







目录
1. 概要
DTW( Dynamic Time Warping,动态时间规整)是基于动态规划(Dynamic Programming)策略对两个时序列通过非线性地进行时域对准(Timing alignment)调整以便于正确地计算两者之间相似度(similarity)的一种算法。
本文简单介绍DTW算法所针对的问题背景、DTW基本算法流程,并给出简单的Python实现例。
本文如标题“初识。。。”所示,面向像作者这样初次接触DTW的渣渣^-^。不过本文并不准备动态规划策略进行描述,所以本文要求读者对动态规划有基本的了解。
2. 时序列相似度度量
考虑如下所示的几个时序列波形之间的“相似度”的比较。时序列波形之间的相似度的衡量的一种方法就是把时序列波形看作是一个向量,然后计算两个向量之间的欧几里得距离。除了欧几里得距离以外,其它的相似度度量还有比如说余弦相似度(cosine similarity)。
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 30 10:50:53 2021
@author: chenxy
"""
import numpy as np
import matplotlib.pyplot as plt
def euclid_dist(t1,t2):
return np.sqrt(np.sum((t1-t2)**2))
t = np.arange(100)
ts1 = 5*np.sin(2*np.pi*t*0.05) # 0.05Hz sin wave, 1Hz sampling rate, amplitude=5
ts2 = 3*np.sin(2*np.pi*t*0.02) # 0.02Hz sin wave, 1Hz sampling rate, amplitude=3
ts3 = 0.08*t-4
fig,axs = plt.subplots(figsize=(12,8))
axs.plot(ts1)
axs.plot(ts2)
axs.plot(ts3)
axs.legend(['ts1: sin,0.05Hz, amplitude=5',\
'ts2: sin,0.02Hz, amplitude=3',\
'ts3: line with slope = 0.08'])
euclidean_dist_12 = euclid_dist(ts1,ts2)
euclidean_dist_13 = euclid_dist(ts1,ts3)
euclidean_dist_23 = euclid_dist(ts2,ts3)
print('euclidean_dist_12 = {0:6.2f}'.format(euclidean_dist_12))
print('euclidean_dist_13 = {0:6.2f}'.format(euclidean_dist_13))
print('euclidean_dist_23 = {0:6.2f}'.format(euclidean_dist_23))运行后得到:

图1
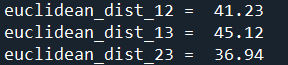
如果直接采用欧几里得距离作为相似性度量的话,如以上结果可得,ts2和ts3之间的距离最小,或者说相似度最高。但是,从人类的直觉来看的话,由于ts1和ts2都是正弦波,只不过频率和幅度不同而已,而ts3是一根直线,显然应该是ts1和ts2更相似才合理。
进一步,考虑一个与ts1频率、幅度都相等,但是相位差180度的正弦波。
ts4 = 5*np.sin(2*np.pi*t*0.05+np.pi) # 0.05Hz sin wave, 1Hz sampling rate, amplitude=5
fig,axs = plt.subplots(figsize=(12,8))
axs.plot(ts1)
axs.plot(ts4)
axs.plot(ts3)
axs.legend(['ts1: sin,0.05Hz, amplitude=5',\
'ts4: sin,0.05Hz, amplitude=5, phase offset=pi',\
'ts3: line with slope = 0.08'])
euclidean_dist_14 = euclid_dist(ts1,ts4)
euclidean_dist_34 = euclid_dist(ts3,ts4)
print('euclidean_dist_14 = {0:6.2f}'.format(euclidean_dist_14))
print('euclidean_dist_34 = {0:6.2f}'.format(euclidean_dist_34))运行后得到:
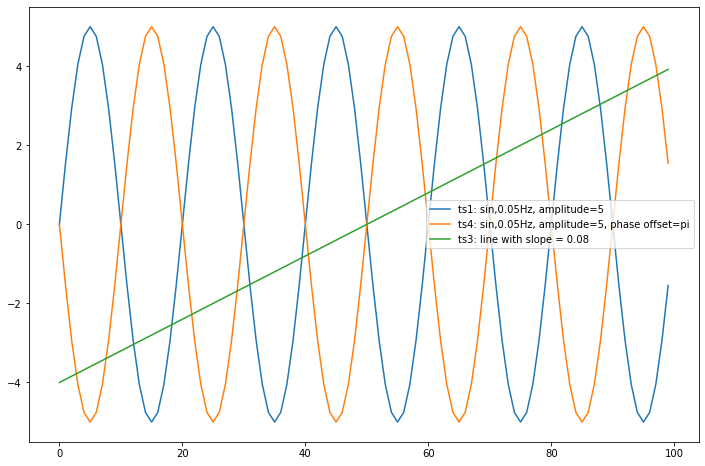
图2
![]()
这一次结果更加明显地反直觉。Ts1与ts4仅仅只是反相而已,而它们之间的”距离”居然会远远大于ts3与ts4之间的距离!
造成以上反直觉的结果的原因在于:Ts1,ts2,ts4之间虽然基本波形其实是相似的,但是在时域存在没有对准(或者说不同步)的问题。Ts1和ts4之间相位相反也可以看作是时域未对准,因为可以把ts4看作是ts1延迟半个周期的波形。而ts2与ts1之间则不仅仅是相位偏差导致的时域未对准,还有因为他们的周期不同而导致相位的偏差是随时间变化的。
以上的情况还只是最简单的情况。因为ts1和ts2和ts4同是正弦波,差异在于相位和频率,但是相位和频率差异是固定的。因此,通过对其中一个信号进行相位调整的扫描以及对时域波形扩张(对应于改变频率)的扫描,然后再进行信号处理中的相关运算是可以正确地识别出它们之间的相似度来的。
在真实世界中,两个原本相似度很高的时序列之间可能时域上相对变形(distortion)程度不但是时变的,而且还是非线性变化的。将一段语音变速播放就会产生这种类似的效果。这种情况下要想正确识别出它们之间的相似度,就需要先对两者之间局部时域波形的相对变形进行纠正以后再计算欧几里得距离。“对两者之间局部时域波形的相对变形纠正”称为Time-Warping(时域规整)处理。经过Time-Warping(时域规整)处理后,两个序列中样点间不再保持一一对应关系,而是可能出现一些一对多或者多对一的关系,相当于局部范围内时域波形出现了相对压缩或者拉伸后再进行对应,如下图所示:

图3
3. DTW基本算法
DTW算法就是基于动态规划策略对两个时序列进行动态的时域规整处理后以搜索估计它们之间最小可能的距离(最大可能的相似度)。广泛地用于时序列分类和聚类等应用中。
DTW算法基本工作原理如下所述:
考虑两个时序列和
,长度分别为n和m(直接计算两个序列之间的欧氏距离要求两者长度相等。但是,基于DTW算法来估计相似度并不要求长度相等)。
首先,构建一个n*m的矩阵D,其中D[i,j]表示Qi与Pj之间的欧氏距离(注意,为了描述方便,下标是从1开始计数(记为1-indexed)。但是在python或C代码实现中则是从0开始计数,称为0-indexed)。DTW的目标就是要找到一条从[1,1]到[n,m]的路径使得该条路径的累积欧氏距离最小。
如前所述,在Time Warping处理中,一个时序列上的一个点可以对应另一个时序列的一个或者多个点。对应地,在以上矩阵D中的路径(从左上角的[1,1]出发的)构造过程中,可以从一个格点到达其右边、下边以及右下的格点。理论上,也可以走向其它5个方向的格点,但是这样肯定会导致非最小化的距离,因此可以不用考虑。
考虑表示一条从[1,1]到[n,m]的路径,其中Wk表示路径经过的某格点所保存的Q和C之间某两点
之间的欧氏距离的平方
![]() (注意,这里用平方而不是绝对值,是因为两个时序列之间的距离是要先进行平方和运算再开方的)。如下图所示就是一条可能的路径。
(注意,这里用平方而不是绝对值,是因为两个时序列之间的距离是要先进行平方和运算再开方的)。如下图所示就是一条可能的路径。

图4
这样,以上最小累计距离搜索的优化问题可以表述为求解
![]()
如上图所示,将从[1,1]到达[i,j]的累计距离记为![]() 。
。
很显然,经历最短累计距离到达[i,j]的前一个点必然是[i-1,j-1], [i,j-1], [i-1,j]三者之一。在已经计算出[i-1,j-1], [i,j-1], [i-1,j]各自所对应的最短累计距离的前提下,可以得到关于![]() 的递推关系式如下:
的递推关系式如下:
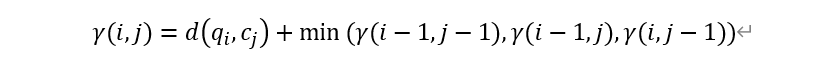
基于这个递推关系式,可以从[1,1]开始逐行(或逐列也可以)计算并填充关于的表格,填充完整个表格后即可以得到两个序列之间的最短距离
![]() ,这个距离通常也称为DTW距离。
,这个距离通常也称为DTW距离。
进一步,记录以上关于的创建过程中的路径选择历史的话,可以从[n,m]回溯得到最优路径所经历的所有格点。也就可以据此得到如以上图3那样的Time Warping映射图。
4. Python实现
DTW算法实现如以下函数DTWDistance()所示。基于这一函数我们来重新评估以上4个序列之间的DTW距离。
"""
DTWDistance(s1, s2) is copied from:
http://alexminnaar.com/2014/04/16/Time-Series-Classification-and-Clustering-with-Python.html
"""
def DTWDistance(s1, s2):
DTW={}
for i in range(len(s1)):
DTW[(i, -1)] = float('inf')
for i in range(len(s2)):
DTW[(-1, i)] = float('inf')
DTW[(-1, -1)] = 0
for i in range(len(s1)):
for j in range(len(s2)):
dist= (s1[i]-s2[j])**2
DTW[(i, j)] = dist + min(DTW[(i-1, j)],DTW[(i, j-1)], DTW[(i-1, j-1)])
return np.sqrt(DTW[len(s1)-1, len(s2)-1])
dtw_dist_12 = DTWDistance(ts1,ts2)
dtw_dist_13 = DTWDistance(ts1,ts3)
dtw_dist_14 = DTWDistance(ts1,ts4)
dtw_dist_23 = DTWDistance(ts2,ts3)
dtw_dist_24 = DTWDistance(ts2,ts4)
dtw_dist_34 = DTWDistance(ts3,ts4)
print('dtw_dist_12 = {0:6.2f}'.format(dtw_dist_12))
print('dtw_dist_14 = {0:6.2f}'.format(dtw_dist_14))
print('dtw_dist_24 = {0:6.2f}'.format(dtw_dist_24))
print('dtw_dist_23 = {0:6.2f}'.format(dtw_dist_23))
print('dtw_dist_13 = {0:6.2f}'.format(dtw_dist_13))
print('dtw_dist_34 = {0:6.2f}'.format(dtw_dist_34))运行结果如下:

由此可以看出ts3(直线)与其它三者之间的DTW距离都比其它三者之间的相互的DTW距离要大,也就是说ts1,2,4相互之间的相似度是要大于ts3与ts1,2,4之间的相似度的。
5. Next Action
- DTW算法的运算复杂度优化
- 以上提到过的\gamma表格建立中的路径选择历史的记录以及最优路径回复,以及Time Warping可视化
- 基于DTW与KNN结合的时序列分类(classification)和聚类(clustering)的应用示例
Reference:
[1]http://alexminnaar.com/2014/04/16/Time-Series-Classification-and-Clustering-with-Python.html


















 1189
1189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











