









使用 mmdetection 框架训练 faster_rcnn(swin transformer骨干网)模型时候,把 train pipeline 中的 Resize 参数从 (1333,800) 调整到 (2666, 1600)后,训练过程中发生异常 “RuntimeError: Index put requires the source and destination dtypes match, got Half for the destination and Float for the source.”。
错误堆栈
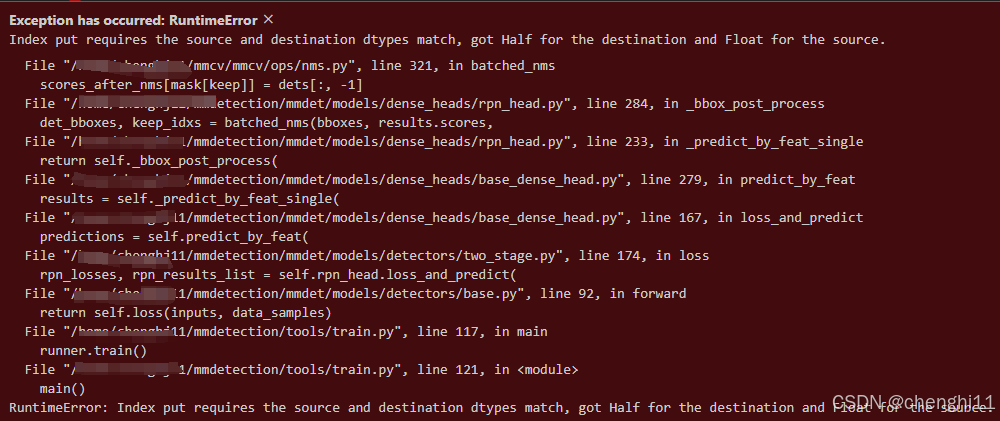
Exception has occurred: RuntimeError
Index put requires the source and destination dtypes match, got Half for the destination and Float for the source.
File "*/mmcv/mmcv/ops/nms.py", line 321, in batched_nms
scores_after_nms[mask[keep]] = dets[:, -1]
File "*/mmdetection/mmdet/models/dense_heads/rpn_head.py", line 284, in _bbox_post_process
det_bboxes, keep_idxs = batched_nms(bboxes, results.scores,
File "*/mmdetection/mmdet/models/dense_heads/rpn_head.py", line 233, in _predict_by_feat_single
return self._bbox_post_process(
File "*/mmdetection/mmdet/models/dense_heads/base_dense_head.py", line 279, in predict_by_feat
results = self._predict_by_feat_single(
File "*/mmdetection/mmdet/models/dense_heads/base_dense_head.py", line 167, in loss_and_predict
predictions = self.predict_by_feat(
File "*/mmdetection/mmdet/models/detectors/two_stage.py", line 174, in loss
rpn_losses, rpn_results_list = self.rpn_head.loss_and_predict(
File "*/mmdetection/mmdet/models/detectors/base.py", line 92, in forward
return self.loss(inputs, data_samples)
File "*/mmdetection/tools/train.py", line 117, in main
runner.train()
File "*/mmdetection/tools/train.py", line 121, in <module>
main()
RuntimeError: Index put requires the source and destination dtypes match, got Half for the destination and Float for the source.
过程分析
经过调试确认是由 mmcv 框架中 nms 计算的一个逻辑导致:
- 在对 RPN 网络输出的 boxes 进行 NMS 计算时会判断当前总的 boxes 数量是否超配置的阈值(默认 10000),如果超过的话会按照分类id进行分批 NMS 计算。
- 对每个批次保留的 scores(dtype:fp32)即 dets[:, -1] 保存到 scores_after_nms(dtype:fp32)中,由于 dtype 不一致 tensor 的赋值操作导致异常抛出;
- 源码文件:mmcv/ops/nms.py,示例代码如下:
max_num = nms_cfg_.pop('max_num', -1)
total_mask = scores.new_zeros(scores.size(), dtype=torch.bool)
# Some type of nms would reweight the score, such as SoftNMS
scores_after_nms = scores.new_zeros(scores.size())
for id in torch.unique(idxs):
mask = (idxs == id).nonzero(as_tuple=False).view(-1)
dets, keep = nms_op(boxes_for_nms[mask], scores[mask], **nms_cfg_)
total_mask[mask[keep]] = True
scores_after_nms[mask[keep]] = dets[:, -1] # 异常位置
keep = total_mask.nonzero(as_tuple=False).view(-1)
解决方法
任意选一种就行:
- 不开启混合进度训练:修改训练配置文件的 optim_wrapper.type,由 AmpOptimWrapper 改为 OptimWrapper。缺点:会增加显存占用且极大影响训练时间;
- 模型输入调小,下采样之后的特征图变小生成的建议框也会减少:train pipeline Resize 设置为 (1333,600)。缺点:对小目标检测不友好;
- 重新定义批次 nms 计算阈值:修改训练配置的model.train_cfg.rpn_proposal.nms.split_thr,一般要大于 10000。缺点:增加计算量;
- 自己动手改一下 mmcv/ops/nms.py 对 dtype 进行转换。缺点:无;

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









