






gym入门
gym简介
gym是一个用于开发和比较强化学习算法的工具箱。它对代理(agent)的结构没有任何假设,并且与任何数值计算库(如TensorFlow或Theano)兼容。
gym库是一个测试问题的集合,即环境。你可以用它来制定你的强化学习算法。这些环境有一个共享的接口,允许您编写通用的算法。
gym安装
在cmd中输入:
pip install gym
环境
下面是一个让某些东西运行的最小示例。这将是1000个时间间隔运行一个 CartPole-v0 环境的实例,并在每个步骤中呈现环境。你应该会看到一个窗口弹出呈现经典的车杆问题:
import gym
env = gym.make('CartPole-v0')
env.reset()
for _ in range(1000):
env.render()
env.step(env.action_space.sample()) # take a random action
env.close()
结果如图:

通常情况下,我们会在杆子离开界面前就停止仿真。这里我们先忽略关于调用step()的警告,即使这个环境已经返回done = True。
如果你想看看其他环境的运行情况,试着用一些类似于MountainCar-v0, MsPacman-v0(需要Atari依赖)或Hopper-v1(需要MuJoCo依赖)的东西替换上面的CartPole-v0。 环境都是从Env基类派生出来的。
例如MountainCar-v0仿真如下图:

import gym
env = gym.make('MountainCar-v0')
env.reset()
for _ in range(1000):
env.render()
env.step(env.action_space.sample()) # take a random action
env.close()
观察值(Observations)
如果我们想要做得更好,而不是在每一步都采取随机行动,那么最好是真正了解我们的行动对环境的影响。环境的step函数返回的正是我们所需要的。实际上,step返回四个值。这些都是:
1、观察observation(对象):一个特定于环境的对象,代表你对环境的观察。例如,摄像机的像素数据,机器人的关节角度和关节速度,或棋盘游戏中的棋盘状态。
2、奖励reward(浮点数):通过之前的行动获得的奖励数量。在不同的环境中,奖励的规模是不同的,但目标总是增加你的总奖励。
3、完成done (布尔型):是否该再次重置环境。大多数(但不是所有)任务都被划分为定义良好的章节,“done”为True表示章节已经结束。(例如,可能是杆子倾斜得太远,或者你失去了上一条生命。)
4、信息info (dict型):调试有用的诊断信息。它有时对学习很有用(例如,它可能包含环境最后状态更改后的原始概率)。但是,你的代理人(agent)的官方评估是不允许用于学习的。
这只是经典的“代理-环境循环”的实现。每个时间步,代理选择一个行动,环境返回一个观察结果和一个奖励。
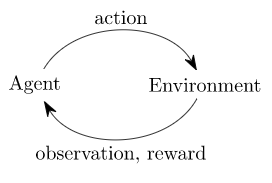
这个过程通过调用reset()启动,它返回一个初始观察结果。所以写前面代码的更合适的方式是重视done标记:
CartPole

空间(Spaces)
在上面的例子中,我们从环境的行动空间中抽取随机行动。但这些行动到底是什么呢?每个环境都有一个action_space和一个observation_space。这些属性属于Space类型,它们描述了有效操作和观察的格式:
import gym
env = gym.make('CartPole-v0')
print(env.action_space)
#> Discrete(2)
print(env.observation_space)
#> Box(4,)

Discrete空间允许一个固定范围的非负数,所以在这种情况下,有效的动作是0或1。
Box空间表示一个n维的方框,因此有效的观察结果将是一个4个数字的数组。我们还可以检查Box方框的边界:
print(env.observation_space.high)
#> array([ 2.4 , inf, 0.20943951, inf])
print(env.observation_space.low)
#> array([-2.4 , -inf, -0.20943951, -inf])

这种自省(introspection)有助于编写适用于许多不同环境的泛型代码。Box和Discrete是最常见的空间(Spaces)。你可以从空格中取样或检查某物是否属于它:
对于carpole -v0,其中一个动作向左侧施力,另一个向右侧施力。你的学习算法越好,你自己解释这些数字的难度就越小。
可用的环境
gym提供了一套不同的环境,从容易到困难,涉及许多不同类型的数据。如下是完整的环境列表的鸟瞰视图:

1、经典控制和玩具文本:完成小规模任务,主要来自RL文献。他们是来帮你开始的。
2、Algorithmic:执行多位数相加、序列反转等运算。有人可能会反对说,这些任务对计算机来说太容易了。挑战在于纯粹从例子中学习这些算法。这些任务具有一个很好的属性,即可以通过改变序列长度来改变难度。
3、雅达利(Atari):玩经典雅达利游戏。我们已经整合了街机学习环境(这对强化学习研究有很大的影响)在一个易于安装的形式。
4、2D和3D机器人:在模拟中控制机器人。这些任务使用MuJoCo物理引擎,这是为快速和准确的机器人模拟而设计的。
背景:为什么使用Gym?(2016)
强化学习(RL)是机器学习的一个分支领域,主要研究决策和电机控制。它研究智能体(agent)如何学习如何在复杂、不确定的环境中实现目标。它令人兴奋有两个原因:
1、RL非常笼统,包含了所有涉及做出一系列决策的问题:例如,控制机器人的马达,使其能够跑和跳,做商业决策,如定价和库存管理,或玩电子游戏和桌面游戏。RL甚至可以应用于具有顺序或结构化输出的监督学习问题。
2、RL算法已经开始在许多困难的环境中取得良好的结果。RL有很长的历史,但直到最近深度学习的进步,它需要大量针对具体问题的工程。DeepMind的Atari结果、Pieter Abbeel团队的BRETT和AlphaGo都使用了深度RL算法,这种算法没有对环境做太多假设,因此可以应用于其他设置。
然而,RL研究也因两个因素而放缓:
1、需要更好的基准。在监督学习中,像ImageNet这样的大型标注数据集推动了学习的进展。在RL中,最接近的对等物是大量且多样的环境集合。然而,现有的RL环境的开源集合没有足够的多样性,而且它们甚至很难设置和使用。
2、出版物中使用的环境缺乏标准化。问题定义上的细微差别,如奖励功能或行动集合,可以极大地改变任务的难度。这一问题使得复制已发表的研究和比较不同论文的结果变得困难。
Gym尝试解决这两个问题。
参考资料
https://gym.openai.com/docs/#background-why-gym-2016















 1494
1494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









