






来自:http://www.pyimagesearch.com/2014/11/17/non-maximum-suppression-object-detection-python/
康涅狄格州很冷。很冷。有时很难在早上睡觉。老实说,没有大量的南瓜香料拿铁和美丽的日出在清脆的秋叶上,我不认为我会离开我的舒适的床。
但我有工作要做。今天的工作包括写一篇关于Felzenszwalb等人的博文。非最大抑制方法。
如果你还记得,上周我们讨论了用于异常检测的定向梯度直方图。
这种方法可以分为6个步骤,包括:
- 取正面图像
- 抽样负像
- 训练线性SVM
- 进行硬负采矿
- 使用硬阴性样本重新训练线性SVM
- 在测试数据集上评估您的分类器,利用非最大抑制来忽略冗余的重叠边界框
在应用这些步骤之后,您将拥有一个像John Coltrane一样平滑的物体检测器:

图1:我的Python对象检测框架应用于面部检测。即使在低对比度图像中,也可以容易地检测到脸部。
(注:本帖中使用的图像是从MIT + CMU Frontal Face Images数据集中获取的)
这些是使用定向梯度的直方图构建对象分类器所需的最低限度的步骤。存在这种方法的扩展,包括Felzenszwalb等人的可变形部分模型和Malisiewicz等人的Exemplar SVM。
然而,无论您选择哪种HOG +线性SVM方法,您将(几乎100%的确定性)检测图像中对象周围的多个边界框。
例如,看看这个帖子顶部的奥黛丽·赫本的形象。我使用HOG和线性SVM为我的Python框架进行物体检测,并训练它来检测面部。显然,已经发现赫本斯女士面对形象 - 但检测共发现 六次!
虽然每次检测实际上都是有效的,但我确定不要让我的分类器向我报告说,当只有一张脸时 ,它会发现 六张脸。像我说的那样,这是使用对象检测方法时常见的“问题”。
其实我甚至不想把它称为“问题”!这是一个很好的问题。它表示您的检测器正常工作。如果您的检测器(1)报告了一个假阳性(即检测到一个不是一个脸)或(2)未能检测到一个脸部,那将会更糟。
为了解决这个问题,我们需要应用非最大抑制(NMS),也称为非最大抑制(Non-Maxima Suppression)。
当我第一次实现我的Python对象检测框架,我不知道一个很好的Python实现非最大抑制,所以我联系到我的朋友Tomasz Malisiewicz博士,我认为是“去”的人的话题物体检测和HOG。
作为这个主题的知识权威的Tomasz将我引用到MATLAB中的两个实现,我已经在Python中实现了。我们将回顾Felzenszwalb等人的第一个方法。那么下周,我们将回顾一下Tomasz自己实施的(更快)非最大抑制方法。
所以没有太大的拖延,让我们的手变脏。
寻找这个帖子的源代码?
跳到下载部分。
OpenCV和Python版本:
该示例将在 Python 2.7 / Python 3.4+和OpenCV 2.4.X / OpenCV 3.0+上运行。
Python中对象检测的非最大抑制
打开一个文件,命名为nms.py ,让我们开始实施Felzenszwalb等。Python中非最大抑制的方法:
# import the necessary packages
import numpy as np
# Felzenszwalb et al.
def non_max_suppression_slow(boxes, overlapThresh):
# if there are no boxes, return an empty list
if len(boxes) == 0:
return []
# initialize the list of picked indexes
pick = []
# grab the coordinates of the bounding boxes
x1 = boxes[:,0]
y1 = boxes[:,1]
x2 = boxes[:,2]
y2 = boxes[:,3]
# compute the area of the bounding boxes and sort the bounding
# boxes by the bottom-right y-coordinate of the bounding box
area = (x2 - x1 + 1) * (y2 - y1 + 1)
idxs = np.argsort(y2)我们将从第2行开始,导入一个单独的包,NumPy,我们将用于数字处理。
从那里我们 在第5行定义我们的 non_max_suppression_slow函数。此函数接受参数,第一个是以(startX,startY,endX,endY)的形式的一组边界框, 第二个是我们的重叠阈值。我稍后会在这篇文章中讨论重叠阈值。
第7行和第8行对边界框进行快速检查。如果列表中没有边框,只需将空列表返回给调用者。
从那里,我们初始化我们在第11行的挑选边界框列表(即我们想保留的边界框,丢弃其余的) 。
让我们继续解开第14-17行边界框的每个角的 (x,y)坐标 - 这是使用简单的NumPy数组切片完成的。
然后我们使用我们的切片 (x,y)坐标来计算线21上每个边界框的面积 。
一定要注意 22号线。我们应用np.argsort 获取 边界框的右下方y坐标的排序坐标的索引 。我们根据右下角进行排序是非常重要的,因为我们需要在此函数中计算其他边框的重叠率。
现在,让我们进入非最大抑制功能的肉:
# keep looping while some indexes still remain in the indexes
# list
while len(idxs) > 0:
# grab the last index in the indexes list, add the index
# value to the list of picked indexes, then initialize
# the suppression list (i.e. indexes that will be deleted)
# using the last index
last = len(idxs) - 1
i = idxs[last]
pick.append(i)
suppress = [last]我们开始循环使用第26行的索引,我们将继续循环,直到我们用尽索引为止。
从那里我们将抓住idx 列表的第31行的长度 ,获取第32行的idx 列表中 最后一个条目的值 ,将索引i附加 到我们的边界列表中以保持在第33行,最后初始化我们的 抑制 列表(我们想忽略的框的列表),其索引列表在行34上的索引 。
那是一口气 而且由于我们将索引处理到索引列表中,这并不是一件简单的事情来解释。但是,请务必暂停这里,并仔细检查这些代码,因为它很重要。
计算重叠率并确定我们可以忽略的边界框的时间:
# loop over all indexes in the indexes list
for pos in xrange(0, last):
# grab the current index
j = idxs[pos]
# find the largest (x, y) coordinates for the start of
# the bounding box and the smallest (x, y) coordinates
# for the end of the bounding box
xx1 = max(x1[i], x1[j])
yy1 = max(y1[i], y1[j])
xx2 = min(x2[i], x2[j])
yy2 = min(y2[i], y2[j])
# compute the width and height of the bounding box
w = max(0, xx2 - xx1 + 1)
h = max(0, yy2 - yy1 + 1)
# compute the ratio of overlap between the computed
# bounding box and the bounding box in the area list
overlap = float(w * h) / area[j]
# if there is sufficient overlap, suppress the
# current bounding box
if overlap > overlapThresh:
suppress.append(pos)
# delete all indexes from the index list that are in the
# suppression list
idxs = np.delete(idxs, suppress)
# return only the bounding boxes that were picked
return boxes[pick]在这里,我们开始循环第37行的idx 列表中 的(剩余)索引 ,获取39行当前索引的值 。
使用最后一次在入门 IDX 从名单 32号线和 目前在入门 IDX 从列表中第39行,我们发现最大的 (X,Y)坐标开始边框和 最小 (X,Y)为结束坐标第44-47行的边界框 。
这样做可以让我们在较大的边界框内找到当前最小的区域(因此,为什么我们最初按照 右下方的y坐标对idx列表进行排序是如此重要 )。从那里,我们计算第50和51行的区域的宽度和高度 。
所以现在我们正处于重叠阈值的起点。上 55行 我们计算 重叠 ,这是通过将当前的边界框,其中“当前”是由索引定义的面积除以当前最小区域的面积所限定的比率 Ĵ 上 39行。
如果 重叠 率大于第59行的阈值 ,则我们知道两个边界框充分重叠,因此可以抑制当前边界框。重叠的常用值 通常在0.3和0.5之间。
行64然后从idx 列表中删除抑制的边界框 ,我们继续循环,直到 idx 列表为空。
最后,我们在第67行返回一组选中的边界框(未被抑制的) 。
让我们继续创建一个驱动,所以我们可以执行这个代码,看看它的行动。打开一个新文件,命名为nms_slow.py,并添加以下代码:
# import the necessary packages
from pyimagesearch.nms import non_max_suppression_slow
import numpy as np
import cv2
# construct a list containing the images that will be examined
# along with their respective bounding boxes
images = [
("images/audrey.jpg", np.array([
(12, 84, 140, 212),
(24, 84, 152, 212),
(36, 84, 164, 212),
(12, 96, 140, 224),
(24, 96, 152, 224),
(24, 108, 152, 236)])),
("images/bksomels.jpg", np.array([
(114, 60, 178, 124),
(120, 60, 184, 124),
(114, 66, 178, 130)])),
("images/gpripe.jpg", np.array([
(12, 30, 76, 94),
(12, 36, 76, 100),
(72, 36, 200, 164),
(84, 48, 212, 176)]))]
# loop over the images
for (imagePath, boundingBoxes) in images:
# load the image and clone it
print "[x] %d initial bounding boxes" % (len(boundingBoxes))
image = cv2.imread(imagePath)
orig = image.copy()
# loop over the bounding boxes for each image and draw them
for (startX, startY, endX, endY) in boundingBoxes:
cv2.rectangle(orig, (startX, startY), (endX, endY), (0, 0, 255), 2)
# perform non-maximum suppression on the bounding boxes
pick = non_max_suppression_slow(boundingBoxes, 0.3)
print "[x] after applying non-maximum, %d bounding boxes" % (len(pick))
# loop over the picked bounding boxes and draw them
for (startX, startY, endX, endY) in pick:
cv2.rectangle(image, (startX, startY), (endX, endY), (0, 255, 0), 2)
# display the images
cv2.imshow("Original", orig)
cv2.imshow("After NMS", image)
cv2.waitKey(0)我们首先 在第2行导入我们的 non_max_suppression_slow函数。 为了组织起见,我将这个函数放在 pyimagesearch包中,但是你可以把函数放在任何你认为合适的地方。从那里,我们导入NumPy进行数字处理, cv2 为我们的OpenCV绑定在 3-4行。
然后,我们定义的列表, 图片 上的8号线。该列表由2元组组成,其中元组中的第一个条目是图像的路径,第二个条目是边界列表。这些边界框是从我的HOG +线性SVM分类器获得的,在不同的位置和尺度上检测潜在的“面”。我们的目标是为每个图像采取一组边界框,并应用非最大抑制。
我们首先循环遍历第27行 的图像路径和边界框, 并在30行加载图像 。
为了可视化行动中非最大抑制的结果,我们首先在第34和35行绘制原始(非抑制)边界框 。
然后,我们对第38行应用非最大抑制, 并在42-43行绘制选中的边界框 。
生成的图像最终显示在 第46-48行。
非最大抑制算法运行
看到Felzenszwalb等 非最大抑制方法,从本页底部下载源代码和附带的图像,浏览到源代码目录,并发出以下命令:
$ python nms_slow.py首先,你会看到奥黛丽·赫本的形象:
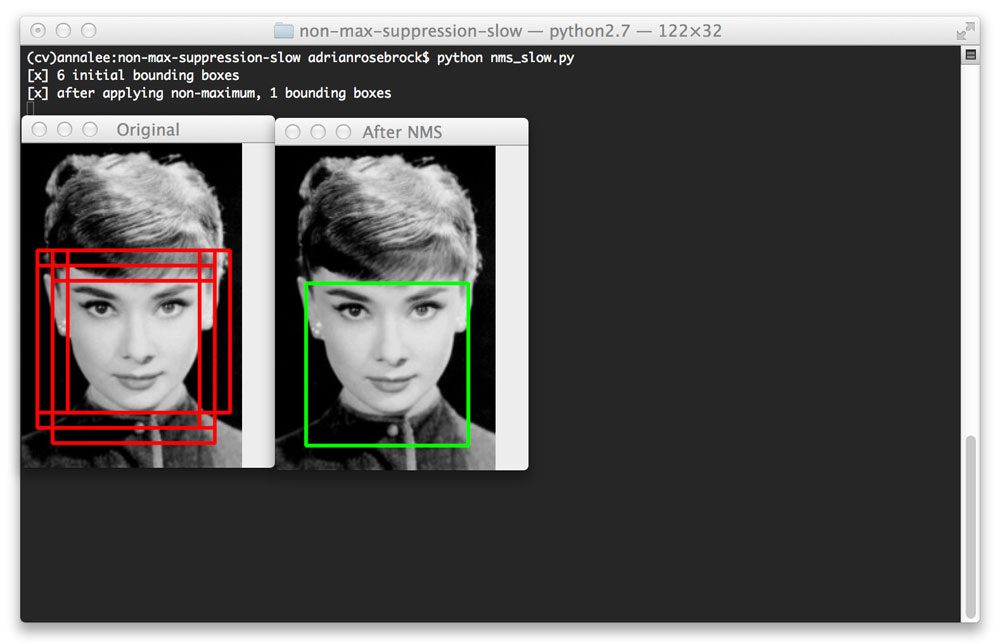
图2:我们的分类器最初检测到六个边界框,但是通过应用非最大抑制,我们只剩下一个(正确的)边界框。
注意如何 检测到六个边界框,但是通过应用非最大抑制,我们可以将这个数字修剪到一个。
第二个图像也是如此:
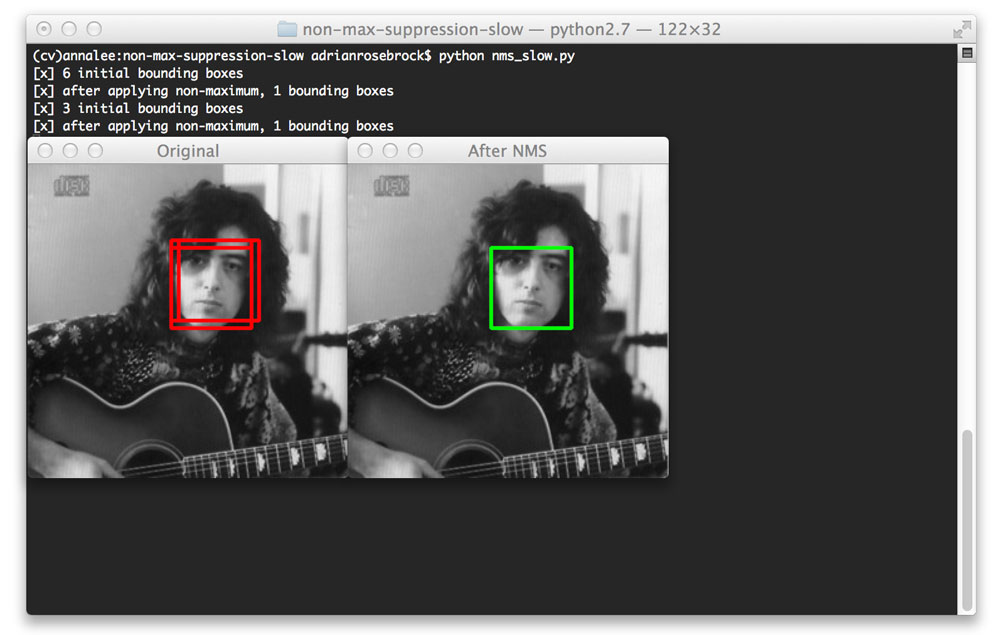
图3:最初检测三个边界框,但通过应用非最大抑制,我们可以将重叠边界框的数量修剪为1。
在这里我们找到了三个对应于相同脸部的边框,但是非最大抑制即将减少到 一个边界框。
到目前为止,我们只检查包含一张脸的图像。但是,包含多个面的图像怎么样?让我们来看看:
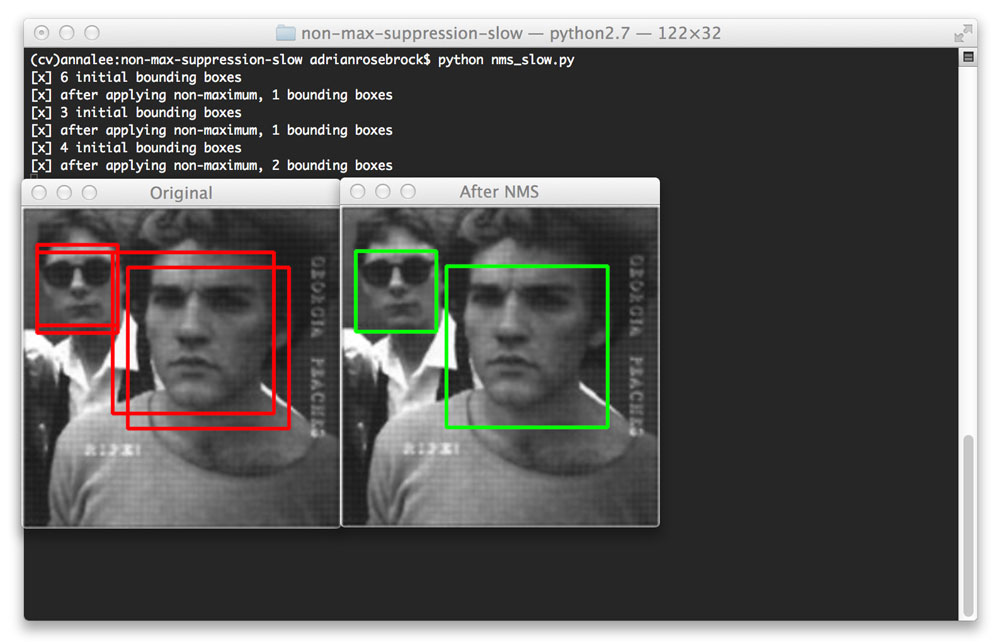
图4:当有多个面时,非最大抑制正确处理,抑制较小的重叠边界框,但保留不重叠的框。
即使对于包含多个对象的图像,非最大抑制也能够忽略较小的重叠边界框,并且仅返回较大的边界。非最大抑制在这里返回 两个边界框,因为每个面的边界框完全相同。即使他们没有重叠,做重叠率不超过0.3所提供的阈值。
概要
在这篇博文中,我向您展示了如何应用Felzenszwalb等人 非最大抑制方法。
当使用定向梯度直方图描述符和线性支持向量机进行对象分类时,您几乎 总是检测要检测的对象周围的多个边界框。
而不是返回 所有找到的边框,您应该首先应用非最大抑制来忽略彼此重叠的边界框。
然而,对Felzenszwalb等人进行了改进。非最大抑制方法。
在我的下一篇文章中,我将实现我的朋友Tomasz Malisiewicz博士建议的方法,据报道它超过了100倍!
请务必使用下面的表格将代码下载到这篇文章!当我们在下周考察Tomasz的非最大抑制算法时,一定会有方便!















 1999
1999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









