







 本文介绍了如何利用OpenAI的gym库中的Cart Pole游戏进行强化学习实验。游戏目标是通过神经网络训练使小车保持杆子竖直,达到200个连续动作而不倒。文章探讨了强化学习的概念,并预告了后续将分享的常见强化学习模型。通过安装gym并运行示例代码,读者可以开始自己的强化学习之旅。
本文介绍了如何利用OpenAI的gym库中的Cart Pole游戏进行强化学习实验。游戏目标是通过神经网络训练使小车保持杆子竖直,达到200个连续动作而不倒。文章探讨了强化学习的概念,并预告了后续将分享的常见强化学习模型。通过安装gym并运行示例代码,读者可以开始自己的强化学习之旅。
openAi开源了一个叫gym的游戏库,这个库里有好多小游戏可以用来做强化学习试验,比如Cart Pole平衡车小游戏。
gym的Cart Pole环境
Cart Pole在OpenAI的gym模拟器里面,是相对比较简单的一个游戏。游戏里面有一个小车,上有竖着一根杆子。小车需要左右移动来保持杆子竖直。如果杆子倾斜的角度大于15°,那么游戏结束。小车也不能移动出一个范围(中间到两边各2.4个单位长度)。如下图所示:
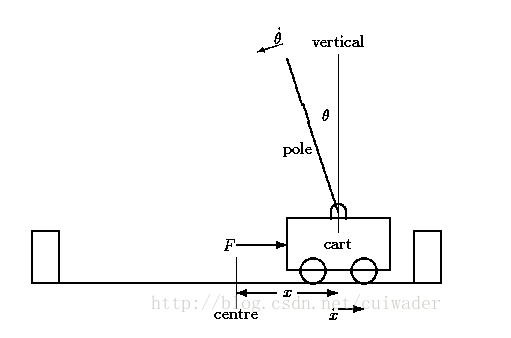
在gym的Cart Pole环境(env)里面,左移或者右移小车的action之后,env都会返回一个+1的reward。到达200个reward之后,游戏也会结束。
强化学习的目的就是训练神经网络来自动玩这个游戏,使得最终结果是连续移动200个action而平衡车不倒,一直到游戏正常结束。
那么问题来了,神经网络是通过什么机制来学会自动玩这个游戏呢?这就是深度学习里一个鼎鼎大名的领域叫“强化学习”。著名的围棋智能机器人阿法狗就是强化学习的一个典型应用。
那么强化学习是怎么实现的呢?它的工作原理是什么?
笔者不打算太多介绍理论方面的知识,更多的从实践出发,教给大家怎么编写自己的强化学习模型。强化学习模型大概有DQN,策略网络,DDPG等几种常见的神经网络结构,具体的模型实践会在后续章
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 633
633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









