








写这个系列文章的目的在于解读SinGAN网络的同时,介绍MindSpore深度学习框架的特点及其使用技巧。本系列文章将分为四篇文章介绍,包含论文解读、源码解读、动手复现。希望能在大家今后的工作学习当中更好的理解SinGAN网络。
SinGAN网络之论文解读
简介
设计了一个基于单张图片的非条件图像生成模型,并应用在图像随机生成,图像融合、手绘画转自然图像、图像编辑以及图像超分重建等领域。
文献下载:https://arxiv.org/pdf/1905.01164.pdf
网络特点
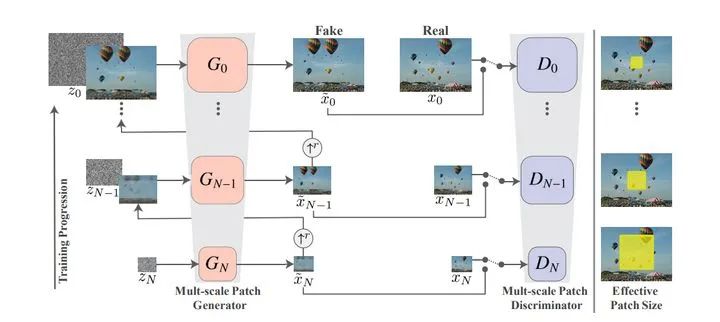
SinGAN的网络结构
SinGAN的网络结构如上图所示,由金字塔形状的多个GAN网络组成,从下到上,输出图片的尺寸由小到大,由粗糙到精细。第一个生成器输入一个随机噪音,生成非常粗糙的图片,之后采用迭代的思想不断让生成器学习更多的局部细节。下面解释迭代过程。
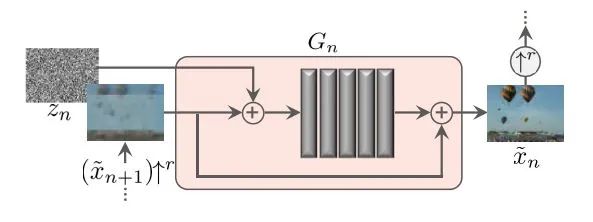
SinGAN的单个生成器结构
生成器和判别器采用同一网络结构,如上图所示的5层卷积层。前一个生成器的输出图像经过尺寸放大后叠加等大的随机噪音作为5层卷积层的输入图像,5层卷积层的输出图像叠加前一个生成器的放大输出图像即是当前生成器的输出结果。
随着迭代次数的增加,生成图像将会越来越清晰。
损失函数
SinGAN网络的损失函数由两部分组成,一是对抗损失,二是重建损失。对抗损失是判别器判别图谱的平均值,原文献中采用了wgan-gp以增强训练的稳定性。重建损失是固定第一个生成器的输入噪音,后面生成器的噪音使用零矩阵替代,用于重建图像,采用均方误差和原始图像进行对比。
SinGAN网络之Pytorch代码解读
源码下载
官方源码:https://github.com/tamarott/SinGAN
其他实现:https://github.com/FriedRonaldo/SinGAN
官方源码较为复杂,因此以其他人实现的代码进行解释,数据集采用随机图像
生成器

生成器初始化

生成器更新

生成器前传
生成器由5个卷积层组成,若前后两个生成器结构完全相同,后一个生成器初始化时继承前一个的权重和偏置,每个4个生成器翻倍一次卷积层的通道数,最开始的通道数为32个。
判别器

判别器前传
判别器的网络结构和更新与生成器相同,判别器前传生成和输入图像相同的判别图谱。
训练阶段

生成器的训练

判别器的训练
重建损失采用均方误差,对抗损失可选择wgan-gp、zero-gp和lsgan模式。第一个噪音采用符合标准正态分布的噪音,之后的噪音乘以均方根误差为系数。
验证阶段
对固定的噪音和随机的噪音进行验证,固定的噪音生成重建图像,随机的噪音生成假图片。

SinGAN网络之MindSpore实现
loss设置
与Pytorch不同,在MindSpore上的训练模型,loss和单步训练最好写成算子的形式。
g_loss设置

d_loss 设置
训练单步设置
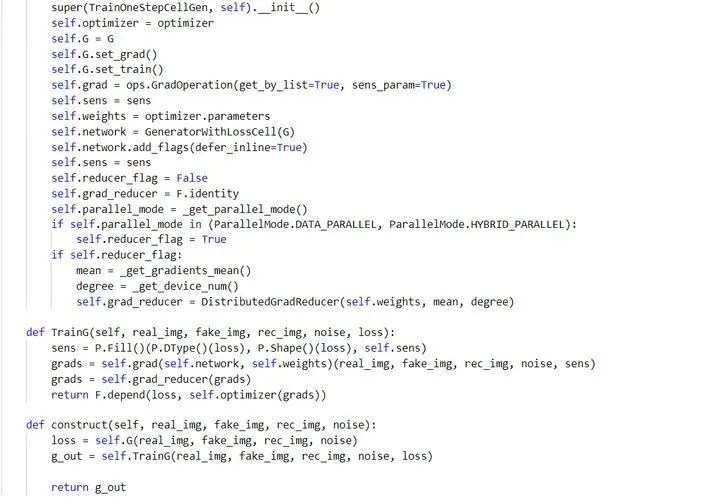
生成器训练单步设置
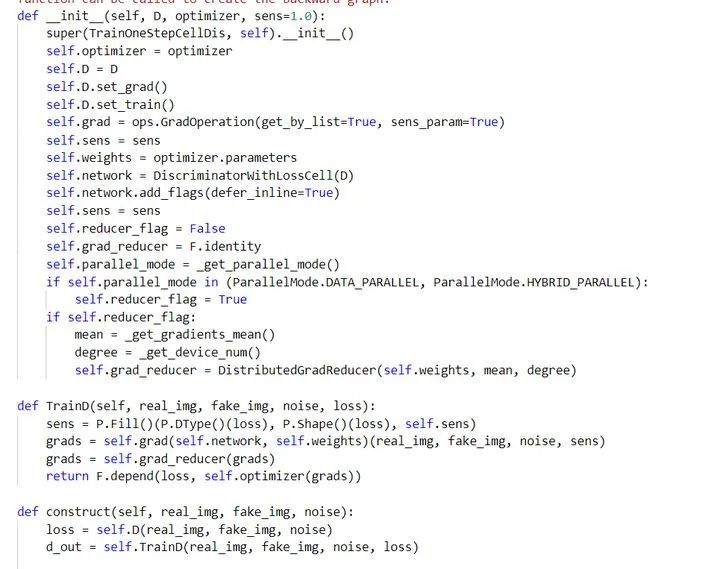
判别器训练单步设置
训练设置

把原始图像调整至需要的scale,获取对应的生成器和判别器并进行初始化,采用列表的形式保存之前的生成器,保证旧生成器关闭求导功能,采用adam优化器,并和loss模块绑定成单步训练。
开始训练

得到当前生成器的输入图像和噪音,开始训练。
保存图像

保存原始图像、重建图像和生成图像。

MindSpore官方资料
官方QQ群 : 486831414
官网:https://www.mindspore.cn/
Gitee : https : //gitee.com/mindspore/mindspore
GitHub : https://github.com/mindspore-ai/mindspore
论坛:https://bbs.huaweicloud.com/forum/forum-1076-1.html















 2340
2340











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









