






第二十二章 Additional Topics in Modern Rendering
这一章是全书的最后一章,旨在讨论作为一名图形程序员新手接下来需要学习哪些知识。因此,本章所讲述的内容与之前章节不同,主要是讨论一些现代渲染的相关主题,而不是深入讲解某个具体的图形技术。特别是讨论一些提高图形渲染应用程序性能的方法技巧,并探讨如何使用deffred shading和global illumination提高场景的渲染质量。此外,还会讲解有关compute shaders和数据驱动引擎架构的内容。
Rendering Optimization
有多种方法可以用于优化渲染速度,但是所有的方法大致上都可以分为两类:
- 针对CPU部分进行优化(在数据发送到GPU之前)
- 针对GPU部分进行优化(优化shader)
无论使用什么优化方法,最重要的是减少从应用程序开始渲染到最终把场景显示到屏幕上所花的时间。通常情况下,渲染管线中要处理的objects数量越多,渲染的时间越长。因此,在渲染优化中最常用的一种方法是减少渲染管线中要处理的objects数量。具体包括剔除位于camera视域范围之外的objects,并对objects进行排序,这样在GPU中就可以以最优的方式进行渲染。此外,减少调用渲染API的开销,以及减少管线中的每一个阶段所要执行的shader指令数量也是非常重要的优化方法。
每一种优化技巧都有多种实现方法。接下来的章节主要讲解在现代渲染中一些常见的优化方法。
View Frustum Culling
在理想情况下,位于camera的视域体(view frustum)之外的objects不应该传递到GPU中进行渲染。由于在管线的最后阶段不会把这些objects写入render target中,如果不剔除这些ojbects,至少在管线的前几个阶段会阻塞图形总线(graphics bus)。View frustum culling的处理过程是把场景的objects与view frustum进行碰撞检测,如果一个object位于frustum内部,就发送到GPU中执行渲染,否则,剔除该object。
用于frustum碰撞检测的一个简单方法是遍历场景中全部的objects。但是如果场景中包含大量的objects,这种简单的遍历方法就会变得非常缓慢。因此,我们主要的任务是pruning(精简)要执行碰撞检测的objects列表。用于执行精简的一个常用数据结构是bounding volume hierarchies(BVHs,包围体层次结构)。一个BVH结构由一个预处理步骤构建,并把objects列表组织到一个bounding volume层次中。例如,使用bounding volume sphere(包围球)构造一个二叉树结构的bounding spheres hierarchy。该hierarchy结构中的每一个结点都包含能够容纳所有objects的最小的包围球。二叉树中的每一个叶结点对应一个object(以及包围球),每一个非叶子结点包含两个子结点,每一个子结点又由父结点中的一半objects组成。依此类推,二叉树的根结点包含全部的objects。Pruning objects列表的一部分进行渲染主要是,遍历该二叉树并测试每一个结点的包围球是否与view frustum相交。如果某个结点的包围球与view frustum不相交,那么该结点的所有子结点的包围球与view frustum也不相交,那么该结点及以下的整个树枝都不需要进一步处理。包围球与view frustum相交的每一个叶结点都会传递到GPU中进行渲染。
这种构建二叉树的方法并不局限于使用bounding spheres(包围球)。还可以使用axis-aligned bounding boxes(AABBs,轴对齐的包围盒)或oriented bounding boxes(OBBs)作为包含objects的包围体。与这几种包围体对应的树形结构通常称为AABB-tress,OBB-tress以及Sphere-tress。不同的包围体具有不同的贴合程度(tightness of fit),计算相交的速度也不同,因此在贴合度和计算速度之间得到一种折衷的方法。例如,球形包围体具有最快计算物体相交的速度,但是贴合程序最差。从sphere到AABB,OBB,low-poly hull分别表示贴合程度越来越好,而计算相交的速度越来越慢。
Bounding volume hierarchies表示在一个场景中对object进行划分,另一种划分方法space partitioning systems则是对objects所在的空间进行划分。Space partitioning systems把一个空间划分为两个或多个互不重叠的子空间。场景中的每一个object恰好都被分配到其中一个空间区域。类似于上面的例子,也可以把这些划分的区域组织成一个树形结构,称为space-partitioning tree。例如,一个binary-space partitioning tree(也称为BSP tree),根据objects所在的空间区域把objects划分到一个平面的某一边,然后递归使用该划分方法直到达到树的最大深度。BSP trees是多种常用的space partitioning方法的一种,另外两个常用的space partitioning systems是quadtress(四叉树)和octress(八叉树)。
一个四叉树递归的把一个空间划分为四个象限(一般为正方形或矩阵)。在递归达到一个最大容量的时候就把objects分配到其中一个象限,此时就划分好了象限(通常是达到树的最大深度)。当某个结点所包含的空间区域与view frustum不相交,该结点就会被pruned(裁剪)。
一个八叉树是一个三维的四叉树,把空间划分为八个卦角(通常为立方体)。但是,这并不说在三维场景中不能使用四叉树。相反,当一个游戏中大部分的objects都位于同一个平面上(比如,xz平面)时,使用四叉树更好。使用八叉树比四叉树会消耗更多内存,以及更高的计算成本,用于创建和遍历。但是如果场景设定在一个外部空间中,在整个空间中objects或多或少都是均匀分布,那么使用八叉树所带来的剔除计算速度的提升就可以弥补所引起的内存和计算成本。这意味着场景中objects的分布情况决定了划分使用的数据结构。四叉树和八叉树都是均匀的space-partitioning systems,这两种方法对空间进行均匀的划分。但是,如果场景中的objects并不是均匀分部的,使用这种方法就会产生大量空白的区域(浪费内存空间)。对于这种情况,可以使用一种非均匀的space-partitioning system,比如kD-tree。
所有的划分系统方法都需要在,算法实现的复杂度,内存需求,以及更新成本之间进行折衷处理。无论使用哪种方法,必须保证使用该方法得到的剔除计算的性能提升能弥补产生的额外开销。到底选择哪种剔除方法很大程度上是基于应用程序的先决条件。例如,场景中的objects是分散的还是聚焦到一起?是或多或少位于同一个平面内还是包含一个垂直的分量?另外,在tree中是否包含动态的objects,还是仅包含静态的meshes?如果包含动态的objects,需要更新相关的数据结构,根据场景的复杂度,可能会导致高昂的计算成本。总之,需要在应用程序中进行各种测试以确定使用一种最好的数据结构。
Occlusion Culling
在前面章节中,我们已经介绍过了backface culling(背面剔除),具体是指不渲染那些背向camera的triangles。另外还介绍了如何使用depth buffer(深度缓存,也称为z-buffer)剔除那些被遮挡的pixels(称为z-culling)。但是这些方法是在object被发送到GPU之后执行的。而CPU occlusion culling(遮挡剔除)则是在把objects发送给GPU之前,先剔除那些被完全遮挡的objects。考虑以下情形,你位于一个大厦内,该大厦只是某个场景的一部分。大厦的墙壁遮挡了所有墙外的objects,这些objects包含了场景中所有geometry的大多数。那么剔除这些被遮挡的objects将显著提高渲染性能。
执行occlusion culling主要有两种方法:potentially visible set(PVS,潜在可见集)rendering和portal rendering。
PVS渲染方法主要是把场景划分为多个区域,并预先计算在每个区域中针对不同的camera位置哪些objects是可见的。这种方法的时间成本就是查找camera位置对应的PVS集合的时间复杂度,在该集合中只有可见的objects才会发送到GPU中。但是PVS方法也有一些不足的地方:对PVS数据进行排序需要大量的内存开销,不支持整个动态场景,生成PVS数据会产生预处理时间成本。此外,创建PVS数据通常需要进行手动配置,需要花费一定的时间,并且在场景发生变化时,需要重新生成PVS数据。
Portal rendering也是把场景划分为多个区域regions(或zones),其中每一个区域都会遮挡位于该区域外面的objects。邻接区域是指通过portal把两个区域连接到一起,portal表示这两个区域共用的geometry,用于指示在区域以外的潜在可见objects。使用PVS算法可以预先计算区域内部以及相邻两个区域之间的可见性。
Object Sorting
Occlusion culling是为了减少overdraw(多余的绘制),或者说对同一个pixel执行多次渲染。在绘制一个不透明的pixel时,如果仅仅是使用一个距离camera更近的pixel覆盖该不透明的pixel将会浪费大量的处理时间。通过非必要绘制的pixels数量与必须进行绘制的pixels数量之间的比率,可以描述重复绘制的数量比例。理想情况,该比值应该为0(即没有多余的绘制)。重复绘制的比例值越大,性能就越低。
对(不透明的)objects进行距离camera由近到远的排序,可以减少重复绘制,这种方法是基于z-buffer会拒绝绘制无法通过深度测试的pixels。这种排序方法需要大量的计算成本,但是使用一种降低排序准确度的折衷方法可以减小计算成本。另一种替代object排序的方法是,使用一个early z pass方法绘制场景。这种technique会对场景渲染两次:首先把场景渲染到depth buffer中(该pass中禁用pixel shader),然后再渲染到frame buffer中。在第二次渲染场景时,只有距离camera最近的pixels才能通过深度测试,其他的pixels在pixel shader执行之前都会被剔除。
Shader Optimization
当你剔除了尽可能多的objects,并对可见的objects进行排序用于支持有效的z-culling操作之后,就可以开始重点关注shaders的优化。在本书上所编写的shaders都是倾向于更好的可读性,而不是高效的性能。这一节主要目的是提供一些提高shaders运算速度的指导方法。
- Know the enemy (or, profile your code)(找出影响性能的地方,或者说对代码进行性能分析)
市场上有多种工具可以用于对shaders做性能分析,我比较喜欢使用NVIDIA Nsing Visual Studio Edition。NVIDIA的官方网站上提供了这个工具,并包含大量的帮助文档,另外还可以观看教学视频从头开始学习。实际上,性能分析不仅仅关系到shader的优化;针对CPU端的应用程序做性能分析也是非常重要的。性能分析一般是用于整个应用程序中,而且是任何优化过程的第一步。 - Dont early optimize(不要在程序开发的前期做优化)
在程序开发的前期如果没有遇到性能问题,不值得把开发时间用于提高渲染速度的优化工作上。 - Pixels outnumber vertices(pixels数量远大于vertices数量)
在渲染管线中vertices数量通常要少于pixels数量。因此,在不影响视觉效果的情况下,把pixel shader的部分代码指令转移到vertex shader中执行可以提高性能。
判断pixel shader是不是性能瓶颈的一种常用方法是,比较应用程序在不同的窗口尺寸下的性能。窗口的尺寸越大,需要渲染的pixel就越多。如果在不断提高窗口分辨率的情况下,性能急剧下降,就说明pixel shader就是影响性能的问题所在。 - Skip unnecessary instructions(跳过不需要执行的指令)
这一条优化建议主要是关于dynamic branching(动态条件分支)。例如,如果shader中支持fog(雾)效果,在pixel shader中一开始就要判断fog amount(雾的影响程度)。如果pixel完全被fog模糊了,就可以不执行pixel shader中剩下的指令。这种方法同样适用于大多数“提前丢弃”pixels的情况,比如计算透明效果。在执行alpha混合运算时,如果当前要计算的pixel是完全透明的,就可以跳过整个pixel shader指令运算。
也就是说,使用这种方法更多情况下是跳过部分代码块,而不是整个shader代码。例如,使用Lambert余弦定理计算光照的diffuse分量,如果光源位于表面的“背面”,就可以跳过对diffuse和specular分量的额外计算。但是,你依然需要计算ambient分量(如果有的话)。在这些情形下,使用dynamic branching能够带来一定的性能提升。
虽说要谨慎使用这种方法,但是几乎可以肯定的是使用dynamic branching方法比执行不必要的指令更好。
Dynamic branching方法的另一种应用情形是对数据执行不必要的重复规范化运算。如果在CPU端程序中确保一个方向向量已经被规范化了,那么在GPU中就不需要再执行规范化操作。同样,在pixel shader中,由于
插值计算会产生细微的偏差,也需要对方向向量重复规范化。但是,如果由该误差导致的视觉偏差足够小也可以去掉多余的规范化运算指令。 - Keep your shaders simple(使用shaders的代码尽量简洁)
Shaders的代码指令越复杂,那么执行的速度就越慢。 - Examine the assembly code(检查shader对应的汇编代码)
通过配置HLSL编译器的命名行参数可以输出每一个shader的汇编指令。打开工程的Property Page对话框,选择Configuration Properties–>HLSL Compiler–>Command Line,然后在
Additional Opetions区域添加几下配置:
/Fc”$(OutDir)Content\Effects\%(Filename).asm”
列表22.1中显示了BlinnPhongInstrincs.fx的pixel shader对应的release版本的汇编代码。
列表22.1 Assembly Code for the Pixel Shader from BlinnPhongIntrinsics.fx
PixelShader = asm{
ps_5_0
dcl_globalFlags refactoringAllowed
dcl_constantbuffer cb0[2], immediateIndexed
dcl_constantbuffer cb1[10], immediateIndexed
dcl_sampler s0, mode_default
dcl_resource_texture2d(float,float,float,float) t0
dcl_input_ps linear v1.xyz
dcl_input_ps linear v2.xy
dcl_input_ps linear v3.xyz
dcl_input_ps linear v4.xyz
dcl_output o0.xyzw
dcl_temps 3
dp3 r0.x, v4.xyzx, v4.xyzx
rsq r0.x, r0.x
dp3 r0.y, v3.xyzx, v3.xyzx
rsq r0.y, r0.y
mul r0.yzw, r0.yyyy, v3.xxyz
mad r1.xyz, v4.xyzx, r0.xxxx, r0.yzwy
dp3 r0.x, r1.xyzx, r1.xyzx
rsq r0.x, r0.x
mul r1.xyz, r0.xxxx, r1.xyzx
dp3 r0.x, v1.xyzx, v1.xyzx
rsq r0.x, r0.x
mul r2.xyz, r0.xxxx, v1.xyzx
dp3 r0.x, r2.xyzx, r1.xyzx
dp3 r0.y, r2.xyzx, r0.yzwy
ge r0.zw, r0.xxxy, l(0.000000, 0.000000, 0.000000, 0.000000)
log r0.x, r0.x
mul r0.x, r0.x, cb1[9].x
exp r0.x, r0.x
max r0.y, r0.y, l(0.000000)
and r0.z, r0.w, r0.z
and r0.x, r0.x, r0.z
sample_indexable(texture2d)(float,float,float,float) r1.xyzw,
v2.xyxx, t0.xyzw, s0
min r0.x, r0.x, r1.w
mul r0.yzw, r0.yyyy, r1.xxyz
mul r2.xyz, cb0[1].wwww, cb0[1].xyzx
mul r0.yzw, r0.yyzw, r2.xxyz
mul r2.xyz, cb0[0].wwww, cb0[0].xyzx
mad r0.yzw, r2.xxyz, r1.xxyz, r0.yyzw
mul r1.xyz, cb1[8].wwww, cb1[8].xyzx
mad o0.xyz, r1.xyzx, r0.xxxx, r0.yzwy
mov o0.w, l(1.000000)
ret
// Approximately 32 instruction slots used
};通过检查汇编代码,可以看出哪些是完全由shader代码直接生成的指令,哪些是值得商榷的重构部分的指令。也就是说显卡驱动会对这些指令做进一步处理以用于实际的显示中。因此,要查看某个具体驱动程序生成的指令,需要使用针对具体显卡供应商的应用程序。
- Use intrinsic functions(使用HLSL内置函数)
在第6章“Lighting Models”使用HLSL内置函数lit()计算diffuse和specular系数时已经讨论了这个概念。相对于自己编写代码实现两样的功能,使用内置函数会产生更少的指令以及更高的性能。
Don’t perform calculations on otherwise constant data(不要计算常量值)
回顾一下在shaders中执行的计算光照强度的乘法运算代码(比如,sampledColor.rgb * ambientColor.rgb * ambientIntensity)。其中,对于绘制过程中的每一个pixel来说,ambientColor.rgb * ambientColor.a相乘的结果都是一个常量值。因此,最好是在CPU中计算该常数值,并发送到shader中。在第6章已经详细讲解了这个问题,但也值得在这里两次强调。本书中的shaders都是在pixel shader中计算,只是为了与NVIDIA FX Composer交互时更加简单。
这一节只是非常浅显的讲述了这些主题,但是这些准则能够带给你正确的优化方向。
Hardware Instancing
关于优化相关的主题,我们最后一个要讨论的是hardware instancing,表示只调用一次绘制操作就可以对同一个mesh data渲染多个实例。这种方法通常用于在一个场景中绘制重复的geometry。但是,由于每一个实例都共享同一个geometry数据,因此每一个实例(至少)要有一个唯一的world matrix,可能还有一些其他的属性值用于与其他的实例副本区别开来。在不使用hardware instancing方法时,对同一个vertex buffer调用多次绘制函数也可以渲染同一个mesh的多个实例,而且每一次调用,都需要更新object对应的shader常量值。尽管这样可以绘制多个实例,但是每一次绘制调用以及material的更新都会导致额外的API调用开销。而hardware instancing就是用于减少这种开销。
要使用hardware instancing方法,需要在per-instance的变量中增加要发送到input-assembler阶段的相关数据。列表22.2中列出了在point light shader中使用hardware instancing的代码。其中,VS_INPUT结构新增了用于表示object的world matrix,specualr power以及specular color的变量。
列表22.2 An Instancing Point Light Shader
#include "include\\Common.fxh"
/************* Resources *************/
cbuffer CBufferPerFrame
{
float4 AmbientColor = {1.0f, 1.0f, 1.0f, 0.0f};
float4 LightColor = {1.0f, 1.0f, 1.0f, 1.0f};
float3 LightPosition = {0.0f, 0.0f, 0.0f};
float LightRadius = 10.0f;
float3 CameraPosition : CAMERAPOSITION;
}
cbuffer CBufferPerObject
{
float4x4 ViewProjection : VIEWPROJECTION;
}
Texture2D ColorTexture;
SamplerState TrilinearSampler
{
Filter = MIN_MAG_MIP_LINEAR;
AddressU = WRAP;
AddressV = WRAP;
};
/************* Data Structures *************/
struct VS_INPUT
{
float4 ObjectPosition : POSITION;
float2 TextureCoordinate : TEXCOORD;
float3 Normal : NORMAL;
row_major float4x4 World : WORLD;
float4 SpecularColor : SPECULARCOLOR;
float SpecularPower : SPECULARPOWER;
};
struct VS_OUTPUT
{
float4 Position : SV_Position;
float3 Normal : NORMAL;
float2 TextureCoordinate : TEXCOORD;
float3 WorldPosition : WORLD;
float Attenuation : ATTENUATION;
float4 SpecularColor : SPECULAR;
float SpecularPower : SPECULARPOWER;
};
/************* Vertex Shader *************/
VS_OUTPUT vertex_shader(VS_INPUT IN)
{
VS_OUTPUT OUT = (VS_OUTPUT)0;
OUT.WorldPosition = mul(IN.ObjectPosition, IN.World).xyz;
OUT.Position = mul(float4(OUT.WorldPosition, 1.0f), ViewProjection);
OUT.Normal = normalize(mul(float4(IN.Normal, 0), IN.World).xyz);
OUT.TextureCoordinate = IN.TextureCoordinate;
float3 lightDirection = LightPosition - OUT.WorldPosition;
OUT.Attenuation = saturate(1.0f - (length(lightDirection) / LightRadius));
OUT.SpecularColor = IN.SpecularColor;
OUT.SpecularPower = IN.SpecularPower;
return OUT;
}
/************* Pixel Shader *************/
float4 pixel_shader(VS_OUTPUT IN) : SV_Target
{
float4 OUT = (float4)0;
float3 lightDirection = LightPosition - IN.WorldPosition;
lightDirection = normalize(lightDirection);
float3 viewDirection = normalize(CameraPosition - IN.WorldPosition);
float3 normal = normalize(IN.Normal);
float n_dot_l = dot(normal, lightDirection);
float3 halfVector = normalize(lightDirection + viewDirection);
float n_dot_h = dot(normal, halfVector);
float4 color = ColorTexture.Sample(TrilinearSampler, IN.TextureCoordinate);
float4 lightCoefficients = lit(n_dot_l, n_dot_h, IN.SpecularPower);
float3 ambient = get_vector_color_contribution(AmbientColor, color.rgb);
float3 diffuse = get_vector_color_contribution(LightColor, lightCoefficients.y * color.rgb) * IN.Attenuation;
float3 specular = get_scalar_color_contribution(IN.SpecularColor, min(lightCoefficients.z, color.w)) * IN.Attenuation;
OUT.rgb = ambient + diffuse + specular;
OUT.a = 1.0f;
return OUT;
}
/************* Techniques *************/
technique11 main11
{
pass p0
{
SetVertexShader(CompileShader(vs_5_0, vertex_shader()));
SetGeometryShader(NULL);
SetPixelShader(CompileShader(ps_5_0, pixel_shader()));
}
}在VS_INPUT结构体中新增的变量替代了全局的shader常量,并在vertex和pixel shaders中用于变换object的坐标位置以及计算specular。另外,在全局的ViewProjection变量中,已经去掉了world matrix分量。在所有的实例中ViewProjection矩阵都是常量值,但是world matrix则是由per-instance data提供。
在CPU端应用程序中,需要更新input layout以匹配新的input signature。对于D3D11_INPUT_ELEMENT_DESC结构体的InputSlotClass成员,不再使用之前的D3D11_INPUT_PER_VERTEX_DATA枚举变量值,而是对每一个实例数据成员使用D3D11_INPUT_PER_INSTANCE_DATA枚举值。以下代码演示了用于表示shader输出结构的input element数组,如列表22.2所示:
D3D11_INPUT_ELEMENT_DESC inputElementDescriptions[] =
{
{ "POSITION", 0, DXGI_FORMAT_R32G32B32A32_FLOAT, 0, 0, D3D11_INPUT_PER_VERTEX_DATA, 0 },
{ "TEXCOORD", 0, DXGI_FORMAT_R32G32_FLOAT, 0, 16, D3D11_INPUT_PER_VERTEX_DATA, 0 },
{ "NORMAL", 0, DXGI_FORMAT_R32G32B32_FLOAT, 0, 24, D3D11_INPUT_PER_VERTEX_DATA, 0 },
{ "WORLD", 0, DXGI_FORMAT_R32G32B32A32_FLOAT, 1, 0, D3D11_INPUT_PER_INSTANCE_DATA, 1 },
{ "WORLD", 1, DXGI_FORMAT_R32G32B32A32_FLOAT, 1, 16, D3D11_INPUT_PER_INSTANCE_DATA, 1 },
{ "WORLD", 2, DXGI_FORMAT_R32G32B32A32_FLOAT, 1, 32, D3D11_INPUT_PER_INSTANCE_DATA, 1 },
{ "WORLD", 3, DXGI_FORMAT_R32G32B32A32_FLOAT, 1, 48, D3D11_INPUT_PER_INSTANCE_DATA, 1 },
{ "SPECULARCOLOR", 0, DXGI_FORMAT_R32G32B32A32_FLOAT, 1, 64, D3D11_INPUT_PER_INSTANCE_DATA, 1 },
{ "SPECULARPOWER", 0, DXGI_FORMAT_R32_FLOAT, 1, 80, D3D11_INPUT_PER_INSTANCE_DATA, 1 }
};在D3D11_INPUT_ELEMENT_DESC结构体中新增加的input element descriptions需要重点关注一下。其中,4个新增的WORLD元素,都表示4×32-bit的浮点数;并使用semantic索引值0,1,2,3标明(semantic索引值是D3D_INPUT_ELEMENT_DESC结构体中的第二个成员)。这4个元素指定了用于输入shader中的4×4 world matrix的16个浮点值。另外需要注意的是,所有的per-instance元素都是使用索引值为1的slot 传递到input-assembler阶段(slot是D3D_INPUT_ELEMENT_DESC结构体中的第4个成员,位于表示数据格式的成员的下一个)。在input-assembler(IA)阶段,包含16个input slots,在一次绘制调用中最多可以支持16个vertex buffers。使用不同的slots可以把实例数据存储在一个vertex buffer中,与存储geometry数据的buffer分开。使用这种方法,就可以单独更新instance buffer。最后需要注意的是,每一个per-instance element的最后一个结构体成员(InstanceDataStepRate)都被赋值为1。该变量值表示在指向instance buffer的中下一个元素之前,使用同一个per-instance data绘制的实例数量。
列表22.3中hardware instancing示例程序的初始化和绘制函数代码。本书配套网站上提供了完整的示例代码。
列表22.3 Initialization and Draw Calls for the Hardware Instancing Demo
void InstancingDemo::Initialize()
{
SetCurrentDirectory(Utility::ExecutableDirectory().c_str());
std::unique_ptr<Model> model(new Model(*mGame, "Assets\\Models\\Sphere.obj", true));
// Initialize the material
mEffect = new Effect(*mGame);
mEffect->LoadCompiledEffect(L"Assets\\Effects\\Instancing.cso");
mMaterial = new InstancingMaterial();
mMaterial->Initialize(mEffect);
// Create vertex buffer
Mesh* mesh = model->Meshes().at(0);
ID3D11Buffer* vertexBuffer = nullptr;
mMaterial->CreateVertexBuffer(mGame->Direct3DDevice(), *mesh, &vertexBuffer);
mVertexBuffers.push_back(VertexBufferData(vertexBuffer, mMaterial->VertexSize(), 0));
// Create instance buffer
std::vector<InstancingMaterial::InstanceData> instanceData;
UINT axisInstanceCount = 5;
float offset = 20.0f;
for (UINT x = 0; x < axisInstanceCount; x++)
{
float xPosition = x * offset;
for (UINT z = 0; z < axisInstanceCount; z++)
{
float zPosition = z * offset;
instanceData.push_back(InstancingMaterial::InstanceData(XMMatrixTranslation(-xPosition, 0, -zPosition), ColorHelper::ToFloat4(mSpecularColor), mSpecularPower));
instanceData.push_back(InstancingMaterial::InstanceData(XMMatrixTranslation(xPosition, 0, -zPosition), ColorHelper::ToFloat4(mSpecularColor), mSpecularPower));
}
}
ID3D11Buffer* instanceBuffer = nullptr;
mMaterial->CreateInstanceBuffer(mGame->Direct3DDevice(), instanceData, &instanceBuffer);
mInstanceCount = instanceData.size();
mVertexBuffers.push_back(VertexBufferData(instanceBuffer, mMaterial->InstanceSize(), 0));
// Create index buffer
mesh->CreateIndexBuffer(&mIndexBuffer);
mIndexCount = mesh->Indices().size();
std::wstring textureName = L"Assets\\Textures\\EarthComposite.jpg";
HRESULT hr = DirectX::CreateWICTextureFromFile(mGame->Direct3DDevice(), mGame->Direct3DDeviceContext(), textureName.c_str(), nullptr, &mColorTexture);
if (FAILED(hr))
{
throw GameException("CreateWICTextureFromFile() failed.", hr);
}
mPointLight = new PointLight(*mGame);
mPointLight->SetRadius(100.0f);
mPointLight->SetPosition(5.0f, 0.0f, 10.0f);
mKeyboard = (Keyboard*)mGame->Services().GetService(Keyboard::TypeIdClass());
assert(mKeyboard != nullptr);
mProxyModel = new ProxyModel(*mGame, *mCamera, "Assets\\Models\\PointLightProxy.obj", 0.5f);
mProxyModel->Initialize();
mRenderStateHelper = new RenderStateHelper(*mGame);
mSpriteBatch = new SpriteBatch(mGame->Direct3DDeviceContext());
mSpriteFont = new SpriteFont(mGame->Direct3DDevice(), L"Assets\\Fonts\\Arial_14_Regular.spritefont");
}
void InstancingDemo::Update(const GameTime& gameTime)
{
UpdateAmbientLight(gameTime);
UpdatePointLight(gameTime);
mProxyModel->Update(gameTime);
}
void InstancingDemo::Draw(const GameTime& gameTime)
{
ID3D11DeviceContext* direct3DDeviceContext = mGame->Direct3DDeviceContext();
direct3DDeviceContext->IASetPrimitiveTopology(D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST);
Pass* pass = mMaterial->CurrentTechnique()->Passes().at(0);
ID3D11InputLayout* inputLayout = mMaterial->InputLayouts().at(pass);
direct3DDeviceContext->IASetInputLayout(inputLayout);
ID3D11Buffer* vertexBuffers[2] = { mVertexBuffers[0].VertexBuffer, mVertexBuffers[1].VertexBuffer };
UINT strides[2] = { mVertexBuffers[0].Stride, mVertexBuffers[1].Stride };
UINT offsets[2] = { mVertexBuffers[0].Offset, mVertexBuffers[1].Offset };
direct3DDeviceContext->IASetVertexBuffers(0, 2, vertexBuffers, strides, offsets);
direct3DDeviceContext->IASetIndexBuffer(mIndexBuffer, DXGI_FORMAT_R32_UINT, 0);
mMaterial->ViewProjection() << mCamera->ViewMatrix() * mCamera->ProjectionMatrix();
mMaterial->AmbientColor() << XMLoadColor(&mAmbientColor);
mMaterial->LightColor() << mPointLight->ColorVector();
mMaterial->LightPosition() << mPointLight->PositionVector();
mMaterial->LightRadius() << mPointLight->Radius();
mMaterial->ColorTexture() << mColorTexture;
mMaterial->CameraPosition() << mCamera->PositionVector();
pass->Apply(0, direct3DDeviceContext);
direct3DDeviceContext->DrawIndexedInstanced(mIndexCount, mInstanceCount, 0, 0, 0);
mProxyModel->Draw(gameTime);
mRenderStateHelper->SaveAll();
mSpriteBatch->Begin();
std::wostringstream helpLabel;
helpLabel << L"Ambient Intensity (+PgUp/-PgDn): " << mAmbientColor.a << "\n";
helpLabel << L"Point Light Intensity (+Home/-End): " << mPointLight->Color().a << "\n";
helpLabel << L"Move Point Light (8/2, 4/6, 3/9)\n";
mSpriteFont->DrawString(mSpriteBatch, helpLabel.str().c_str(), mTextPosition);
mSpriteBatch->End();
mRenderStateHelper->RestoreAll();
}在初始化函数中创建了一组spheres排列在xz-平面上,并使用instance data创建一个vertex buffer用于绘制调用。在绘制函数中,通过调用ID3D11DeviceContext::IASetVertexBuffers()指定了两个buffers,然后使用object的index数量和要绘制的实例的数量作为参数,调用ID3D11DeviceContext::DrawIndexInstanced()函数进行绘制。在该示例的Update()函数中可以修改instance buffer或添加(删除)instances。图22.1中显示了hardware instancing示例中输出结果。
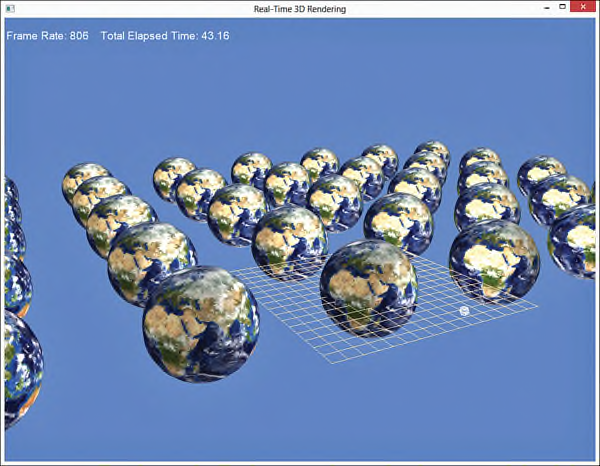
图22.1 Output of the hardware instancing demo. (Original texture from Reto Stöckli, NASA Earth Observatory. Additional texturing by Nick Zuccarello, Florida Interactive Entertainment Academy.)















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









