







 本文详细介绍了机器学习中常用的softmax函数、cross-entropy损失函数及其梯度推导,包括单变量、向量梯度和batch实施,以及它们在深度学习中的应用和Python实现。
本文详细介绍了机器学习中常用的softmax函数、cross-entropy损失函数及其梯度推导,包括单变量、向量梯度和batch实施,以及它们在深度学习中的应用和Python实现。
目录
4.5 cross-entropy loss gradient
5. Gradient of "softmax + cross-entropy" combo
1. 概要
简要介绍机器学习、深度学习中常用的softmax函数,cross-entropy损失函数,以及它们的梯度推导(尤其是softmax和cross-entropy loss级联后的梯度推导)。特别地,从对单个变量的偏导数,到对输入向量的偏导数(即梯度),乃至到对整个batch的梯度的矩阵表示。最后,给出对应的python实现。这些将成为完全DIY用python实现一个分类神经网络的一个基本构成模块。
2. Sigmoid function
Sigmoid函数(也称为Logistic函数)是一种常用的非线性激活函数,它将输入值映射到一个介于0和1之间的值域。其定义为:
(1)
其中,Sigmoid函数的图像呈S形,常用于神经网络中作为激活函数使用,将输出值转换为概率值。Sigmoid函数的优点在于它有很好的数学特性,单调、连续、可导,且其导函数非常“漂亮”(九可以用Sigmoid函数自己表示,因此非常方便于实现)!Sigmoid函数导数可以表示为:
(2)
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(z):
'''
'''
return 1 / (1 + np.exp(-z))
x = np.arange(100) * 0.1 - 5
y = sigmoid(x)
y_derivative = y * (1 - y)
plt.plot(x,y, label = 'sigmoid')
plt.plot(x,y_derivative, label = 'derivative of sigmoid')
plt.legend() 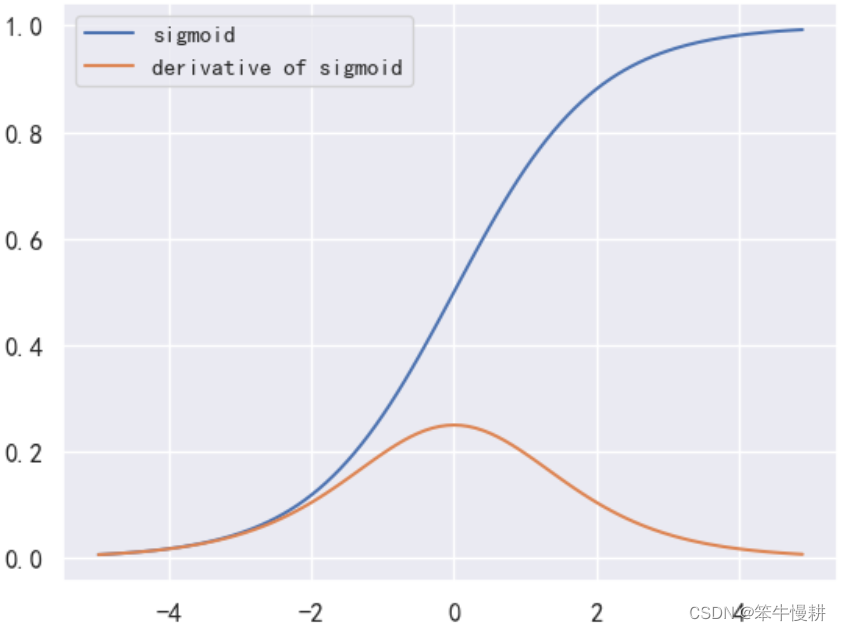
图1:sigmoid and its derivative
但是,从深度学习的角度来看,Sigmoid的缺点也是明显的。如上图所示,当输入数据绝对值较大时,函数的导数接近于0,这容易导致梯度消失的问题,影响神经网络的训练效果。因此,事实上在现代深度学习中,Sigmoid函数在大部分情况下(用作隐藏层的激活函数)都被更有效的激活函数(如ReLU、LeakyReLU等)所取代。通常只用于二值分类神经网络的输出层。
3. Softmax function
3.1 定义
Sigmoid函数适用于二分类问题,对于多分类问题,需要在Sigmoid函数的基础上进行扩展,这个扩展就得到Softmax函数。softmax函数的输入通常是一个向量,输出是一个相同大小的向量。softmax函数的特点是能够将任意实数向量转换为一个概率分布(严格地来说,是转换为符合概率公理的一组数据,因此可以当作概率值使用)。其输出是一个和为1的向量,其中每个元素表示对应类别的概率。其公式为:
(3)
其中,z表示一个向量,其中有n个分量(对应于n分类问题)。
考虑n=2的情况,
(4)
(5)
假定z1和z2分别表示类别1和类别2的评价分数,则显然,z1>z2表示结果应该被判定为类别1,z1<z2表示结果应该被判定为类别2(相等时,可以随意)。现在,令:z=z1-z2。则判决准则变为z>0表示应该被判定为类别1,z<0表示应该被判定为类别2。
(6)
由此可以看到,在两分类问题(判别是类别1还是类别2的问题可以转换为判别是否为类别1的问题)条件下,Softmax函数就退化为Sigmoid函数了。
3.2 softmax函数的偏导数
softmax函数的偏导数(由于有多个输入了,所以是偏导数)也同样有非常优美的形式(与sigmoid一样,这个优美的导函数形式源自于指数函数的的导数性质,以及输出结果归一化【即总和为1】特性)。
首先,为了简洁,将softmax函数记为以下形式:
(7)
的针对变量
的偏导函数(需要注意,不管是
还是
都是n个变量
的函数!)可以推导如下。这里,需要分类讨论。注意,以下为了简洁起见,用
表示
。
case1: i = j
(8)
跟上面的式(2)长得像不像!
case2: i != j
(9)
合并起来的话,可以写成如下所示:
(10)
其中,I()表示Indicator function,()内条件下成立的话取值为1,否则取值为0.
3.3 softmax函数的梯度
简而言之,梯度就是将各偏导数表示成向量(或矩阵)的形式。一般来说,把梯度视为行向量。
首先考虑y的分量的梯度(scalar to vector derivative)(注意,这里用不带下标的字母y,z表示向量,带下标的则表示其中的分量。通常会用字体加粗来着重强调表示向量,但是这里就不拘泥于这个了,有时会加粗有时不加粗,但是不带下标就表示是向量)
(11)
整个向量y的梯度(vector to vector derivative)就是将以上各分量的梯度纵向摞起来构成一个矩阵(这个在vector/matrix calculus中叫做所谓的numerator layout。与之相对的还有一种叫做denominator layout。但是前者更常见)
(12)
其中,采用了缩减表示:
3.4 softmax python实现
import numpy as np
def softmax(logits):
'''
Assuming a numpy ndarray (D,m), as input.
Before doing the division, we must reshape the sums into a one-column matrix,
otherwise, NumPy complains that it cannot divide a matrix by a one-dimensional array.
'''
tmp = np.exp(logits)
tmp = tmp / np.sum(tmp, axis = 1).reshape(-1,1)
np.testing.assert_almost_equal(np.sum(tmp, axis = 1), 1)
return tmp
# test of softmax
# logits = np.random.rand(16).reshape(4,4)
logits = np.array([[2,2,2,2]])
s = softmax(logits)
print(logits)
print(s)
Output:
[[2 2 2 2]]
[[0.25 0.25 0.25 0.25]]4. cross-entropy loss
交叉熵损失(cross-entropy loss),是一种基于对数的损失函数(log loss)。也称为负对数似然(negative log likelihood,NLL)损失,是机器学习和深度学习中用于分类问题的一种常见损失函数。它用于比较模型输出的概率分布与真实标签的概率分布之间的差异。
在二分类问题中,对应于所使用的logistic函数(即sigmoid函数),此时的交叉熵损失也称为logistic loss。换句话说,logistic loss是cross-entropy loss的在二分类情况下的特例。
4.2 logistic loss
logistic loss的表达式(单个样本)如下式所示:
(13)
其中,y是样本的实际标签(0或1),是模型预测样本属于正类的概率,是sigmoid函数输出(当然其它激励函数的输出也可以,只要它能够表示概率)。
显然,当真实标签y为1时,损失函数为,当真实标签y为0时,损失函数为
。因此,当模型的预测值越接近真实标签,损失函数的值越小,反之,当模型的预测值与真实标签越不一致,损失函数的值越大。
一般来说,深度学习中样本数据都是采用(小)批量处理的方式(mini-batch),一个批量数据的的总的损失,就是取各样本的损失的平均值,如下所示:
(14)
这里(由于上文说了用下标表示一个向量中的分量)用上标来表示样本编号。
4.3 logistic loss gradient
进行简单的单变量微分运算可得logistic loss gradient(单变量条件下就是普通的导数)如下所示:
(15)
4.4 cross-entropy loss
cross-entropy loss的表达式(单个样本)可以表达为logistic loss的直接向多分类情况的扩展(对应于把多分类问题看作是多个二分类问题的合并),如下式所示:
(16)
在上式中,求和的每一项相当于是针对每一个类别的logistic loss。其中k代表类别数。表示模型预测样本属于该类的概率。
cross-entropy loss的更简洁的表达方式为(在多分类中,后半截的信息是冗余的,已经包含在其它各类别项的前半部分中了):
(17)
同样批量处理的时的一个批量的交叉熵损失取各样本的交叉熵的均值,如下所示:
(18)
其中,N为样本数量,M为类别数,代表样本i的真实标签为类别j的概率(如果样本i的真实标签为类别j则为1,否则为0. 即一个one-hot vector),
代表模型预测样本i属于类别j的概率。
交叉熵损失的直观意义是,模型预测的概率分布与真实标签的概率分布越接近,损失就越小。因此,当模型对样本的分类预测越准确时,交叉熵损失就越小。
4.5 cross-entropy loss gradient
先看loss对其中某个分量的偏导数(简单到爆):
(19)
cross-entropy loss的梯度就是将针对各分量的偏导数拼起来凑成一个向量而已(注意,如前所述,在数学分析中,通常将梯度视为行向量):
(20)
5. Gradient of "softmax + cross-entropy" combo
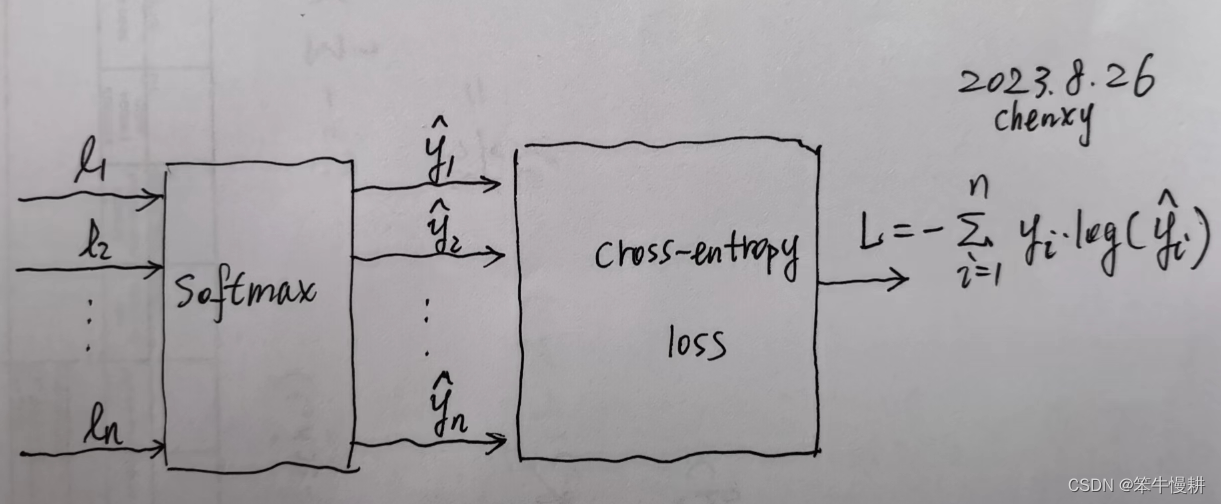
图2:combo of softmax and cross-entropy loss
在机器学习或者深度学习中,softmax和cross-entropy通常是组合起来使用的。所以,可以把两者的组合看作是一个组件/模块,即:
(21)
这里,用SML表示combo of softmax and cross-entropy loss,表示softmax的logits输入(如前所述它是一个向量),
为softmax的输出。
SML的梯度是指最终的loss针对softmax的输入logits的梯度。由于,SML由两个函数级联而成,即所谓的复合函数,求偏导数需要用到链式法则(chain rule)。而且,如下所示,由于和
都是向量,所以需要用到全微分版本的链式法则。
先看针对logits的分量i的偏导数。
step1: (22-1)
首先,L是 = {...,
,...}的函数,而各
又分别是
的函数,所以求L对
的偏导数需要考虑各
作为中间媒介的贡献。这是所谓的全微分,具体细节请参考高等数学教材。
step2: 参见4-5.
(22-2)
step3: 参见3-2.
(22-3)
step4: 把(22-1~3)串起来可以得到:

图3:SML vs logits derivative
so beautiful! 这么眼花缭乱的一大堆东西,最后竟然得出如此简洁的一个结果!
进一步,可以得到L的梯度表示(就是将各分量排排队凑成一个向量)如下所示 :
(22-4)
6. batch implementation
coming soon
进一步更完整的关于backpropagation的数学推导参考:Tutorial: Mathmatical Derivation of Backpropagation
reference:


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











