






前言
在本地安装好ollama后,下载加载模型总是失败,出现的错误信息为:
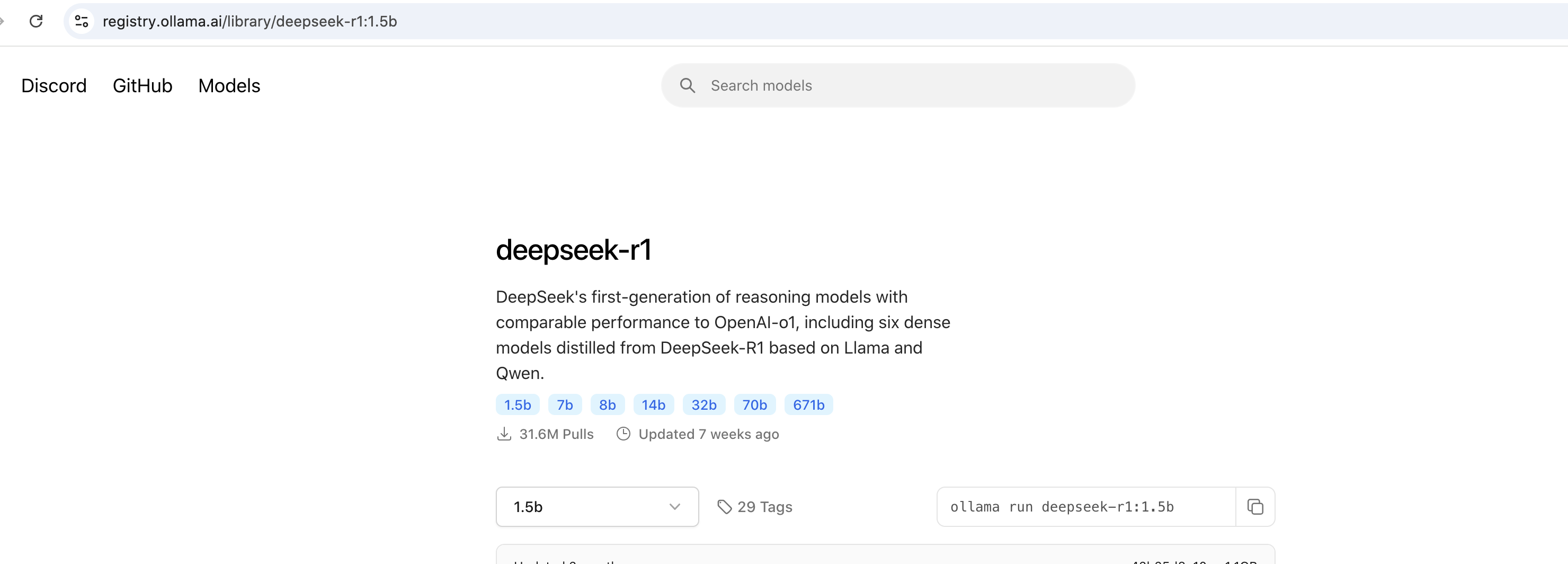
ollama run deepseek-r1:1.5b
Error: pull model manifest: Get "https://registry.ollama.ai/v2/library/deepseek-r1/manifests/1.5b": net/http: TLS handshake timeout。 重试了比较多的方法,都没能成功,所以出现了本文离线下载gguf模型文件,然后再倒入ollama运行的原因。
如何下载离线模型
最快下载离线模型的方式是直接去huggingface上找模型。比如找千问的模型
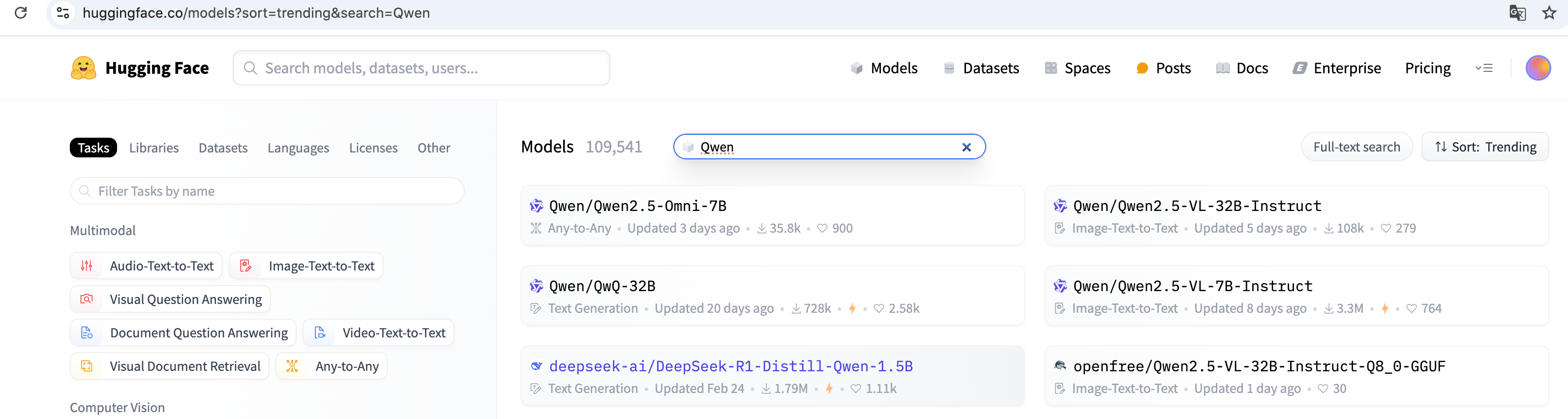
直接找到的模型,看模型文件都是safetensors
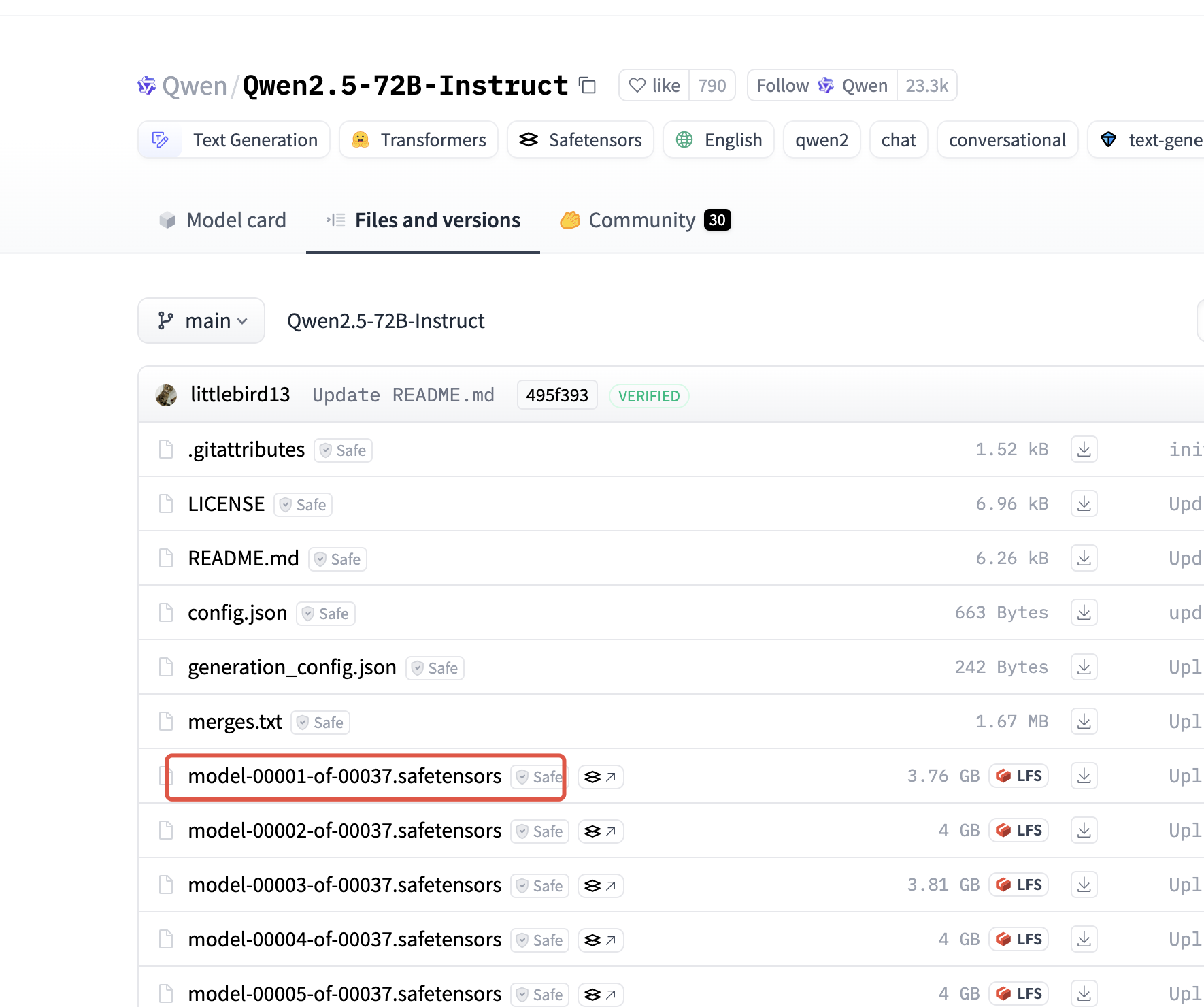
ollama没法直接加载safetensors格式。
safetensors和gguf模型格式区别
-
Safetensors:
-
由 Hugging Face 推出的一种新型安全的模型存储格式,主要用于保存模型的权重参数。
-
特别关注模型的安全性和隐私保护,不包含执行代码,减少了模型文件的大小并提高了加载速度。
-
支持零拷贝(zero-copy)和懒加载(lazy loading),没有文件大小限制,并且支持 bfloat16/fp8 数据类型。
-
不包含模型的元数据信息,在大模型高效序列化、数据压缩、量化等方面存在不足。
-
-
GGUF:
-
是一种针对大模型的二进制文件格式,专为 GGML 及其执行器快速加载和保存模型而设计,是 GGML 格式的替代者。
-
包含加载模型所需的所有信息,无需依赖外部文件,简化了模型部署和共享的过程,有助于跨平台操作。
-
支持量化技术,可以降低模型的资源消耗,并且设计为可扩展的,以便在不破坏兼容性的情况下添加新信息。
-
小结:
-
Safetensors 更侧重于安全性和效率,适合快速部署和对安全性有较高要求的场景。
-
GGUF 格式则是一种为大模型设计的二进制文件格式,优化了模型的加载速度和资源消耗,适合需要频繁加载不同模型的场景。
如何找到gguf模型文件
直接在unsloth下搜索,大部分都是gguf格式的。https://huggingface.co/unsloth
safetensors如何转gguf格式
参考文献如何将SafeTensors模型转换为GGUF格式_safetensors转换为gguf-CSDN博客
注意:不是所有的safetensors格式都可以转换成gguf的
如何加载本地大模型
- 将模型文件拷贝到ollama的模型文件
cp xxxx.gguf ~/.ollama/models
- 创建Modelfile文件
FROM qwen2.5-7b-instruct-q5_0.gguf
# set the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 0.7
PARAMETER top_p 0.8
PARAMETER repeat_penalty 1.05
PARAMETER top_k 20TEMPLATE """{{ if .Messages }}
{{- if or .System .Tools }}<|im_start|>system
{{ .System }}
{{- if .Tools }}# Tools
You are provided with function signatures within <tools></tools> XML tags:
<tools>{{- range .Tools }}
{"type": "function", "function": {{ .Function }}}{{- end }}
</tools>For each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:
<tool_call>
{"name": <function-name>, "arguments": <args-json-object>}
</tool_call>
{{- end }}<|im_end|>
{{ end }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1 -}}
{{- if eq .Role "user" }}<|im_start|>user
{{ .Content }}<|im_end|>
{{ else if eq .Role "assistant" }}<|im_start|>assistant
{{ if .Content }}{{ .Content }}
{{- else if .ToolCalls }}<tool_call>
{{ range .ToolCalls }}{"name": "{{ .Function.Name }}", "arguments": {{ .Function.Arguments }}}
{{ end }}</tool_call>
{{- end }}{{ if not $last }}<|im_end|>
{{ end }}
{{- else if eq .Role "tool" }}<|im_start|>user
<tool_response>
{{ .Content }}
</tool_response><|im_end|>
{{ end }}
{{- if and (ne .Role "assistant") $last }}<|im_start|>assistant
{{ end }}
{{- end }}
{{- else }}
{{- if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
{{ end }}{{ .Response }}{{ if .Response }}<|im_end|>{{ end }}"""# set the system message
SYSTEM """You are Qwen, created by Alibaba Cloud. You are a helpful assistant."""
- 加载模型
ollama create qwen2.5-coder-7b-q3km -f Modelfile
- 运行模型
ollama run qwen2.5-coder-7b-q3km

ollama如何同时加载多个大模型
如果本地资源充足,ollama可以同时加载多个大模型,梳理出来有三种方式:
方式1:docker镜像隔离
-- 下载docker镜像
docker pull ollama/ollama:latest
-- 启动镜像实例
docker run -d \ --name ollama-model1 \ -p 11434:11434 \ -v ollama-model1:/root/.ollama \ ollama/ollama:latest \ serve --model llama3:8b
方式2:Server 不同的端口启动
-- 针对每个模型文件创建Modelfile,然后加载模型
ollama create llama3-8b -f llama3.Modelfile
ollama create mistral-7b -f mistral.Modelfile
方式3:同实例同时加载多个模型
-
确保使用的是 Ollama 的最新版本(v0.1.33 或更高版本)
-
设置环境变量,
OLLAMA_NUM_PARALLEL环境变量来指定并发请求数量。OLLAMA_MAX_LOADED_MODELS环境变量来指定同时加载的模型数量。
set OLLAMA_NUM_PARALLEL=2
set OLLAMA_MAX_LOADED_MODELS=2
ollama serve
ollama run gemma:2b ollama run llama3:8b

















 919
919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









