







目录
1.算法仿真效果
matlab2022a仿真结果如下(完整代码运行后无水印):
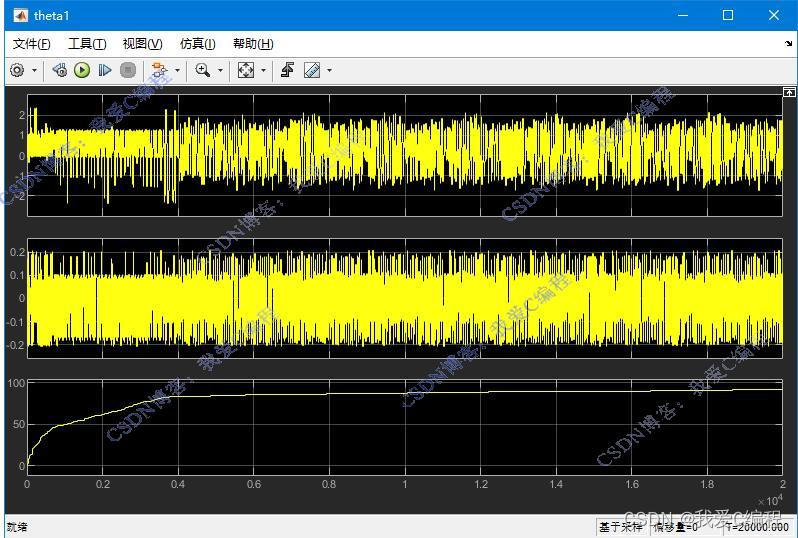
2.算法涉及理论知识概要
基于强化学习的倒立摆平衡车控制系统是一个典型的动态系统控制问题,它通过不断的学习和决策过程,使倒立摆维持在垂直平衡位置,即使受到外力干扰或系统内部噪声影响。强化学习在此类问题中的应用,展示了其在解决复杂控制问题中的强大潜力。
2.1强化学习基础
强化学习(Reinforcement Learning, RL)是一种通过与环境交互学习策略的机器学习方法,目的是最大化长期奖励。其核心要素包括状态(State, s)、动作(Action, a)、奖励(Reward, r)、策略(Policy, π)和环境(Environment)。在倒立摆平衡控制问题中:
- 状态 s:描述系统当前的配置,通常包括倒立摆的角度θ、角速度θ˙、小车的位置x和速度x˙。
- 动作 a:控制小车向左或向右施加的力,如-10N至10N的力。
- 奖励 r:每一步给予智能体的反馈,例如,当倒立摆保持平衡时给予正奖励(如+1),当倒立摆倒下或偏离预定范围时给予负奖励或终止。
- 策略 π:基于当前状态选择动作的策略,目标是找到最优策略π∗最大化期望累积奖励。
2.2 倒立摆模型
倒立摆系统可由以下二阶线性微分方程组描述其动力学特性:
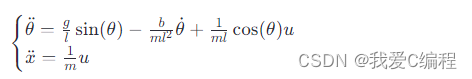
其中,g是重力加速度,l是摆长,m是摆的质量,b是摩擦系数,u是小车对系统施加的控制力。
2.3 Q-Learning算法应用于倒立摆控制
Q-Learning是一种无模型的强化学习算法,通过学习一个动作价值函数Q(s,a)来决定在给定状态下采取什么行动。该函数表示在状态s采取动作a后,预期能获得的累积奖励。Q-Learning的更新规则如下:
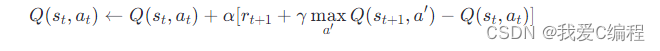
这里,α是学习率,γ是折扣因子,rt+1是采取动作at后立即获得的奖励,st+1是下一个状态。
由于倒立摆控制问题的维度较高,经典的Q-table可能不切实际,因此常采用DQN来解决。DQN使用深度神经网络近似Q函数,可以处理高维状态空间。其关键创新在于引入了经验回放(Experience Replay)和固定Q-targets,以减少关联性和提高学习稳定性。
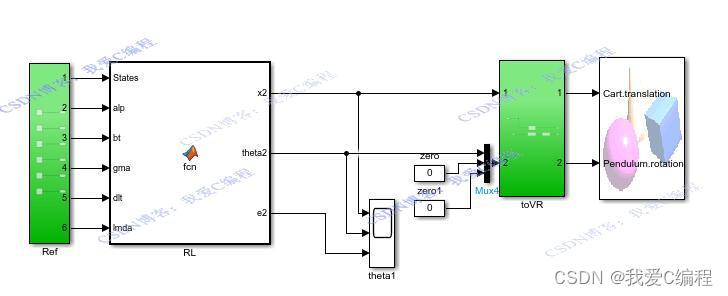
3.MATLAB核心程序
0Z_006m
4.完整算法代码文件获得
V


















 971
971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











