








概述
原文:《An efficient and robust line segment matching approach based on LBD descriptor and pairwise geometric consistency》
上一步我们进行了线特征的提取和描述,接下来我们进行线特征的匹配。在此之前我们先通过预处理将一些明显无法匹配的特征给消除,以降低图匹配问题的维度。
该部分图匹配算法分为三步:
- 查找候选匹配对
- 构建关系图
- 生成最终匹配结果
1. 查找候选匹配对
匹配的双方,我们分别称为参考图像和查询图像,检测出双方的LineVecs之后,我们要检测他们的一元几何属性和局部外观相似度,若未通过测试,那么认为他们是不匹配的。这样做可以大大减小图优化匹配的问题维度,使得我们后期匹配的速度更快。
1.1.一元几何属性
线段的一元几何属性就是LineVecs的方向,在同一个LineVec中的线具有相同的方向,并且每一个LineVec拥有唯一的方向。但是两张图中的LineVecs的方向有可能是不可靠的,图像有可能会有任意角度的旋转,对于这点,我们利用图像对之间存在的近似全局旋转角,可以减少候选匹配对的数目。
构建旋转
和其他文章中使用对应匹配来进行图像旋转不同,LBD的Matching中通过计算两个图像的LineVecs方向直方图,得到规范化直方图



而全局旋转变换不一定总是好的,所以我们也需要去检查估计旋转角是不是真的。实际上如果透视变换可以通过旋转来近似,那么直方图之差

上图就显示出了两张图之间的直方图差距,通过旋转我们可以得出两张图之间相似度很高。上图中的预估角度
但是如果图像中提取的线重复度很低的话,这种直方图方法就有可能提取出错误的旋转角度。为了解决这个问题,对于在方向直方图上落入相同区间bins的线段,将他们的长度累积起来。那么我们就可以得到一个长度向量,其第i个元素就是方向直方图中第i个bin中的线段累计长度。
我们设定最小偏移直方图小于阈值th,并且最小偏移长度向量距离小于阈值tl时,我们接受我们所估计的全局旋转角。一旦全局旋转角被接受,就会有一对LineVecs被匹配。但是如果这对LineVecs的方向角度和估计的全局旋转角之差超过阈值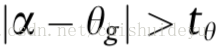
1.2. 局部外观相似性
我们用直线描述符之间的距离(lost)来度量局部外观相似度。
对于LineVec中的每个线段,我们都从提取出线的尺度层中生成一个LBD描述子向量V。当我们对一幅图像中提取出来的两组LineVec进行匹配,要去评估参考LineVec和测试LineVec中所有描述子之间的距离,并且用最小的描述子距离去测量LineVec外观相似度s。如果 s > ts s大于局部外观不相似容忍度,那么相应两个LineVecs将不会再进一步考虑。
在检查了LineVecs的一元几何属性和局部外观相似性之后,通过了这些测试的直线对被当做候选匹配。我们在上面的测试中,应当选取一组松散阈值,其中经验值是 tθ=π/4 ts=0.35。候选匹配的数量比实际匹配的数量要大很多,因为我们不能仅仅按照刚才两个属性来确定最终的匹配结果,当然我们上面的工作也是大大减小了图形匹配的问题维度的。
2. 构建关系图
对于上面得到一组候选匹配项,我们要构建一个关系图
其中关系图里的节点代表潜在的对应点
节点之间的连接的权重代表对应点之间的一致性。
拿到了k对对应关系,我们用一个大小为k*k的邻接矩阵A来表示关系图,其中第i行第j列的元素值是候选LineVec匹配对
成对几何属性

我们选择两条线分别是
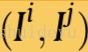



Ij和Pj的值可以用相同的方法求解得到,
外观相似度
之前,我们使用LBD描述向量来表示线的局部外观。
假设描述子与r图(参考图)和q图(查询图)的LineVecs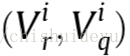

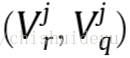

计算一致性得分Aij:

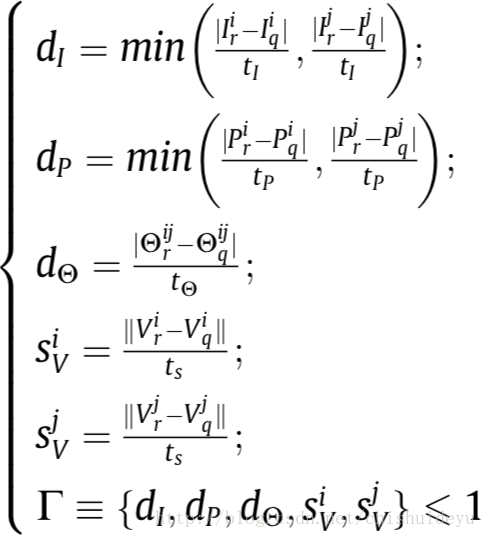
其中是
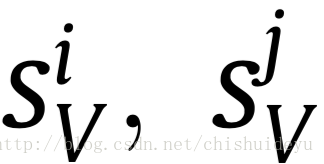

接下来我们设
3. 生成最终匹配结果
到这一步之后,匹配的问题最终就变成了,寻找匹配簇LM,该匹配簇可以最大化总的一致性分数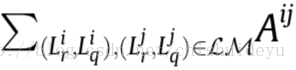


其中x受制于映射约束。一般来说用二次规划来解决这个问题太耗费资源,我们采用谱图技术,对x放款映射约束和积分约束,使得他的元素可以采集实际值在[0,1]区间里。
通过Raleigh比率定理,可以最大化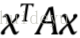
以下是算法细节:
- 通过EDLine算法从参考图和查询图内提取LineVecs,以从两幅图中分别获得两组LineVecs
- 利用两组LineVecs的方向直方图估计图像对的全局旋转角
- 计算两组LineVecs的LBD描述子
- 通过检查描述子的一元几何属性和局部外观,生成一组候选匹配对
- 根据候选匹配对中一致性分数,构建k*k大小的邻接矩阵
- 通过使用ARPACK库,得到邻接矩阵A的主特征向量x*
- 初始化匹配结果
- 查找
,如果x*(a)=0,那么停止查找返回匹配结果LM,否则设
,
且x*(a)=0。
- 检查CM中所有的候选者,如果
冲突,那么设
- 如果CM是空的,那么返回LM,否则返回到步骤8。

最后一行的线段匹配可以从LineVecs LM的匹配结果直接检索。注意,在LineVec的线位于图像的同一区域,并且具有同一方向,因此,每对linevec的匹配,线段匹配有一对就足够检索了。















 1248
1248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









