







NumPy比Python自有方法和对象的优势
Numpy之所以在Python数据分析中占有重要地位,原因之一就是它的设计对于含有大量数组的数据非常高效。
a、NumPy是在一个连续的内存块中存储数据,独立于其他Python内置对象。NumPy的算法库是用C语言编写的,在操作数据内存不必进行类型检查或其它管理工作。比起Python的内置序列,NumPy数组使用的内存更少。
b、NumPy可以在整个数组上执行复杂的计算,而不需要Python的循环操作。
那么,Numpy到底是如何达到如此高效的?这就跟Numpy的多维数组对象ndarray内部设计相关:
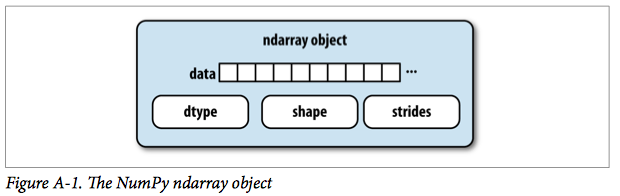
ndarray对象内部构造
Numpy的ndarray可以让我们把一组同构数据作为一个多维的数组对象。
- 数据类型,即dtype,会决定一个数据以何种类型被读取,比如浮点,整数,布尔,或其他一些数据类型。
ndarray之所以很灵活,是因为每一个数组对象是一块数据的分步视图。
在使用ndarray时,你可能会感到奇怪,为什么一个数组的视图(array view),arr[::2, ::-1]不会复制任何数据。其原因是ndarray不仅是一大块内存和一种数据类型,它还有步长信息,能让数组以不同的跨度在内存中进行移动。
更确切一点说,ndarray内部包含以下内容:
• 数据指针,在RAM中的一块数据或在内存映射文件中的数据。
• 数据类型,用来描述数组中固定大小的单元。
• 一个用来描述数组形状(shape)的元组(tuple)。
• 一个保存步长(strides)的元组,整数表明每一步的字节大小,好让元素沿着一个方向推进。
看下图显示了一个ndarray对象的内在构成:
比如,一个10x5的数组,形状是(10, 5):
import numpy as np
np.ones((10, 5)).shape
(10, 5)
一个典型的3x4x5数组,类型为float64(8-byte),跨度为(160, 40, 8)(对于跨度的使用要小心,通常情况下,在某一维度上的跨度越大,运算消耗越大):
一个值是8字节,所以一个数字之间的跨度是8,在第一个维度上,有三个4x5的矩阵,所以每个之间是4x5x8=160个字节的跨度。
np 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1886
1886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









