







 这篇文档详细介绍了TensorFlow Lite的8-bit量化规范,旨在帮助硬件开发者支持量化模型的推理。规范包括对称与非对称量化、按轴与按张量量化等,强调了权重的对称性以减少计算开销。同时,列出了如ADD、CONV_2D、SOFTMAX等操作的量化要求,如输入输出范围、粒度和限制条件。
这篇文档详细介绍了TensorFlow Lite的8-bit量化规范,旨在帮助硬件开发者支持量化模型的推理。规范包括对称与非对称量化、按轴与按张量量化等,强调了权重的对称性以减少计算开销。同时,列出了如ADD、CONV_2D、SOFTMAX等操作的量化要求,如输入输出范围、粒度和限制条件。
TensorFlow Lite 8-bit quantization specification (8-bit 量化规范)
The following document outlines the specification for TensorFlow Lite's 8-bit quantization scheme. This is intended to assist hardware developers in providing hardware support for inference with quantized TensorFlow Lite models.
TensorFlow Lite 的 8-bit 量化方案的规范,旨在为硬件开发者提供使用 quantized TensorFlow Lite models 进行推断的硬件支持。
1. Specification summary - 规范摘要
We are providing a specification, and we can only provide some guarantees on behaviour if the spec is followed. We also understand different hardware may have preferences and restrictions that may cause slight deviations when implementing the spec that result in implementations that are not bit-exact. Whereas that may be acceptable in most cases (and we will provide a suite of tests that to the best of our knowledge include per-operation tolerances that we gathered from several models), the nature of machine learning (and deep learning in the most common case) makes it impossible to provide any hard guarantees.
我们提供的是规范,并且只能在遵守规范时提供部分行为保证。我们也理解不同硬件有其偏好和限制,这可能会在实现规范时造成细微偏差,从而导致实现无法达到 bit-exact。但在大多数情况下这或许可以接受 (我们将尽我们所知提供一套测试,其中包括我们从几种模型中收集到的按运算容差),机器学习 (以及最常见的深度学习) 的性质决定了无法提供任何硬性保证。
8-bit quantization approximates floating point values using the following formula.
8-bit 量化近似于使用以下公式得到的浮点值:
r
e
a
l
_
v
a
l
u
e
=
(
i
n
t
8
_
v
a
l
u
e
−
z
e
r
o
_
p
o
i
n
t
)
∗
s
c
a
l
e
real\_value = (int8\_value - zero\_point) * scale
real_value=(int8_value−zero_point)∗scale
反量化 (dequantization): ( i n t 8 _ v a l u e − z e r o _ p o i n t ) ∗ s c a l e = > r e a l _ v a l u e (int8\_value - zero\_point) * scale => real\_value (int8_value−zero_point)∗scale=>real_value
Per-axis (aka per-channel in Conv ops) or per-tensor weights are represented by int8 two’s complement values in the range [-127, 127] with zero-point equal to 0.
Per-tensor activations/inputs are represented by int8 two’s complement values in the range [-128, 127], with a zero-point in range [-128, 127].
per-axis (aka per-channel in Conv ops) or per-tensor weights 由 int8 补码值表示,范围为 [-127, 127],zero-point 等于 0。
per-tensor activations/inputs由 int8 补码值表示,范围为 [-128, 127],zero-point 范围为 [-128, 127]。
There are other exceptions for particular operations that are documented below.
下文记录了特定运算的其他例外情况。
Note: In the past our quantization tooling used per-tensor, asymmetric, uint8 quantization. New tooling, reference kernels, and optimized kernels for 8-bit quantization will use this spec.
注:过去,我们的量化工具使用的是 per-tensor、非对称、uint8 量化。用于 8-bit 量化的新工具、参考内核和优化内核将使用此规范。
2. Signed integer vs unsigned integer - 有符号整数与无符号整数
TensorFlow Lite quantization will primarily prioritize tooling and kernels for int8 quantization for 8-bit. This is for the convenience of symmetric quantization being represented by zero-point equal to 0. Additionally many backends have additional optimizations for int8xint8 accumulation.
TensorFlow Lite 量化将主要优先考虑用于 8-bit 的 int8 工具和 kernels。这是为了方便由 zero-point 等于 0 表示的对称量化。此外,许多后端还有针对 int8xint8 累加的其他优化。
3. Per-axis vs per-tensor - 按轴与按张量
Per-tensor quantization means that there will be one scale and/or zero-point per entire tensor. Per-axis quantization means that there will be one scale and/or zero_point per slice in the quantized_dimension. The quantized dimension specifies the dimension of the Tensor’s shape that the scales and zero-points correspond to. For example, a tensor t, with dims=[4, 3, 2, 1] with quantization params: scale=[1.0, 2.0, 3.0], zero_point=[1, 2, 3], quantization_dimension=1 will be quantized across the second dimension of t:
per-tensor quantization 意味着每个完整张量将有一个 scale and/or zero-point。per-axis quantization 意味着 quantized_dimension 中的每个切片将有一个 scale and/or zero_point。量化维度指定 scales and zero-points 所对应的张量形状的维度。例如,张量 t (具有 dims=[4, 3, 2, 1],量化参数为:scale=[1.0, 2.0, 3.0]、zero_point=[1, 2, 3]、quantization_dimension=1) 将在 t 的第二个维度上进行量化:
t[:, 0, :, :] will have scale[0]=1.0, zero_point[0]=1
t[:, 1, :, :] will have scale[1]=2.0, zero_point[1]=2
t[:, 2, :, :] will have scale[2]=3.0, zero_point[2]=3
Often, the quantized_dimension is the output_channel of the weights of convolutions, but in theory it can be the dimension that corresponds to each dot-product in the kernel implementation, allowing more quantization granularity without performance implications. This has large improvements to accuracy.
通常,quantized_dimension 是卷积权重的 output_channel,但从理论上讲,它可以是与内核实现中每个点积相对应的维度,从而在不影响性能的情况下允许更多的量化粒度。这大大提高了准确率。
TFLite has per-axis support for a growing number of operations. At the time of this document, support exists for Conv2d and DepthwiseConv2d.
TFLite 为越来越多的运算提供按轴支持。在撰写本文时,已支持 Conv2d 和 DepthwiseConv2d。
4. Symmetric vs asymmetric - 对称与非对称
Activations are asymmetric: they can have their zero-point anywhere within the signed int8 range [-128, 127]. Many activations are asymmetric in nature and a zero-point is an relatively inexpensive way to effectively get up to an extra binary bit of precision. Since activations are only multiplied by constant weights, the constant zero-point value can be optimized pretty heavily.
激活 (activations) 是非对称的:它们的 zero-point 可以位于 signed int8 范围 [-128, 127] 内的任何位置。许多激活在本质上是非对称的,zero-point 是一种相对廉价的方式,可以有效获得额外的二进制位精度。由于激活仅乘以常量权重,因此可以对常量 zero-point 进行大量优化。
Weights are symmetric: forced to have zero-point equal to 0. Weight values are multiplied by dynamic input and activation values. This means that there is an unavoidable runtime cost of multiplying the zero-point of the weight with the activation value. By enforcing that zero-point is 0 we can avoid this cost.
权重 (weights) 是对称的:强制使 zero-point 等于 0。weights 会乘以 dynamic input and activation values。这意味着将 weight 的 zero-point 与激活值 (activation value) 相乘时,会不可避免地产生运行时开销。通过强制使 zero-point 等于 0,我们可以避免此开销。
Explanation of the math: this is similar to section 2.3 in arXiv:1712.05877, except for the difference that we allow the scale values to be per-axis. This generalizes readily, as follows:
数学解释:这类似于 Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference 中的 2.3 节,不同之处在于我们允许将 scale 设为 per-axis。这很容易概括如下:
A
A
A is a
m
∗
n
m * n
m∗n matrix of quantized activations. (量化激活的矩阵)
B
B
B is a
n
∗
p
n * p
n∗p matrix of quantized weights. (量化权重的矩阵)
Consider multiplying the
j
j
jth row of
A
A
A,
a
j
a_j
aj by the
k
k
kth column of
B
B
B,
b
k
b_k
bk, both of length
n
n
n. The quantized integer values and zero-points values are
q
a
q_a
qa,
z
a
z_a
za and
q
b
q_b
qb,
z
b
z_b
zb respectively.
考虑将
A
A
A 的第
j
j
j 行
a
j
a_j
aj 乘以
B
B
B 的第
k
k
k 列
b
k
b_k
bk,两者的长度均为
n
n
n。量化的整数值和 zero-points 分别是
q
a
q_a
qa,
z
a
z_a
za and
q
b
q_b
qb,
z
b
z_b
zb。
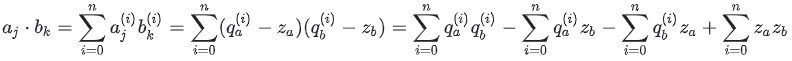
The
∑
i
=
0
n
q
a
(
i
)
q
b
(
i
)
\sum_{i=0}^{n} q_{a}^{(i)}q_{b}^{(i)}
∑i=0nqa(i)qb(i) term is unavoidable since it’s performing the dot product of the input value and the weight value.
∑
i
=
0
n
q
a
(
i
)
q
b
(
i
)
\sum_{i=0}^{n} q_{a}^{(i)}q_{b}^{(i)}
∑i=0nqa(i)qb(i) 项是不可避免的,因为它执行的是 the input value and the weight value 的点积。
The
∑
i
=
0
n
q
b
(
i
)
z
a
\sum_{i=0}^{n} q_{b}^{(i)}z_{a}
∑i=0nqb(i)za and
∑
i
=
0
n
z
a
z
b
\sum_{i=0}^{n} z_{a}z_{b}
∑i=0nzazb terms are made up of constants that remain the same per inference invocation, and thus can be pre-calculated.
∑
i
=
0
n
q
b
(
i
)
z
a
\sum_{i=0}^{n} q_{b}^{(i)}z_{a}
∑i=0nqb(i)za and
∑
i
=
0
n
z
a
z
b
\sum_{i=0}^{n} z_{a}z_{b}
∑i=0nzazb 项由常量组成,这些常量在每次 inference 调用时保持不变,因此可以预先计算。
The
∑
i
=
0
n
q
a
(
i
)
z
b
\sum_{i=0}^{n} q_{a}^{(i)}z_{b}
∑i=0nqa(i)zb term needs to be computed every inference since the activation changes every inference. By enforcing weights to be symmetric we can remove the cost of this term.
每次 inference 都需要计算
∑
i
=
0
n
q
a
(
i
)
z
b
\sum_{i=0}^{n} q_{a}^{(i)}z_{b}
∑i=0nqa(i)zb 项,因为激活 (activation) 会改变每次 inference。通过强制使权重对称,我们可以移除此项的开销。
invocation [ˌɪnvəʊˈkeɪʃ(ə)n]:n. 调用,祈祷,求助,启用
5. int8 quantized operator specifications - int8 量化算子规范
Below we describe the quantization requirements for our int8 tflite kernels:
我们在下面描述了 int8 tflite kernels 的量化要求:
granularity [grænjʊ'lærɪtɪ]:n. 颗粒性
ADD
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Input 1:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
AVERAGE_POOL_2D
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
restriction: Input and outputs must all have same scale/zero_point
CONCATENATION
Input ...:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
restriction: Input and outputs must all have same scale/zero_point
CONV_2D
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Input 1 (Weight):
data_type : int8
range : [-127, 127]
granularity: per-axis (dim = 0)
restriction: zero_point = 0
Input 2 (Bias):
data_type : int32
range : [int32_min, int32_max]
granularity: per-axis
restriction: (scale, zero_point) = (input0_scale * input1_scale[...], 0)
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
DEPTHWISE_CONV_2D
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Input 1 (Weight):
data_type : int8
range : [-127, 127]
granularity: per-axis (dim = 3)
restriction: zero_point = 0
Input 2 (Bias):
data_type : int32
range : [int32_min, int32_max]
granularity: per-axis
restriction: (scale, zero_point) = (input0_scale * input1_scale[...], 0)
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
FULLY_CONNECTED
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Input 1 (Weight):
data_type : int8
range : [-127, 127]
granularity: per-tensor
restriction: zero_point = 0
Input 2 (Bias):
data_type : int32
range : [int32_min, int32_max]
granularity: per-tensor
restriction: (scale, zero_point) = (input0_scale * input1_scale[...], 0)
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
L2_NORMALIZATION
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
restriction: (scale, zero_point) = (1.0 / 128.0, 0)
LOGISTIC
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
restriction: (scale, zero_point) = (1.0 / 256.0, -128)
MAX_POOL_2D
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
restriction: Input and outputs must all have same scale/zero_point
MUL
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Input 1:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
RESHAPE
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
restriction: Input and outputs must all have same scale/zero_point
RESIZE_BILINEAR
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
restriction: Input and outputs must all have same scale/zero_point
SOFTMAX
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
restriction: (scale, zero_point) = (1.0 / 256.0, -128)
SPACE_TO_DEPTH
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
restriction: Input and outputs must all have same scale/zero_point
TANH
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
restriction: (scale, zero_point) = (1.0 / 128.0, 0)
PAD
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
restriction: Input and outputs must all have same scale/zero_point
GATHER
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
restriction: Input and outputs must all have same scale/zero_point
BATCH_TO_SPACE_ND
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
restriction: Input and outputs must all have same scale/zero_point
SPACE_TO_BATCH_ND
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
restriction: Input and outputs must all have same scale/zero_point
TRANSPOSE
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
restriction: Input and outputs must all have same scale/zero_point
MEAN
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
SUB
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Input 1:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
SUM
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
SQUEEZE
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
restriction: Input and outputs must all have same scale/zero_point
LOG_SOFTMAX
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
restriction: (scale, zero_point) = (16.0 / 256.0, 127)
MAXIMUM
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
restriction: Input and outputs must all have same scale/zero_point
ARG_MAX
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
MINIMUM
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
restriction: Input and outputs must all have same scale/zero_point
LESS
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Input 1:
data_type : int8
range : [-128, 127]
granularity: per-tensor
PADV2
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
restriction: Input and outputs must all have same scale/zero_point
GREATER
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Input 1:
data_type : int8
range : [-128, 127]
granularity: per-tensor
GREATER_EQUAL
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Input 1:
data_type : int8
range : [-128, 127]
granularity: per-tensor
LESS_EQUAL
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Input 1:
data_type : int8
range : [-128, 127]
granularity: per-tensor
SLICE
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
restriction: Input and outputs must all have same scale/zero_point
EQUAL
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Input 1:
data_type : int8
range : [-128, 127]
granularity: per-tensor
NOT_EQUAL
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Input 1:
data_type : int8
range : [-128, 127]
granularity: per-tensor
SHAPE
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
QUANTIZE (Requantization)
Input 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
Output 0:
data_type : int8
range : [-128, 127]
granularity: per-tensor
References
https://tensorflow.google.cn/lite/performance/quantization_spec
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference


















 1702
1702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











