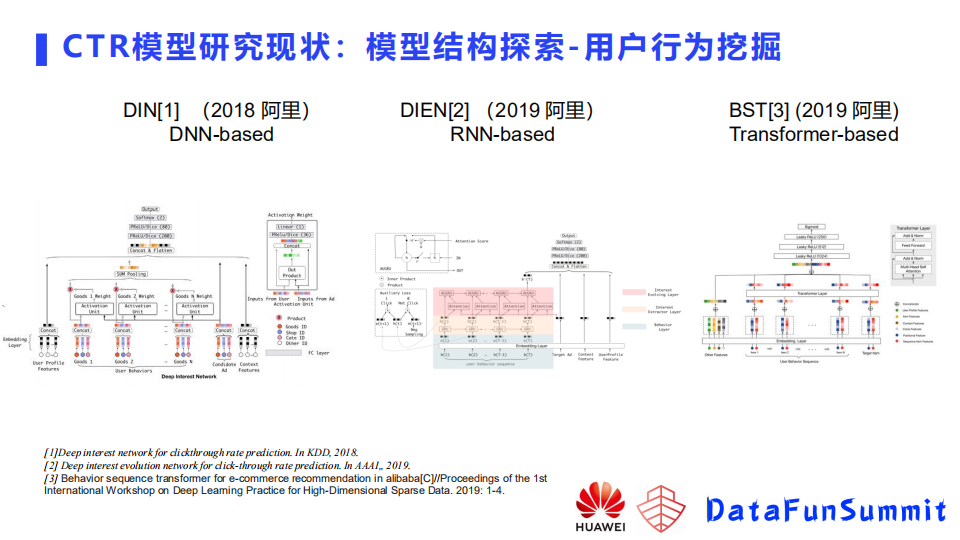
这块从论文来看做的比较早的是阿里的一些工作,包括阿里妈妈团队在2017-2018做的基于dnn的Deep interest network-DIN,是用dnn里面的pooling,将用户的历史行为做了一些建模。这样可以把用户的历史兴趣体现在模型中,从而得到更好的预测效果。2019年,阿里妈妈团队又在DIN的基础上增加了一个RNN模块,推出DIEN模型。DIN只是把用户行为做pooling,把过去历史行为都等同来看,而没有去关注行为之间过去历史之间的序列关系。所以DIEN 模型在user modeling加了一个RNN模型,从而可以拟合序列关系。同年,阿里另一个团队推出了BST模型,将transformer用在了用户行为 modeling模块里面,目前有很多公司也在用,包括去年快手发布的万亿参数模型,也是用到了transformer来拟合用户的长期行为。
② 组合特征挖掘
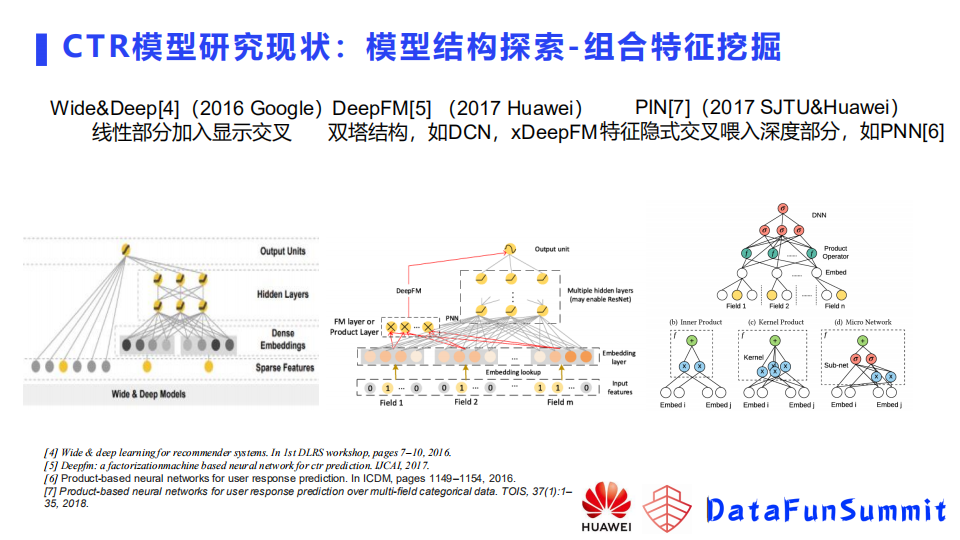
另一类是组合特征挖掘类模型。我个人认为可以分为三类,第一类就是像wide&deep模型,谷歌最先提出,他们在模型里面加入了显示的交叉,也就是特征之间笛卡尔相乘之后构建出来新特征,加入到线性部分,这样模型会记住这些特征,当下次组合特征出现的时候,会直接把它的权重取出来做预测。第二类模型是DeepFM这类的模型,可以称为双塔模型、双塔结构,像DCN,xDeepFM以及后边的很多模型,都属于这类模型,这类模型是在dnn之外以及线性之外,加了基于分解的模块,用来建模两个特征之间的组合关系。两个特征的组合关系,是用一个向量的乘法或者是一些复杂的结构来拟合的,建模完这个关系之后,会直接把输出喂到最终输出中,而不会去神经网络。与之相反的是第三类如PNN这种网络,也会利用分解模式构建特征之间的组合关系,但是它构建完组合关系之后,会再把输出喂入到模型MLP中,让MLP来再度拟和这些特征之间的关系。
3. 结构创新带来的收益越来越小,如何突破?
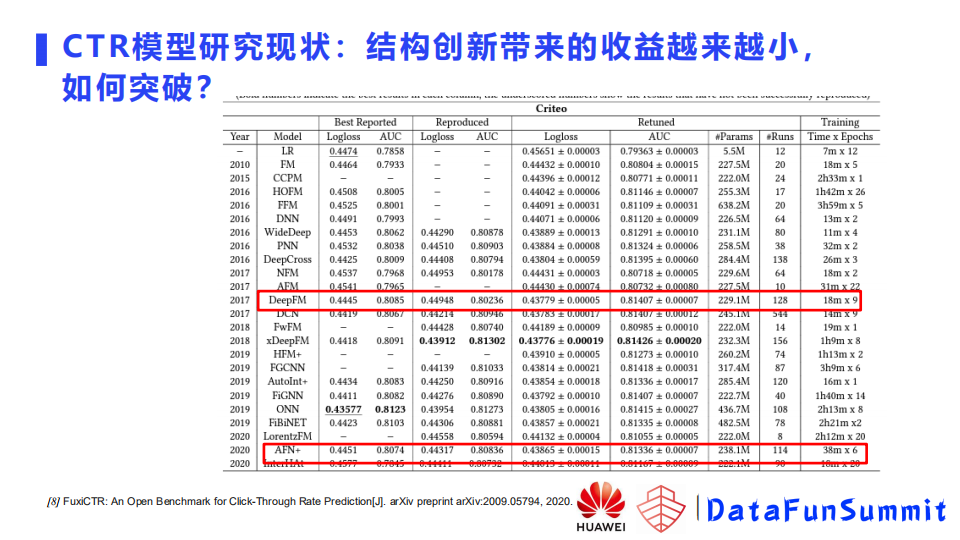
如上图中展示的一些实验结果,是华为诺亚实验室20-21年的一个工作成果,已经公开发表(FuxiCTR: An Open Bench mark for Click-Through Rate Prediction[J]. arXiv preprint arXiv: 2009.05794, 2020.)。论文对15年至今比较有代表性的深度学习点击率预测模型进行复现,在几个公开数据集上进行调参、再调优。实验结果显示,模型创新,结构创新带来的收益越来越小。比如图中DeepFM和AFN+,公开数据集结果显示结果差距不大。当然并不是说这些年模型没有发展,业界使用模型做实验时,很多时候都是用自己私有的数据集,数据集会有不同的特点,模型在这样的私有数据集会有收益,并且会针对数据集专门改造模型。还有就是比如17年的时候很多模型调参的trick没有发现,现在将这些trick带入到17年的模型进行训练,补足了以前模型的短板,所以看不到大的差异。相对于模型创新,如何结合数据设计模型以及如何找到一些针对推荐搜索等场景比较通用的调参策略,是一个不错的突破点。
4. 如何更高效的利用数据?
在此基于组合特征建模和用户行为建模提供两个方向。这几个工作也是近两年发表在KDD和SIGIR上的一些工作。
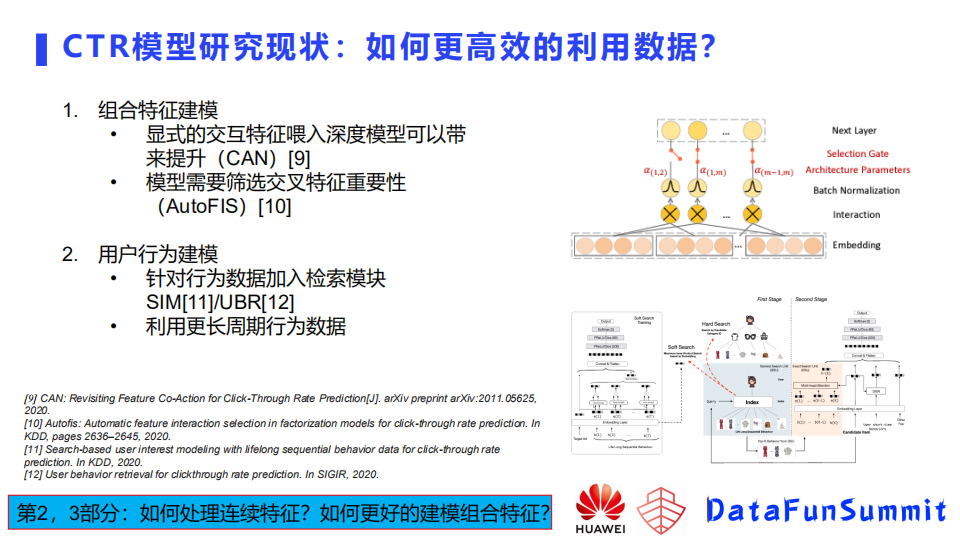
首先是组合特征建模方向,很多深度模型建模的时候,使用显示特征作为输入,这样一是会带来人工的特征工程,二是因为特征的稀疏,直接使用可能学习不好。而像阿里的CAN模型,并没有使用显示的特征,而是将显示的交互特征(组合特征)喂入模型, 带来的提升也是很明显的。怎么设计特征或者说怎么选择哪些特征做显示的喂入,哪些做隐式的交叉也是一个研究方向。另外,很多这种基于交叉基于分解的建模方式都是将所有的特征中间都去做交叉建模,但并不是所有特征都适合这种交叉。哪些可以交叉,哪些交叉后会带来负向的效果,这需要模型去自动选择或者人工去不断尝试。
上图展示了华为诺亚方舟实验室在2020年发表的AutoFIS模型,该模型针对交叉特征加了一组参数,用来自动去学哪些特征重要,哪些特征不重要。通过第一阶段的搜索,筛选出重要特征,把不重要的去掉,再重新输入到模型,这样做效果有明显提升。
第二个方向是用户行为建模。怎么更高效利用数据呢,其实很多工作也提到了,那就是用更长周期的行为数据;但是利用更长周期的行为数据,会带来两个问题,第一个问题就是数据序列会很长,建模时它的参数量会很大,而且不容易训练,另一个问题是可能只是一小部分的用户行为序列很长,其他大多数用户行为序列很稀疏,从而造成模型训练困难。
针对这些问题,阿里以及上海交通大学张伟楠老师分别发表了类似的工作:SIM和UBR。这两个工作想法类似:在行为数据中加入检索模块。如上图所示,用户的行为进来之后,通过一个行为建模的模块,比如RNN或者是transformer,就会得到一个用户的embedding,再和其他的特征一起注入到模型去做预测。这里的检索基于一个target,即预测目标,去对用户的行为做了一个筛选或者加权。基于这样的操作,模型会有很明显的提升。此外,针对如何更高效利用数据,本报告会介绍华为诺亚方舟实验室最近两个工作,如何去处理连续特征和更好的建模组合特征。
5. 如何处理大Embedding?
推荐模型的研究,还有一个方向就是怎样去处理大embedding。分两个方面来看,一方面就是怎样把embedding变小,也就是将embedding压缩;另一方面就是怎么用更新的分布式架构去更高效更低成本的去训练大embedding。
压缩方法的话也有几个分类,这里简单提几个比较有趣的工作,第一个就是twitter在Recsys 2021发表的Double hash的方法。这种方法首先把特征分成了高频和低频,因为高频特征相对比例比较小,给每一个高频特征分配一个独立的embedding,它所占的空间也不是很大。对于低频特征,使用Double hash方法进行压缩,该hash方法是为了尽可能地减少冲突。第二个工作是百度在SIGMOD2021发表的一篇基于int16训练Embedding参数。直接基于低比特参数进行训练模型十分挑战。第三个工作比较偏探索,是Google发表在KDD2021上的DHE模型,去掉了Embedding Table。
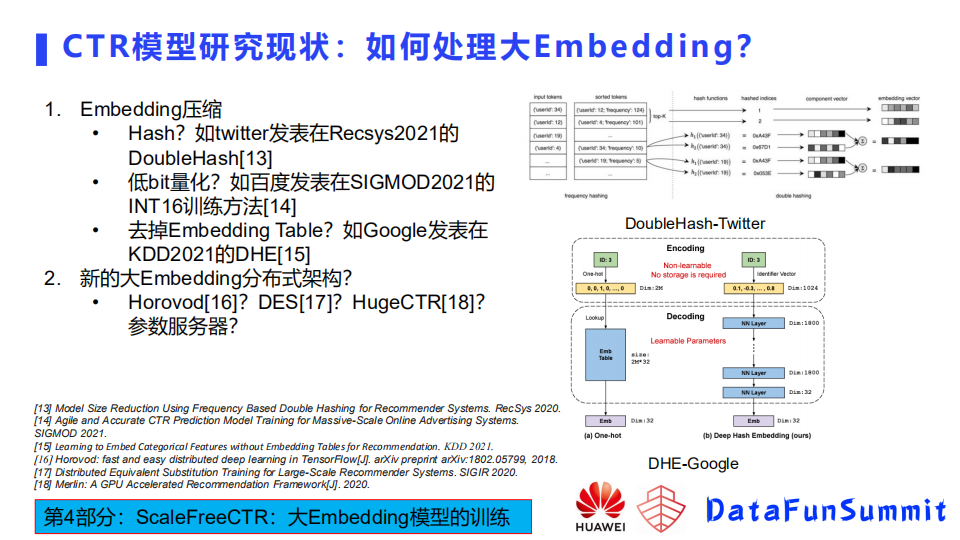
如上图所示,这个模型里面左侧是传统的embedding的处理方法,对一个特征进行编码,得到一个ID,然后用ID去一个大的Embedding table里面查表,得到它对应的Embedding。这种做法需要存一个大的Embedding,假设特征是亿级别的,那这个table可能是数百GB,维护这样一个Embedding table和训练模型是比较困难的。谷歌的DHE基于原始输入,用了1024个hash函数对数据做了一个硬编码,但函数怎么设计,没有提到,只是给了一个简要的指导,基于它硬编码之后的1024维输出,会再通过一个多层的网络去恢复出来一个Embedding,也就是说他认为1024维的hash函数进行编码加上多层神经网络即可恢复出Embedding table的参数。其在矩阵分解的一些模型上做了实验,实验效果显示精度没有损失太多。
另外一个方向的就是新的大Embedding分布式训练架构。这里的话我们最熟知的,用的最多的可能就是基于GPU这种Horovod去数据同步。腾讯发表于SIGIR2020的DES通过模型结合硬件设计了一个分布式的方案。英伟达提出基于cude直接写了一个HugeCTR,当然还有很多其他工作,后面的第四部分会介绍华为诺亚方舟实验室的ScaleFreeCTR模型,简单介绍一下这几种训练方式的一些不同。
02
连续值处理(Continuous Feature)
下面介绍华为的AutoDis,这个工作已经在KDD2021发表。熟悉深度模型的同学可能很清楚,我们的模型基本是服从Embedding+MLP。已有工作更多的是聚焦在怎么去设计网络的架构,在特征组合部分去设计架构,目的是为了更好的去捕捉显式或者隐式的交叉,但是特征的embedding,尤其是针对连续特征的embedding的研究是比较少的。
下面对现有的相关工作做了一些总结。
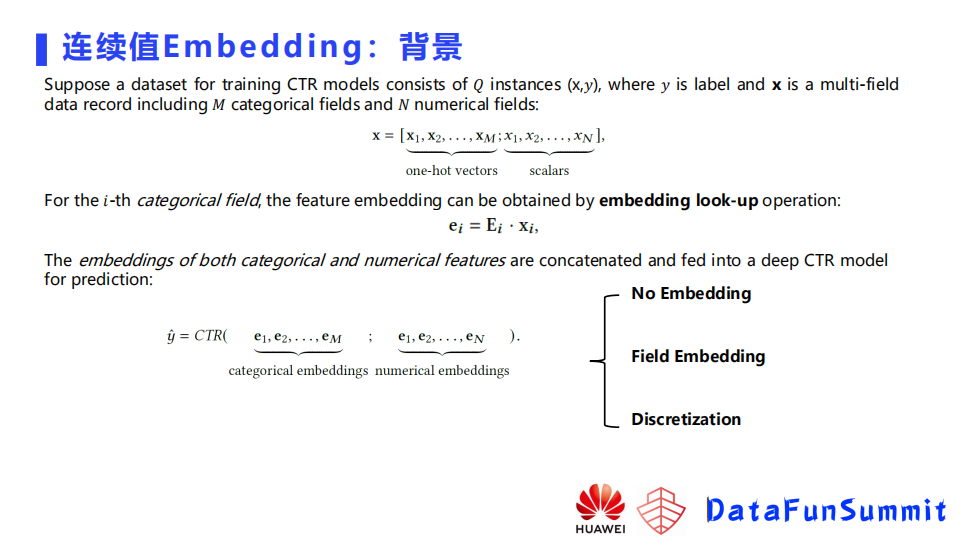
如上图是一种对离散特征的处理方法,它就是做了one-hot的编码,然后去做Embedding lookup。对于连续特征的处理方法,调研发现主要分为三类,第一类就是不使用Embedding,把原始值做一些变化,或者是归一化后输入到模型。第二类是Field Embedding,是给每个域一个Embedding。第三类是把连续特征离散化,之后把它当成离散特征来处理。
第一种方法,No Embedding。这里介绍几个模型的用法,第一个是wide&Deep,在它的介绍里面,使用的是原始值,另外一个是谷歌的YouTubeNet,它会对原始值做平方开根号这些变换。另一个是facebook DLRM模型,对连续值的处理方式是把所有的连续值输入到一个神经网络,然后通过神经网络把它压缩到一个embedding维度大小的一个向量上,然后将Embedding和其他离散特征Embedding Concat起来,再做后面根据它的模型去做不同的计算。京东的DMT模型,他们的网络是使用了归一化的输出,这种方法表示能力比较弱,因为它这里其实没有对原始的延续特征做一个很好的表示。
第二种处理连续值的方法是Field Embedding,每个域有一个Embedding。某个域的Embedding是该域的一个连续值,乘上它的域的Embedding。这类方法的问题是表示能力比较弱,然后不同值之间是一个线性的关系。
第三类的方法就是离散化。离散化可以有很多方法,比方说等频、等距和取log,或者基于树的模型去做一个预训练。但这类方法有两个问题:首先,就是它是两阶段的,离散化的过程不能端到端优化;另外,有一些边界的问题,如下图所示的例子,一个年龄特征,假设我们按40,41来分,40以下的我们称之为青年,41以上的成为中年,其实40和41,它们是很接近的年龄,但是因为我们的离散化的方法,把它分到两个不同的桶里面,可能学到的Embedding是差异比较大的Embedding。

针对这些问题,华为提出了一个连续值Embedding的方法AutoDis,它分为三个模块,第一个模块是Meta-embedding,就是假设有若干个桶,每个桶有个Field Embedding,这个embedding是可以去学习的,还有一个模块叫做Automatic Discretization,这个模块就是将原始值映射到一个H维的向量上。这里函数是去学习连续值分配到H个桶上的概率,然后基于分配概率和Meta-embedding,就会得到最终的连续值的embedding。
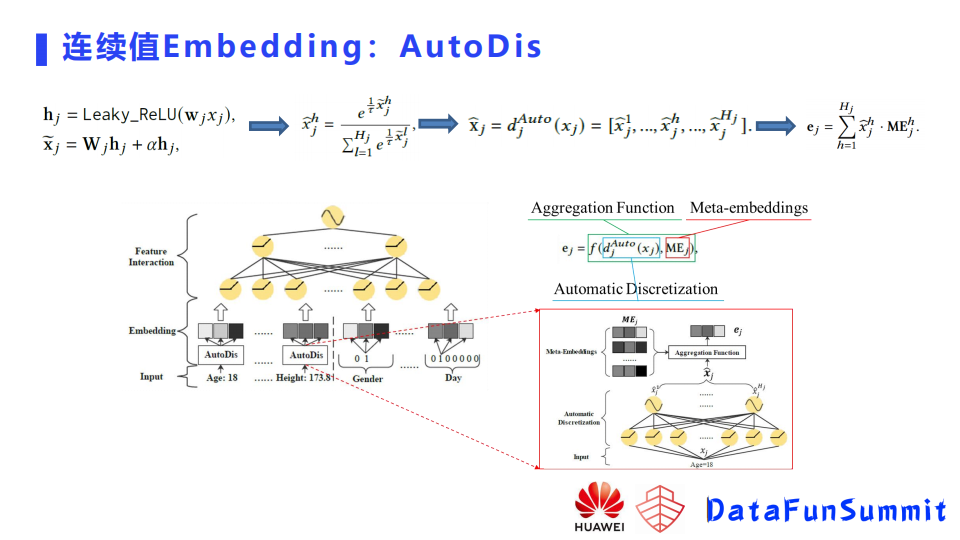
为了验证这个模型是不是有效,这里在两个公开数据集以及一个私有的数据集上做了实验,比较了像前面提到的几种不同的embedding方法,可以看到当使用这种离散化的方法时,它的效果相对于这种没有embedding或者Field Embedding,会有比较明显的提升。
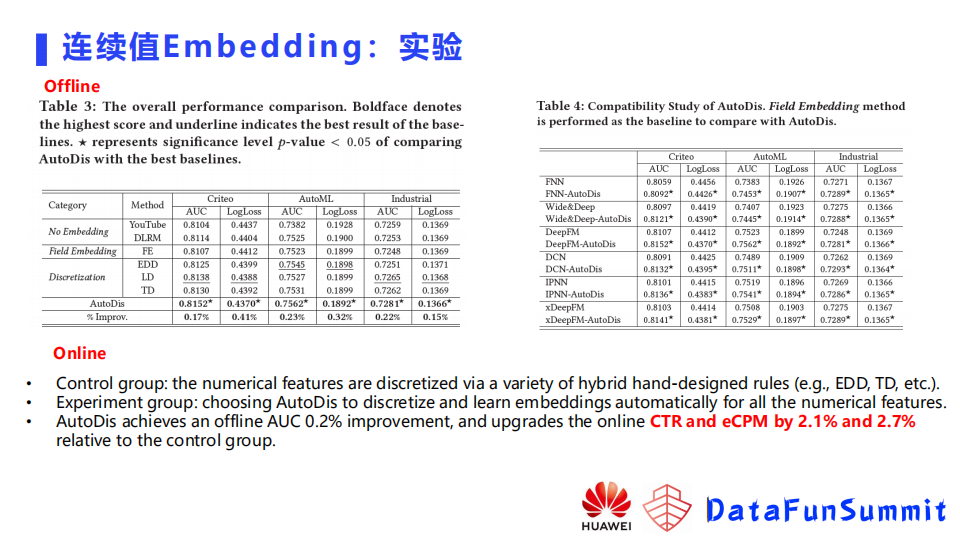
AutoDis方法相对于离散化的方法,会有进一步的提升,这篇文章也在不同的模型尝试加入AutoDis模块,看看AutoDis对普通模型是否有效果,这里可以看到(上图右边部分)它其实都有一些提升。文中还尝试了将该模型在华为内部一个业务上去落地上线。基线组的连续特征被专门做了精细化的设计,通过很多的调参去选择出来一个离散化的策略,实验组使用的是原始的连续值,然后在模型里面加入了一个AutoDis,看线上效果,在点击率及eCPM这两个指标上都是有一个百分位的提升。
03
交叉特征建模(Interaction Modelling)
这一部分介绍华为诺亚方舟实验室的第二个工作 - 交叉特征建模。这个工作目前还没有发表,但是我们已经放在了Arxiv上。
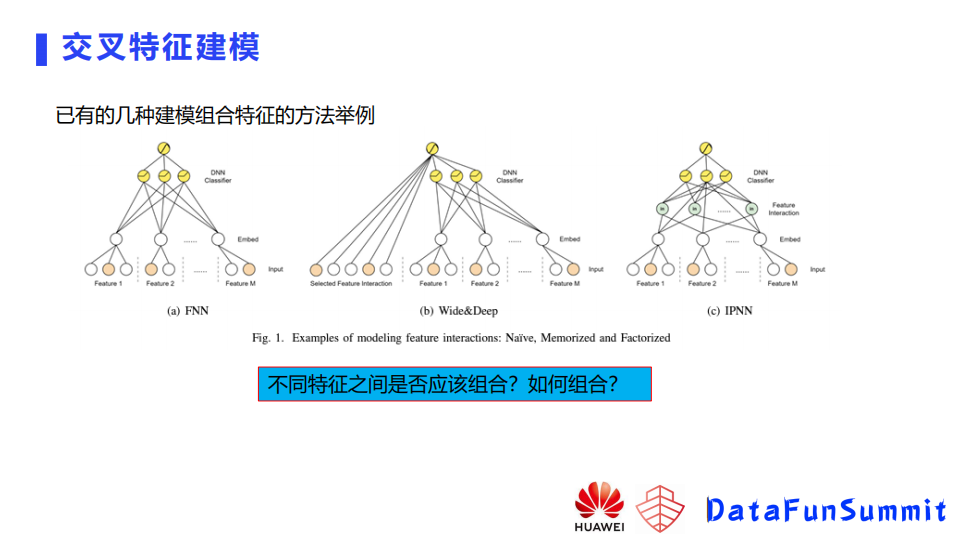
如上图所示,这里将组合特征建模方法分为了三类,即Naive、Memorized和Factorized。
第一类像FNN模型,即不建模,每个特征有一个embedding,所有的特征embedding后concat拼接输入网络,后面网络自己去学,想学到什么就是什么。
第二类像wide&deep模型,这里统称为基于记忆的方法,就是去显示的构造组合特征,特征做交叉做笛卡尔积,然后把新构造的特征输入模型。模型就会记住这个特征,这个信号就比较强。
第三类方法就是基于分解的方法,例如IPNN模型,对不同的域之间的交叉关系,通过乘法的方式去做建模,得到的乘法结果会和原始embedding一起喂入到后面的MLP,然后来再次去做一个组合。不同的特征之间是不是都应该组合,或者说怎么去组合,如果我们去试的话,需要去做很多实验,能不能自动判断特征是不是要组合,以及它们之间应该用哪种组合这种关系去学到呢,这个就是我们这个工作的一个动机。
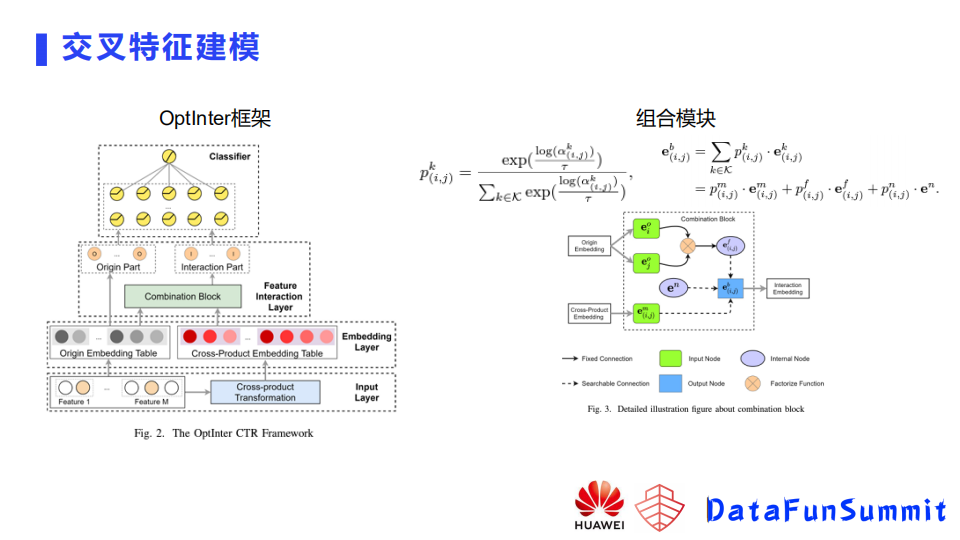
基于这个目标,我们提出Optlnter。如上左图,最上面有一个分类器,然后中间是一个Feature Interaction层,再下面是一个embedding层,这一层一方面会为每个特征用原始方法去构建出来它的embedding输出(Origin Embedding table),还有一个的话就是通过一个Cross-product transformation模块,将交叉特征的embedding学到。Cross-product transformation模快的细节展开如上右图所示,可以看到这个图里面蓝色的模块是一个选择模块,通过选择模块,最终输出这两个域的一个交叉的embedding。选择模块的输入有三个:第一个是使用分解方式去构建的一个embedding,基于这两个特征的一个embedding做一个乘法,然后得到的一个输出;然后第二个输入的话就是拿小白的方法 - 根据业务选择的特征直接输入,不做特征交叉,即我们认为两个特征之间关系不强,不去构建它,用了一个空的embedding。然后第三个输入,是通过交叉或者笛卡尔去构建出来特征,为这个特征分配一个独立的embedding。有这样三个输入,进入选择模块,选择模块会最终选出来一个embedding。选择模块是一个类似于softmax函数(如上图右图中公式),这个函数里面有一些参数是可以去学习的,最终会学出来一个结构的参数。基于这个框架,训练也是分为两个阶段,第一个阶段就是搜索,第二个阶段是Retrain。搜索的话,这块具体细节不进行展开了,其实是要学一个⍺参数。这个参数,是一个结构的参数,针对每个特征,它们之间是使用小白的、记忆的,还是使用基于分解的方式去建模,通过训练会得到一个最优的⍺参数,然后到了retrain阶段的话,我们会根据最优的⍺参数去重构我们的网络,然后基于重构的网络的,将模型重新训练。
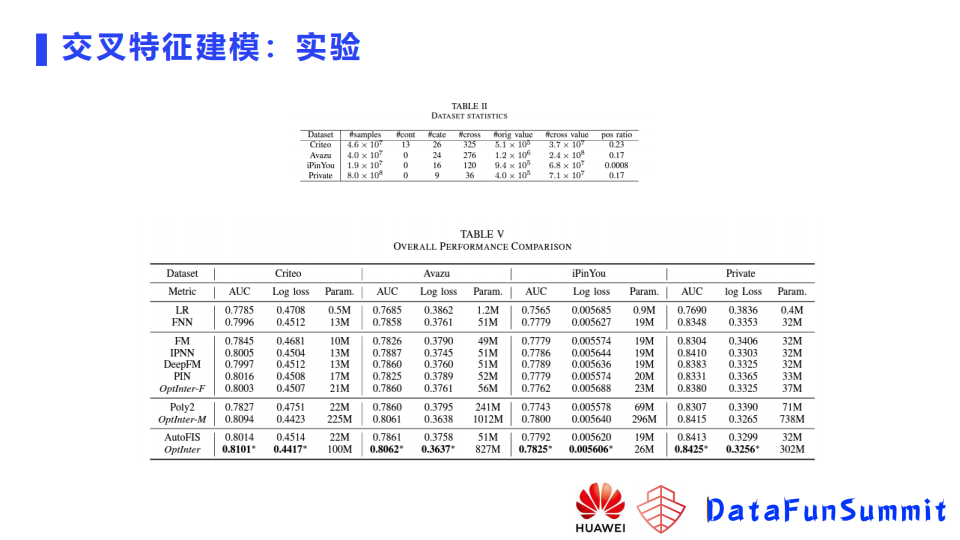
对于以上方法,在多个数据集进行了实验,包括三个公开的数据集,这三个数据集是CTR预测比较常用的数据集,并且在私有的数据集进行了实验;如上图所示,是几个数据集的实验结果。这里分别比较了LR这种不去构建任何特征交叉的方法、分解的方法以及记忆的方法。
04
大Embedding模型训练(Distributed Training)
第四部分也是介绍华为的一个工作 - 大Embedding模型的分布式训练,这个工作发表于SIGIR2021。
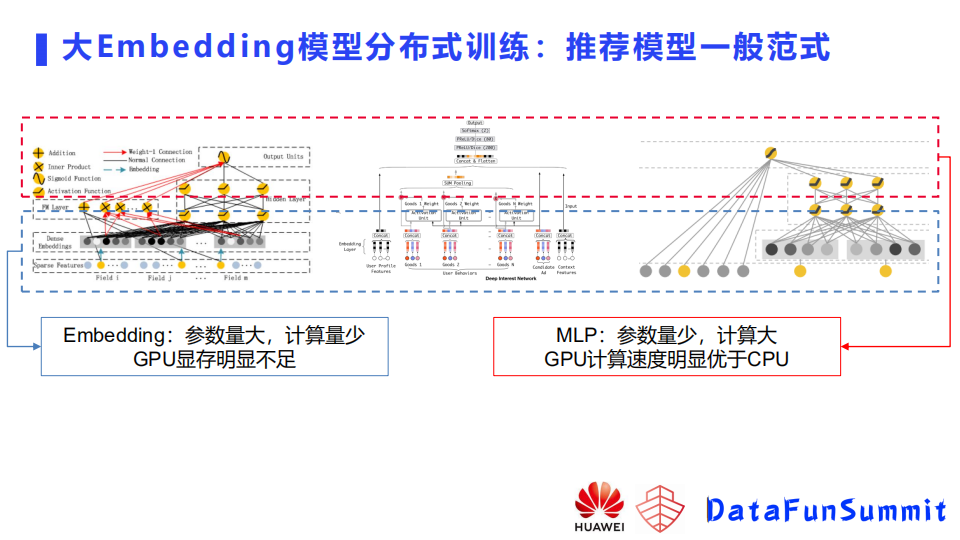
如上图所示,推荐模型一般都包含两部分,一部分是参数embedding,一部分是MLP。两部分在数据和存储上有不同的特点。embedding参数量很大,计算量相对比较少。一般GPU的显存是明显不够去存embedding的,像上文提到的模型有几百个G,一张显卡如V100有32个G,还会去存很多运行态参数等数据,用它存embedding显然是不切实际的。第二部分MLP,它的参数量相对来说比较少,但计算量会相对比较大。训练MLP的话,使用CPU它的效率相对于GPU来说是低很多的。这里简单介绍了下推荐模型的一个训练的特点。
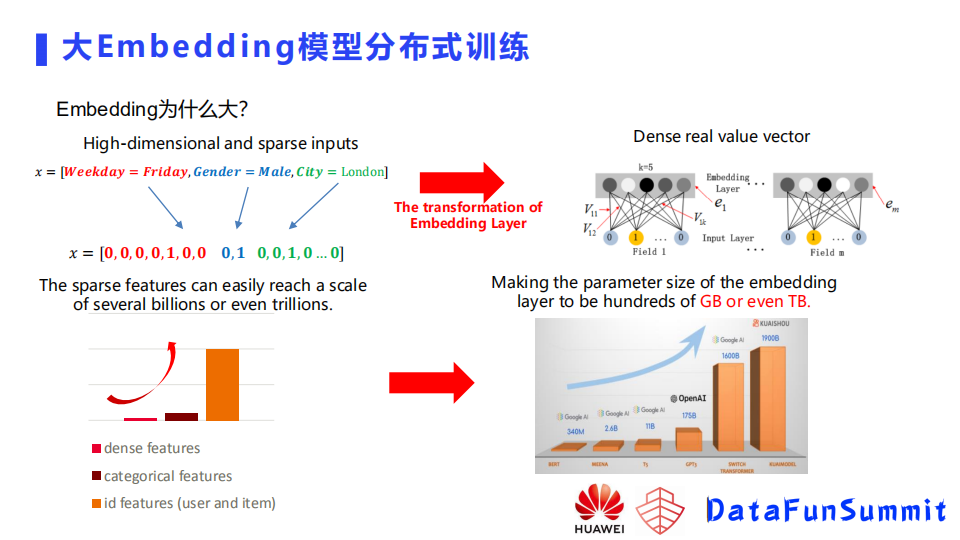
这里再简要提一下,为什么Embedding会大。这是因为推荐里面有很多的高维稀疏输入,什么是高纬稀疏呢,比如上图的例子,样本有三个域的特征,星期、性别和城市,因为它是离散的特征,所以它这里面只有某个位置会有值。这个例子中特征的维度都是比较低的,其实像用户或者是一些交叉特征,它的维度是会很高的,特征的量也是很大的,在推荐里面因为用了embedding,就是将高维稀疏的输入映射到了一个低维稠密的一个向量上,当我们稀疏的特征变得很大,大到几十亿甚至是几百亿上千亿规模之后,它的embedding的table也会变得很大。如上图右下部分,是快手去年发布的一个模型,比谷歌的一个超大模型还要大,这是因为它这里面embedding table里面有很多的特征,每个特征都有个embedding,导致规模会很大。
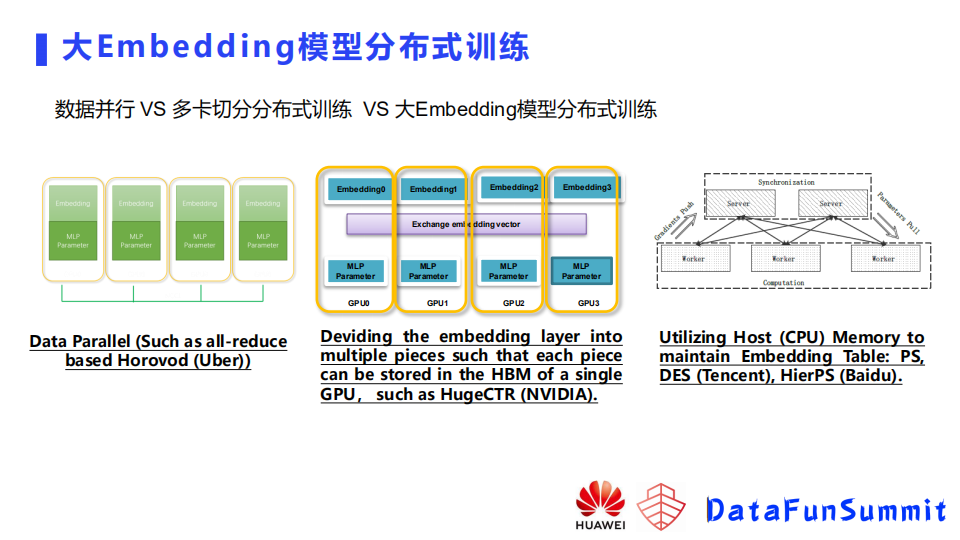
简要介绍下已有的几种并行训练的方法:
第一类是数据并行,例如基于all-reduce的Horovod,这种方式在每个GPU卡中存一份完整的模型副本,需要把模型都能存得下,我们模型如果变得大,GPU显存不足以存下完整模型,即使模型可以存得下,比方说有十几G几十G,基于这样一个大小的模型,它在做通信的时候,它的通信的时延很可能比它计算带来的时间的减少还要来得多,也就是说你增加节点不一定带来性能的一个提升。
第二类是NVIDIA提出的,之前他们的方案还是一个多卡切分的方案,但现在已经支持了一个CPU的embedding的一个存储,他们这个方法把embedding切成多份,然后在每个卡的显存里面存一部分,MLP在每个节点都存一个完整的模型。embeding通过一个all to all的通信, MLP通过all-reduce通信,这个方案有一个问题就是当它的模型很大时需要的GPU卡很多,从而它的成本也会很高。
第三类方法是使用CPU的内存来存embedding,然后用GPU来存MLP。CPU负责存储,MLP来负责前项以及反向的梯度的计算。对于这种方法,如果我们采用同步训练的话,它有一个问题就是因为embedding是存在CPU侧的,需要从CPU去传输到GPU,梯度需要从GPU回传到CPU,他们之间通信的时延是很高的。
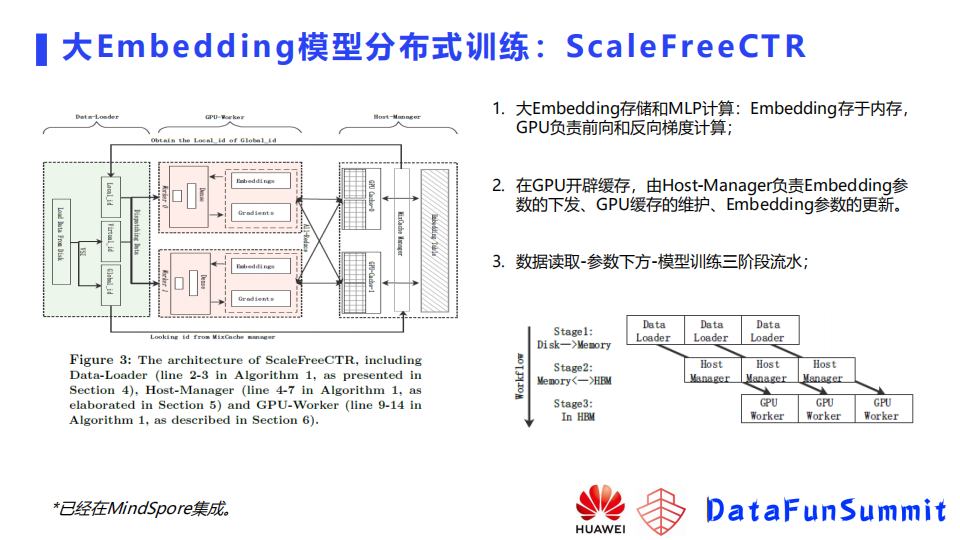
针对这些问题华为就提出了自己的一个分布式训练的框架,叫做ScalefreeCTR,这个框架分成三个部分,第一个部分是有一个Host manager,它是用来负责embedding单元以及缓存的一个维护,另一个模块的话是dataloader,负责将数据从硬盘读到内存,以及做一些去重之类的操作,第三个部分是GPU worker,它负责从缓存里面去把对应的embedding取到,然后去做一个前向计算以及反向的训练,然后再将梯度更新到缓存的embedding中。这里由host-manager来负责embedding参数的下发,GPU缓存的维护,以及embedding参数的更新,因为有了缓存,所以我们可以做到数据读取,参数下发以及模型训练的三阶段的流水,尽可能的提升了资源的利用效率,从而提升了最终的吞吐。
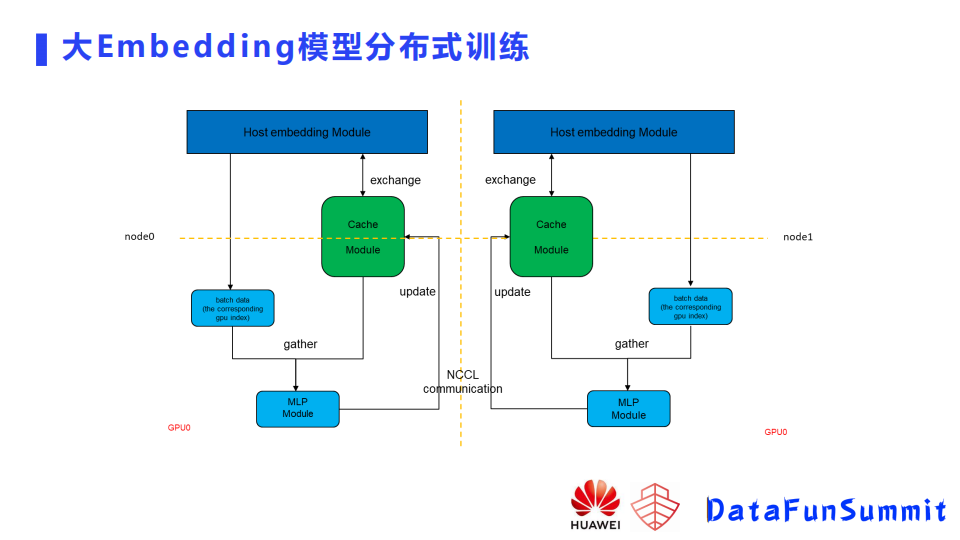
如上所示是比较细节的图,这里可以看到embedding完整的存在了CPU侧。如果有多个节点的话,每个节点负责一部分embedding的存储,然后换Host-manager,它就负责绿色的缓存和embedding之间的交互,host-manager会根据当前的数据去做下一批的数据提前的下发,也就是说当下面的GPUworker完成了上一个batch训练之后,可以直接从缓存里面取到它下一个batch需要用到的参数,因而GPU相对来说利用率是比较高的,GPU之间的通信使用all-reduce的MLP的通信。
05
总结和展望
最后做个简单的总结,从做算法以及训练方法的角度有以下三个比较有意思的方向:
-
怎样去结合数据设计更好的模型,让模型更有针对性。
-
如何进一步提升训练效率,包括怎样去利用更多的数据,以及增快模型迭代效率。
-
怎样去增强数据处理、选择、模型调优的自动化的程度,从而解放业务或者算法同学,让他们更多地去关注模型数据、算法和策略。
今天的分享就到这里,谢谢大家。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
本文转自 https://blog.csdn.net/python1222_/article/details/141815862?spm=1001.2014.3001.5501,如有侵权,请联系删除。















 179
179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









