






原文地址:https://arxiv.org/abs/1905.01164
github地址:https://github.com/tamarott/SinGAN
1.1 研究背景
已有方法在具有多个类别、高度多样性的数据集上表现不够好,通常需要输入另一个信号来调整或者在一个特定任务上,通过相同的生成网络完成。
- SinGAN是无条件式的生成模型,在保留了原始的图像块分布的基础上,创造出新的物体外形和结构;
- 全卷积生成式模型,可以生成任意大小和纵横比的新样本;
- 从单个图像出发,绘制、编辑、协调、超分辨率和动画处理。
1.2 方法
SinGAN多尺度模型,即GAN金字塔结构,如图所示:

每层包含一个生成器和一个判别器模型,生成器输入为上一层生成器的输出图像和当前层的噪声图像(除了金字塔最底下的那一层,其输入为纯噪声),用以增加生成器对噪声的适应,输出为残差图像(五层卷积后的输出图像)和上一层生成器的输出图像,公式如下:

![]()
每一层判别器的网络结构和生成器中生成残差图像的网络结构
相同
损失函数分为对抗损失和重建损失
,前者使用WGAN-GP损失,用于提高训练的稳定性,后者用于确保加入噪声之后可以重建原始图像,当
时,公式如下:

当时,公式如下:
![]()
1.3 实验
数据集:BSD(Berkeley Segmentation Database), Places, the Web,最小图像尺寸为25px,最大图像尺寸为250px,比例因子r尽可能接近4/3
实验结果:
(1)在生成高质量图片的同时,保留原始图像的全局结构和纹理特征

(2)SinGAN的架构是与分辨率无关,因此可以用于高分辨率的图像

(3)测试时尺度对于生成图像的影响,从最粗糙的尺度上()开始生成,全局结构有可能会发生较大变化,可能导致生成不真实的样本。但从较为精细的尺度上开始生成,全局结构保持不变,仅纹理特征发生变化

(4)训练时尺度对于生成图像的影响,尺度较少时,其有效的接受域更小,只能捕获精细的纹理特征。但随着尺度数量的增加,能得到更好的全局结构

评价指标:
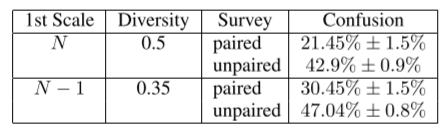
(1)AMT,依靠人为判断,paired组实验为成组的真实图像和生成图像之间的判断,unpaired组实验为随机抽取的真实图像或生成图像,结果如下,unpaired组比paired组更令人混淆,N-1层的生成图像比N层的生成图像更令人混淆,混淆率会随着多样性下降而增加
(2)SIFID,单一图像的FID指标,表示真实图像和生成图像的分布之间的偏差,本文采用的SIFID测量的是在第二个池化层之前使用卷积层输出的深层特征的内部分布,结果如下,混淆率会随着SIFID的减小而增大

1.4 应用
(1)绘制

(2)编辑

(3)协调

(4)超分辨率

(5)动画处理
1.5 结论
介绍了SinGAN这个无条件式的生成模型,学习单一自然图像,生成高质量、多样化图片的同时,保留全局结构和纹理特征。但其仍有一定的局限性,语义多样性欠缺,例如,如果训练图像包含一条狗,SinGAN并不会生成包含其他犬类的图片。















 2340
2340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









