







4.1 Numpy 优势
4.1.1 概述
Numpy(Numerical Python)是一个开源的Python科学计算库,用于快速处理任意维度的数组。
Numpy支持常见的数组和矩阵操作。对于同样的数值计算任务,使用Numpy比直接使用Python要简洁的多。
Numpy使用ndarray对象来处理多维数组,该对象是一个快速而灵活的大数据容器。
4.1.2 ndarray介绍
NumPy提供了一个N维数组类型ndarray,它描述了相同类型的“items”的集合。

用ndarray进行存储
import numpy as np
#创建ndarray
score=np.array([[80, 89, 86, 67, 79],
[78, 97, 89, 67, 81],
[90, 94, 78, 67, 74],
[91, 91, 90, 67, 69],
[76, 87, 75, 67, 86],
[70, 79, 84, 67, 84],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]])
print(score,"\n",score.dtype)
提问:
使用Python列表可以存储一维数组,通过列表的嵌套可以实现多维数组,那么为什么还需要使用Numpy的ndarray呢?
4.1.3 ndarray和原生list运算效率对比
通过一段代码,查看两者效率对比
import numpy as np
import time
#print(%time sum2=sum(b))
start1=time.time()
sum1=sum(a)
end1=time.time()
time1=end1-start1
print(time1)
b=np.array(a)
start2=time.time()
sum2=sum(b)
end2=time.time()
time2=end2-start2
print(time2)
其中第一个时间显示的是使用原生Python计算时间,第二个内容是使用numpy计算时间:

从中我们看到ndarray的计算速度要快很多,节约了时间。
机器学习的最大特点就是大量的数据运算,那么如果没有一个快速的解决方案,那可能现在python也在机器学习领域达不到好的效果。

Numpy专门针对ndarray的操作和运算进行了设计,所以数组的存储效率和输入输出性能远优于Python中的嵌套列表,数组越大,Numpy的优势就越明显。
思考:
ndarray为什么可以这么快?
4.1.4 ndarray的优势
-
- 内存块风格
ndarray到底跟原生python列表有什么不同呢,请看一张图:

从图中我们可以看出ndarray在存储数据的时候,数据与数据的地址都是连续的,这样就给使得批量操作数组元素时速度更快。
- 内存块风格
这是因为ndarray中的所有元素的类型都是相同的,而Python列表中的元素类型是任意的,所以ndarray在存储元素时内存可以连续,而python原生list就只能通过寻址方式找到下一个元素,这虽然也导致了在通用性能方面Numpy的ndarray不及Python原生list,但在科学计算中,Numpy的ndarray就可以省掉很多循环语句,代码使用方面比Python原生list简单的多。
-
- ndarray支持并行化运算(向量化运算)
numpy内置了并行运算功能,当系统有多个核心时,做某种计算时,numpy会自动做并行计算
- ndarray支持并行化运算(向量化运算)
-
- 效率远高于纯Python代码
Numpy底层使用C语言编写,内部解除了GIL(全局解释器锁),其对数组的操作速度不受Python解释器的限制,所以,其效率远高于纯Python代码。
- 效率远高于纯Python代码
4.1.5 小结
- numpy介绍【了解】
- 一个开源的Python科学计算库
- 计算起来要比python简洁高效
- Numpy使用ndarray对象来处理多维数组
- ndarray介绍【了解】
- NumPy提供了一个N维数组类型ndarray,它描述了相同类型的“items”的集合。
- 生成numpy对象:np.array()
- ndarray的优势【掌握】
- 内存块风格
- list – 分离式存储,存储内容多样化
- ndarray – 一体式存储,存储类型必须一样
- ndarray支持并行化运算(向量化运算)
- ndarray底层是用C语言写的,效率更高,释放了GIL
4.2 N维数组-ndarray
4.2.1 ndarray的属性
数组属性反映了数组本身固有的信息

4.2.2 ndarray的形状
创建数组
import numpy as np
#创建不同形状数组
a=np.array([[1,2,3],[4,5,6]])
b=np.array([1,2,3,4])
c=np.array([[[1,2,3],[4,5,6]],[[1,2,3],[4,5,6]]])
print(a.shape)
print(b.shape)
print(c.shape)
分别打印出以及形状

如何理解数组形状?列-特征值,行-样品量,块-sheet分区
二维数组:

三维数组:

4.2.3 ndarray的类型
>>> type(score.dtype)
<type 'numpy.dtype'>
dtype是numpy.dtype类型,先看看对于数组来说都有哪些类型

创建数组,如何指定类型?
a=np.array([[1,2,3],[4,5,6]],dtype=np.float32)
print(a.dtype)
#指定字符串的时候一定不要忘记_,string_
arr=np.array(['python', 'tensorflow', 'scikit-learn', 'numpy'],dtype=np.string_)
print(arr,",","dtype=",arr.dtype)
输出结果为
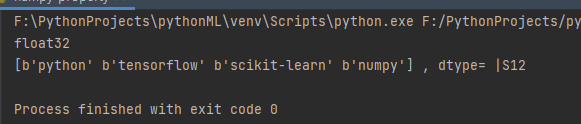
- 注意:若不指定,整数默认int64,小数默认float64
4.3 基本操作
4.3.1 生成数组的方法
-
- 生成0和1的数组**
- np.ones(shape,dtype)
- np.ones_like(a,dtype)
- np.zeros(shape,dtype)
- np.zeros_like(a,dtype)
ones = np.ones([4,8])
ones
返回结果


返回结果:

-
- 从现有数组生成
- 生成方式
(1)np.array(object,dtype)
(2)np.asarray(a,dtype)
a = np.array([[1,2,3],[4,5,6]])
# 从现有的数组当中创建
a1 = np.array(a)
# 相当于索引的形式,并没有真正的创建一个新的
a2 = np.asarray(a)
- 关于array和asarray不同
#array和asarray不同
a=np.array([[1,2,3],[4,5,6]])
print(a)
a1=np.array(a)
print(a1)
a2=np.asarray(a)
print(a2)
a[0,0]=100
print(a)
print(a1) #深度拷贝,重新建了一个数组,因此原数组改变,a1并不改变
print(a2) #浅拷贝,只是建了一个索引,因此原数组改变,a2不改变
运行结果

-
- 生成固定范围数组
- np.linspace(start,stop,num,endpoint)
(1)创建等差数组—指定数量
(2)参数
start:序列的起始值
stop:序列的终止值
num:要生成的等间隔样例数量,默认为50
endpoint:序列中是否包含stop值,默认为ture
#生成等间隔的数组
np.linespace(0,100,11)
返回结果:

- np.arange(start,stop,step,dtype)
(1)创建等差数组——指定步长
(2)参数——step 步长,默认值为1
np.arange(10,50,2)
返回结果
array([10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42,
44, 46, 48])
- np.logspace(start,stop,num)
- 创建等比数列
- 参数,num为要生成的等比数列数量,默认50
# 生成10^x
np.logspace(0, 2, 3)
起始0,终值2,生成3个,那么要生成10^0,10 ^1,10 ^2返回结果
array([ 1., 10., 100.])
-
- 生成随机数组
(1)使用模块:np.random
(2)正态分布创建方式:- np.random.randn(d0,d1,—dn)
功能:从标准正态分布中返回一个或多个样本值 - np.random.normal(loc=0.0, scale=1.0, size=None)
loc:float
此概率分布的均值(对应着整个分布的中心centre)
scale:float
此概率分布的标准差(对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高)
size:int or tuple of ints
- np.random.randn(d0,d1,—dn)
- 生成随机数组
输出的shape,默认为None,只输出一个值
(3)np.random.standard_normal(size=none)
返回指定形状的标准正态分布的数组。
举例1:生成均值为1.75,标准差为1的正态分布数据,100000000个
#准备数据
x1=np.random.normal(1.75,1,100000000)
#画图看分布
plt.figure(figsize=(20,10),dpi=100)
plt.hist(x1,1000)
plt.show()

-
- 均匀分布
- np.random.rand(d0,d1,…,dn):返回【0.0,1.0)内的一组均匀分布的数
- np.random.uniform(low=0.0,high=1.0,size=None)
- 功能:从一个均匀分布[low,high)中随机采样,注意定义域是左闭右开,即包含low,不包含high
- 参数:low-采样下界,float类型,默认值0;high-采样上届,float类型,默认值1;size输出样本数目,缺省时输出1个值
- 返回值:ndarray类型,其形状和参数size中描述一致 - np.random.randint(low,high=None,size=None,dtype=“I”)
-
- 从一个均匀分布中随机采样,生成一个整数或N维整数数组,取数范围:若high不为None时,取[low,high)之间随机整数,否则取值[0,low)之间随机整数。 - 画图看分布情况
- 均匀分布
import matplotlib.pyplot as plt
import numpy as np
#生成均匀分布的随机数
x2=np.random.uniform(-1,1,10000000)
#画图看分布情况
plt.figure(figsize=(20,8),dpi=80)
plt.hist(x=x2,bins=1000)
plt.show()
绘制图像如图:

4.3.2 数组的索引,切片
一维、二维、三维的数组如何索引?
- 直接进行索引,切片
- 对象[:, :] – 先行后列
二维数组索引方式:
In [4]: import numpy as np
In [5]: import random
In [6]: stock_change=np.random.normal(0,1,(4,5))
In [7]: stock_change
Out[7]:
array([[ 0.97061876, -0.70254943, -0.77200517, 0.49441497, 0.39987778],
[-0.17385982, -0.48943064, 0.1857307 , 0.44683973, -1.45188972],
[ 1.59531535, 0.40021221, -0.16226631, -0.21610488, 0.33071997],
[ 0.7183588 , -0.12795818, -0.33117327, 1.2075107 , -0.2414717 ]])
In [8]: stock_change[0,0:3]
Out[8]: array([ 0.97061876, -0.70254943, -0.77200517])
注意: array[a,b,c]分别代表块,行,列,array[a,b],分别代表行,列。另外索引是【】不是()
- 三维数组索引方式
In [9]: a1=np.array([[[1,2,3],[4,5,6]],[[1,2,3],[4,5,6]]])
In [10]: a1
Out[10]:
array([[[1, 2, 3],
[4, 5, 6]],
[[1, 2, 3],
[4, 5, 6]]])
In [11]: a1[0,0,1]
Out[11]: 2
4.3.4. 形状修改
-
- ndarray.reshape(shape,order)
- 返回一个具有相同数据域,但shape不一样的视图,原数组不需要改变
行、列不进行互换
# 在转换形状的时候,一定要注意数组的元素匹配
stock_change.reshape([5, 4])
stock_change.reshape([-1,10]) # 数组的形状被修改为: (2, 10), -1: 表示通过待计算
- ndarray.resize(new_shape)
- 修改数组本身的形状(需要保持元素个数前后相同),原数组形状会改变
行、列不进行互换
stock_change.resize([5, 4])
# 查看修改后结果
stock_change.shape
(5, 4)
- ndarray.T
数组的转置
将数组的行、列进行互换
In [12]: stock_change.T.shape
...:
Out[12]: (5, 4)
4.3.4 类型修改
-
- ndarray.astype(type)
- 返回修改了类型以后的数组
In [13]: stock_change.astype(int32)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-13-74f9b98675d1> in <module>
----> 1 stock_change.astype(int32)
NameError: name 'int32' is not defined
In [14]: stock_change.astype(np.int32)
Out[14]:
array([[ 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, -1],
[ 1, 0, 0, 0, 0],
[ 0, 0, 0, 1, 0]])
-
- ndarray.tostring([order])或者ndarray.tobytes([order])
构造包含数组中原始数据字节的Python字节
- ndarray.tostring([order])或者ndarray.tobytes([order])
In [15]: stock_change.T.shape
...: stock_change.tostring()
Out[15]: b'\xc2T)\x14O\x0f\xef?\xd1;\xd2\xefH{\xe6\xbfV\x1am0D\xb4\xe8\xbfS=\x86\xaf~\xa4\xdf?W7\xdb\xf9\x98\x97\xd9?1_\xd0\xd9\tA\xc6\xbf\xc2W\xe9\xe0\xd4R\xdf\xbf@0\x04\x08\x06\xc6\xc7?\x91\xb6\xed\xa5\x05\x99\xdc?\xd3\r\xdb\xb6\xf0:\xf7\xbf\x9a\xfa@bi\x86\xf9?\x0b\xd0\x0f\xa8\x13\x9d\xd9?/\x86aw$\xc5\xc4\xbf\x03<\xaf)S\xa9\xcb\xbf\xf7\x04A\x17\x84*\xd5?\x10\xde\\\x98\xcb\xfc\xe6?\xd5\xd8[\x03\xef`\xc0\xbf\x9c\x90\x80_\xf11\xd5\xbf\xd2!\x9f\xbd\xf6Q\xf3?\xdcb g\x8b\xe8\xce\xbf'
- jupyter输出太大可能导致崩溃问题【了解】
如果遇到:
IOPub data rate exceeded.
The notebook server will temporarily stop sending output
to the client in order to avoid crashing it.
To change this limit, set the config variable
`--NotebookApp.iopub_data_rate_limit`.
这个问题是在jupyer当中对输出的字节数有限制,需要去修改配置文件
创建配置文件
jupyter notebook --generate-config
vi~/.jupyter/jupyter_notebook_config.py
取消注释,多增加
## (bytes/sec) Maximum rate at which messages can be sent on iopub before they
# are limited.
c.NotebookApp.iopub_data_rate_limit = 10000000
4.3.5. 数组去重
- np.unique()
temp = np.array([[1, 2, 3, 4],[3, 4, 5, 6]])
>>> np.unique(temp)
array([1, 2, 3, 4, 5, 6])
4.3.6 小结
-
创建数组【掌握】
- 生成0和1的数组
- np.ones()
- np.ones_like()
- 从现有数组中生成
- np.array – 深拷贝
- np.asarray – 浅拷贝
- 生成固定范围数组
- np.linspace()
- nun – 生成等间隔的多少个
- np.arange()
- step – 每间隔多少生成数据
- np.logspace()
- 生成以10的N次幂的数据
- np.linspace()
- 生成随机数组
- 正态分布
- 里面需要关注的参数:均值:u, 标准差:σ
u – 决定了这个图形的左右位置
σ – 决定了这个图形是瘦高还是矮胖 - np.random.randn()
- np.random.normal(0, 1, 100)
- 里面需要关注的参数:均值:u, 标准差:σ
- 正态分布
- 均匀
- np.random.rand()
- np.random.uniform(0, 1, 100)
- np.random.randint(0, 10, 10)
- 生成0和1的数组
-
数组索引【知道】
- 直接进行索引,切片
- 对象[:, :] – 先行后列
- 数组形状改变【掌握】
- 对象.reshape()
没有进行行列互换,新产生一个ndarray - 对象.resize()
没有进行行列互换,修改原来的ndarray - 对象.T
进行了行列互换
- 对象.reshape()
- 直接进行索引,切片
-
数组去重【知道】
np.unique(对象)
4.4 ndarray的运算
1. 逻辑运算
Code
import numpy as np
import random
#生成10名同学,5门功课的成绩,最低分40,最高分100
score=np.random.randint(40,100,[10,5])
score
array([[70, 79, 66, 69, 84],
[87, 55, 65, 97, 54],
[86, 49, 80, 94, 84],
[92, 66, 60, 82, 81],
[96, 55, 46, 71, 74],
[85, 95, 62, 92, 54],
[58, 42, 48, 91, 45],
[97, 84, 80, 77, 99],
[67, 40, 76, 53, 49],
[69, 81, 41, 47, 49]])
#取出最后4名同学的成绩,用于逻辑判断
score[6:9,]
array([[58, 42, 48, 91, 45],
[97, 84, 80, 77, 99],
[67, 40, 76, 53, 49]])
test_score=score[6:9,]
#逻辑判断, 如果成绩大于60就标记为True 否则为False
test_score>60
array([[False, False, False, True, False],
[ True, True, True, True, True],
[ True, False, True, False, False]])
#
#BOOL赋值, 将满足条件的设置为指定的值-布尔索引
=1
test_score[test_score>0]=1
test_score
test_score
array([[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1]])
2 通用判断函数
- np.all()
#判断前两名成绩[0:2,:]是否全部大于60
np.all(score[0:2,:]>60)
- np.any()
#判断前两名同学的成绩[0:2, :]是否有大于90分的
np.any(score[0:2,]>90)
3. np.where(三元运算符)
判断前两名同学的成绩[0:2, :]是否有大于90分的
emp=score[:4,:4]
temp
array([[70, 79, 66, 69],
[87, 55, 65, 97],
[86, 49, 80, 94],
[92, 66, 60, 82]])
#判断前四名学生,前四门课程中,成绩中大于60的置为1,否则为0
np.where(temp>60,1,0)
array([[1, 1, 1, 1],
[1, 0, 1, 1],
[1, 0, 1, 1],
[1, 1, 0, 1]]
4. 统计运算
如果想要知道学生成绩最大的分数,或者做小分数应该怎么做?
(1)统计指标
在数据挖掘/机器学习领域,统计指标的值也是我们分析问题的一种方式。常用的指标如下:
- min(a, axis)
Return the minimum of an array or minimum along an axis. - max(a, axis])
Return the maximum of an array or maximum along an axis. - median(a, axis)(中数)
Compute the median along the specified axis. - mean(a, axis, dtype)(算术均值)
Compute the arithmetic mean along the specified axis. - std(a, axis, dtype)
Compute the standard deviation along the specified axis. - var(a, axis, dtype)(方差)
Compute the variance along the specified axis
(2)案例:学生成绩统计运算
emp2=score[0:4,0:5]
temp2,0
print("前四名学生,各科成绩最大分{}".format(np.max(temp2,0)))
前四名学生,各科成绩最大分[92 79 80 97 84]
print("前四名学生,各科成绩最小份{}".format(np.min(temp2,0))
File "<ipython-input-16-7bcf2c8b99c0>", line 1
print("前四名学生,各科成绩最小份{}".format(np.min(temp2,0))
^
SyntaxError: unexpected EOF while parsing
print("前四名学生,各科成绩最小份{}".format(np.min(temp2,axis=0)))
前四名学生,各科成绩最小份[70 49 60 69 54]
如果需要统计出某科最高分对应的同学是哪位
- np.argmax(temp,axis=)
print("前四名同学,各科成绩最高分对应的学生下标{}".format(np.argmax(temp2,axis=0)))
前四名同学,各科成绩最高分对应的学生下标[3 0 2 1 0]
5 小结
- 逻辑运算【知道】
- 直接进行大于,小于的判断
- 合适之后,可以直接进行赋值
- 通用判断函数【知道】
np.all()
np.any() - 统计运算【掌握】
np.max()
np.min()
np.median()
np.mean()
np.std()
np.var()
np.argmax(axis=) — 最大元素对应的下标
np.argmin(axis=) — 最小元素对应的下标
4.5 数组间的运算
1 数组与数的运算
import numpy as np
]
arr=np.array([[1,2,3,4],[5,6,3,1]])
arr+1
array([[2, 3, 4, 5],
[6, 7, 4, 2]])
/2
arr/2
array([[0.5, 1. , 1.5, 2. ],
[2.5, 3. , 1.5, 0.5]])
- 2数组与数组之间的运算

上面这个能进行运算吗,结果是不行的
(1)广播机制 ——超级重要
数组在进行矢量化运算时,要求数组的形状是相等的。当形状不相等的数组执行算术运算的时候,就会出现广播机制,该机制会对数组进行扩展,使数组的shape属性值一样,这样,就可以进行矢量化运算了。
举例:
arr2=np.array([[0],[1],[2],[3]])
arr2.shape
arr2.shape
(4, 1)
arr3=np.array([1,2,3])
arr3.shape #注意,是shape,不是np.shape()
(3,)
arr2+arr3
arr2+arr3
array([[1, 2, 3],
[2, 3, 4],
[3, 4, 5],
[4, 5, 6]])
上述代码中,数组arr1是4行1列,arr2是1行3列。这两个数组要进行相加,按照广播机制会对数组arr1和arr2都进行扩展,使得数组arr1和arr2都变成4行3列。下面通过一张图来描述广播机制扩展数组的过程:

广播机制实现了时两个或两个以上数组的运算,即使这些数组的shape不是完全相同的,只需要满足如下任意一个条件即可。
- 数组的某一维度等长。
- 其中一个数组的某一维度为1 。
广播机制需要扩展维度小****的数组,使得它与维度最大的数组的shape值相同,以便使用元素级函数或者运算符进行运算。
如果是下面这样,则不匹配:

思考:下面两个ndarray能否进行运算?

一个形状是(2,5),一个形状是(2,1)可以运算
2. 小结
数组运算,满足广播机制,就OK【知道】
(1).维度相等
(2).shape(其中对应的地方为1,也是可以的)
4.6 数学矩阵
- 矩阵和向量
(1)矩阵

(2)向量

- 加法和标量乘法

3 矩阵向量乘法
矩阵和向量的乘法如图:m×n 的矩阵乘以 n×1 的向量,得到的是 m×1 的向量

4. 矩阵乘法

- 矩阵乘法的性质
矩阵的乘法不满足交换律:A×B≠B×A
矩阵的乘法满足结合律。即:A×(B×C)=(A×B)×C
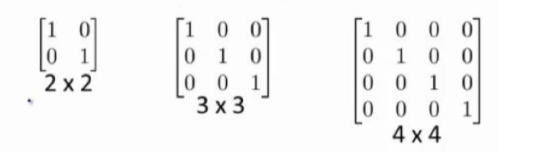
单位矩阵:在矩阵的乘法中,有一种矩阵起着特殊的作用,如同数的乘法中的 1,我们称 这种矩阵为单位矩阵.它是个方阵,一般用 I 或者 E 表示,从 左上角到右下角的对角线(称为主对角线)上的元素均为 1 以外全都为 0。如:
6. 逆、转置
矩阵的逆:如矩阵 A 是一个 m×m 矩阵(方阵),如果有逆矩阵,则:
AA-1 = A-1A = I
低阶矩阵求逆的方法:
(1)待定系数法
(2)初等变换
矩阵的转置:设 A 为 m×n 阶矩阵(即 m 行 n 列),第 i 行 j 列的元素是 a(i,j),即:
A=a(i,j)
定义 A 的转置为这样一个 n×m 阶矩阵 B,满足 B=a(j,i),即 b (i,j)=a (j,i)(B 的第 i 行第 j 列元素是 A 的第 j 行第 i 列元素),记 AT =B。
直观来看,将 A 的所有元素绕着一条从第 1 行第 1 列元素出发的右下方 45 度的射线作 镜面反转,即得到 A 的转置。
7 矩阵成分api:
- np.matmul
- np.dot
= np.array([[80, 86],
[82, 80],
[85, 78],
[90, 90],
[86, 82],
[82, 90],
[78, 80],
[92, 94]])
b = np.array([[0.7], [0.3]])
b = np.array([[0.7], [0.3]])
a*b
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-25-8ce765dcfa30> in <module>
----> 1 a*b
ValueError: operands could not be broadcast together with shapes (8,2) (2,1)
np.matmul(a,b)
array([[81.8],
[81.4],
[82.9],
[90. ],
[84.8],
[84.4],
[78.6],
[92.6]])
np.matmul和np.dot的区别:
二者都是矩阵乘法。 np.matmul中禁止矩阵与标量的乘法。 在矢量乘矢量的內积运算中,np.matmul与np.dot没有区别。
- 小结
- 矩阵和向量【知道】
- 矩阵就是特殊的二维数组
- 向量就是一行或者一列的数据 - 矩阵加法和标量乘法【知道】
- 矩阵的加法:行列数相等的可以加。
- 矩阵的乘法:每个元素都要乘。 - 矩阵和矩阵(向量)相乘 【知道】
(M行, N列)*(N行, L列) = (M行, L列) - 矩阵性质【知道】
矩阵不满足交换率,满足结合律
单位矩阵【知道】:
对角线都是1的矩阵,其他位置都为0 - 矩阵运算【掌握】
np.matmul
np.dot
注意:二者都是矩阵乘法。 np.matmul中禁止矩阵与标量的乘法。 在矢量乘矢量的內积运算中,np.matmul与np.dot没有区别。















 1222
1222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









