






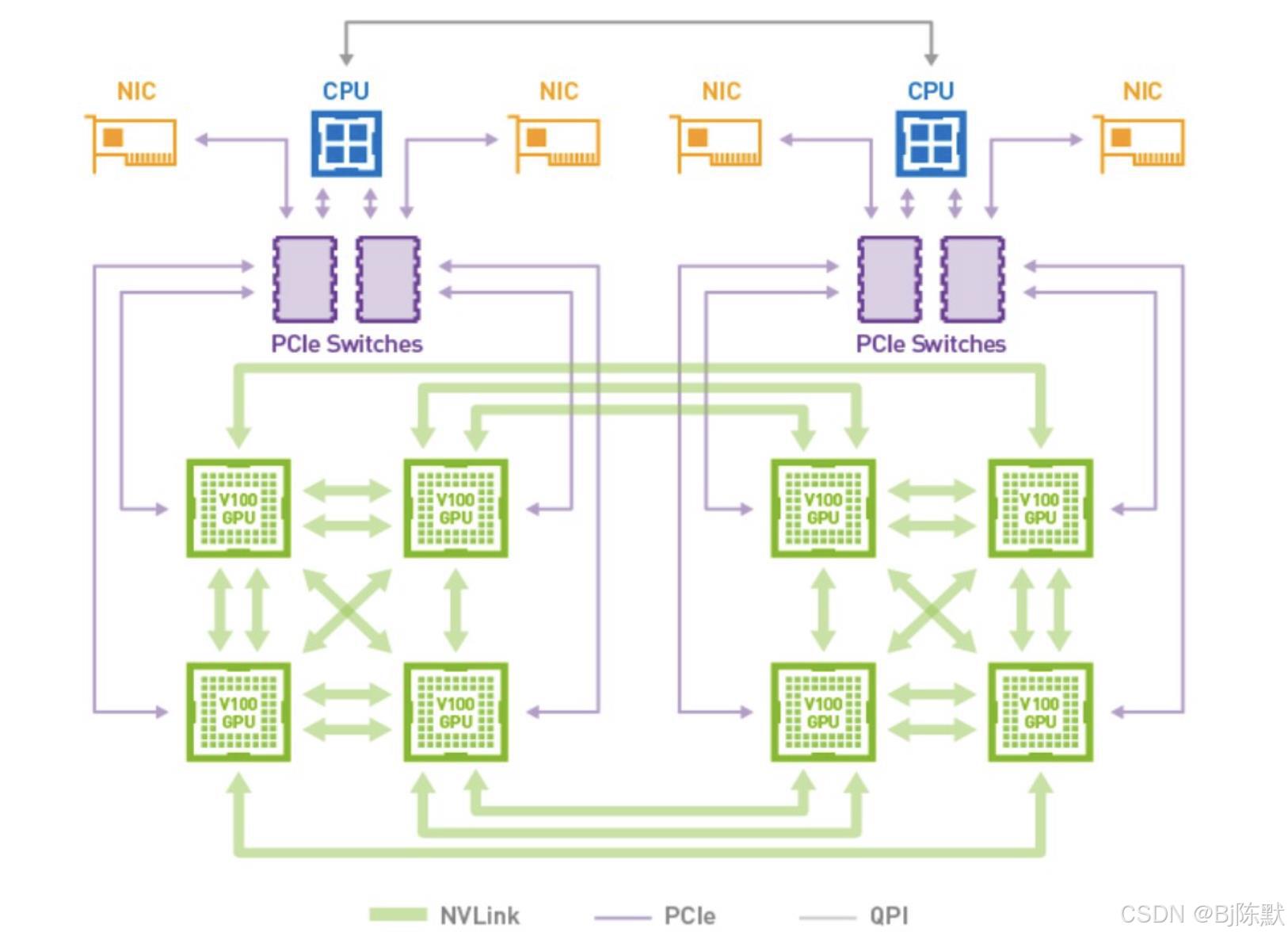
NVLink是英伟达开发的一种高速、低延迟的GPU间互连技术。其原理主要涉及以下几个方面:
1. 高速串行点对点连接:
连接方式:NVLink采用点对点的连接结构,这意味着每个GPU可以直接与其他GPU或设备进行通信,无需通过中央集线器或其他中间设备。这种直接连接方式有效减少了通信中的瓶颈,提高了数据传输的效率和速度。例如,在多GPU并行计算的场景中,各个GPU之间可以快速地交换数据,协同完成计算任务。
高速串行传输:NVLink使用高速串行接口技术进行数据传输。串行传输方式可以在较少的物理线路上实现高带宽的数据传输,并且具有更好的抗干扰性和可扩展性。通过不断提高串行传输的速率,NVLink能够实现极高的数据传输速度。例如,NVLink 4.0的带宽高达900GB/s。
2. 多链路聚合:
链路数量和带宽叠加:为了进一步提高数据传输速度,NVLink支持多链路聚合技术。一个GPU可以通过多个NVLink链路与其他GPU或设备连接,这些链路可以同时工作,将数据传输带宽进行叠加。例如,NVIDIA H100 GPU中包含18条NVLink 4.0链路,使得GPU之间能够实现大规模的数据并行传输。
数据分流与合并:在数据传输过程中,系统可以根据数据的类型、大小和传输需求,将数据分流到不同的链路上进行传输,然后在接收端再将数据合并。这样可以充分利用多链路的带宽资源,提高数据传输的效率和灵活性。
3. 网状拓扑结构:
灵活的连接方式:NVLink支持网状拓扑结构,这意味着多个GPU之间可以形成一个复杂的连接网络。与传统的菊花链或中心辐射型拓扑相比,网状拓扑允许GPU之间实现更通用且数量更多的连接。这种连接方式使得数据可以在多个GPU之间以更灵活的路径进行传输,提高了系统的可靠性和容错性。
高效的数据路由:在网状拓扑结构中,NVLink内置了路由引擎,能够根据系统的负载情况和数据传输需求,自动选择最优的数据传输路径。这样可以避免数据拥堵,提高数据传输的效率和速度。例如,在大规模的并行计算任务中,系统可以根据各个GPU的负载情况,动态地分配数据传输任务,确保每个GPU都能够充分发挥其性能。
4. 统一内存访问:
内存共享:NVLink支持统一内存的概念,允许连接的GPU之间共享公共内存池。这意味着一个GPU可以直接访问其他GPU的内存空间,无需在GPU之间复制数据,从而减少了数据传输的开销和延迟。
简化编程模型:统一内存访问为开发者提供了一个简单、统一的编程模型,开发者可以像访问本地内存一样访问其他GPU的内存,无需关心数据的具体传输过程和位置。这大大降低了多GPU编程的难度,提高了开发效率。


















 1152
1152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











