







 本文介绍了信息检索领域中的评价指标DCG和nDCG,详细解释了这两个指标的计算方式及其应用场景,并通过对比说明了它们与推荐场景常用指标AUC的区别。
本文介绍了信息检索领域中的评价指标DCG和nDCG,详细解释了这两个指标的计算方式及其应用场景,并通过对比说明了它们与推荐场景常用指标AUC的区别。
简介
top-n 推荐领域的排序任务: 对候选集合作排列, 不仅要识别出样本的正负, 还要对正样本作进一步分档, 把更好的排在更前面.
再对比下分类任务: 仅需对一个样本(候选)作出识别即可.
更高一层的抽象: 也可以认为 分类就是排序, 因为 ctr 预估的值域为 (0,1), 对 ctr_pred 作排序就是排序任务.
1. NDCG
NDCG, Normalized Discounted Cumulative Gain, 正规化的折扣累积收益.
是信息检索领域中, 对排序问题的一个评价指标, 因素有文档相关性与排序位置.
This measure is based on two following assumptions:
- 高度相关文档在排名靠前时, 对用户的帮助更大
- 高度相关文档比轻微相关文档, 对用户的帮助更大
Q: 与推荐场景常用的AUC, 有何区别?
A: 区别于评测样本的组织形式. ndcg 的样本为候选集合, auc 的样本是单个候选.
DCG
计算前k个结果的DCG.
DCG@k=∑i=1krel(i)log2(i+1)(1)\mathrm{DCG@k} = \sum_{i=1}^{k} \frac{rel_{(i)}}{\log_{2}(i+1)} \tag 1DCG@k=i=1∑klog2(i+1)rel(i)(1)
where rel(i)rel_{(i)}rel(i) is i-th doc’s relevant score. kkk is the rank position.
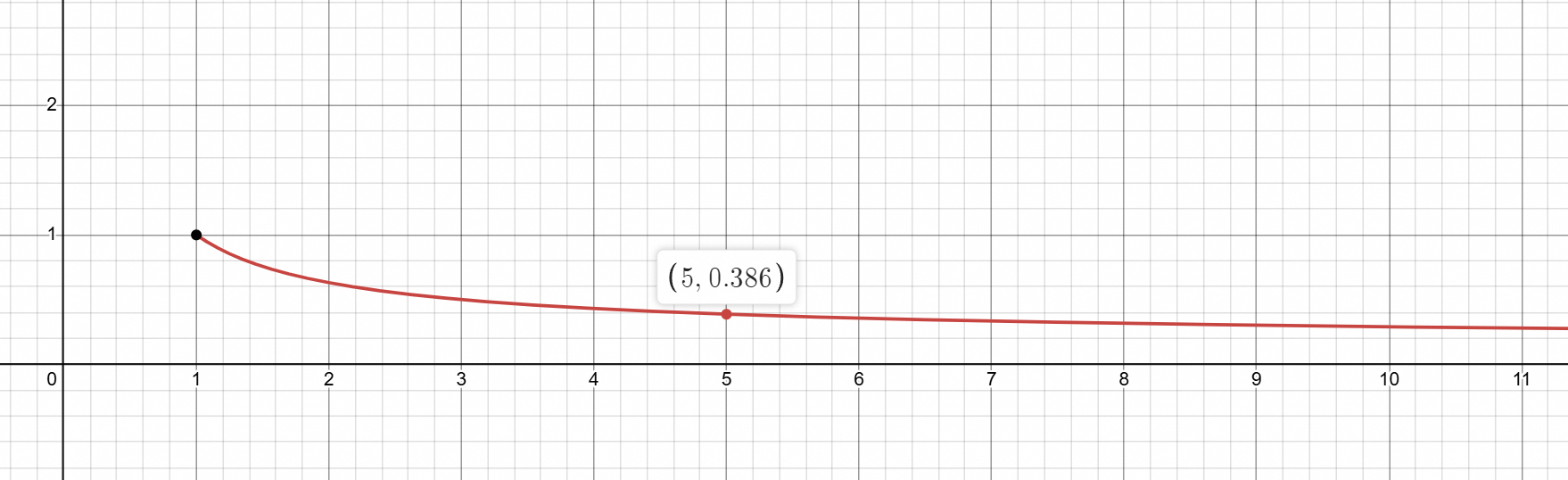
y=1log2(x+1)y=\frac 1{\log_2{(x+1)}}y=log2(x+1)1 图表见下, 位置越靠后, 重要性越低.
nDCG
DCG 直接用并不直观, 因为不同的 query, 搜索结果的个数不一致, 所以需要正规化.
引入 IDCG, 表示在理想情况下, 这些文档按照相关性单调递减排序时的DCG 得分.
nDCGk(或 nDCG@k)=DCGkIDCGk \mathrm{nDCG_{k}}(或\ nDCG@k) = \frac {DCG_k} {IDCG_k} nDCGk(或 nDCG@k)=IDCGkDCGk
2. MAP
MAP(Mean Average Precision), 平均精度均值。
评价预测列表中 { top-1, top-2, …, top-k} 的精度的平均.
P@k
Precision, 精度. 如 P@k=前k个位置的正样本数kP@k =\frac{前k个位置的正样本数}kP@k=k前k个位置的正样本数.
AP
Average Precision, 指一个用户下的样本在不同 top 位置的 精度均值.
注意这里引入了 Hitting point(命中点)的概念, 仅在正样本所在的位置k上作指标累积. 这个口径的依据是 Qwen, chatGPT 给出的 py 实现中都有该细节.
AP@n=∑k=1nP@k⋅I(k)∑k=1nI(k)(1)AP@n=\frac {\sum_{k=1}^n P@k \cdot I(k)}{\sum_{k=1}^n I(k)} \tag 1AP@n=∑k=1nI(k)∑k=1nP@k⋅I(k)(1)
其中 I(k) 仅在 k位置上的样本为正时 值为1.
MAP
mean 指多个用户之间的 AP 再次求均值.
3. GSB
通常用于两个模型之间的对比, 而非单个模型的评测.
ΔGSB=#good−#bad#good+#same+#bad\Delta GSB=\frac{\#good-\#bad}{\#good+\#same+\#bad}ΔGSB=#good+#same+#bad#good−#bad
场景为已经有了一版模型A, 现在迭代了一版模型B, 评估B是否更优于A
| <query,doc> | B模型比A模型的提升 |
|---|---|
| q1,d1 | good |
| q2,d2 | same |
| q3,d3 | bad |
| q4,d4 | bad |
按照上表的统计,
ΔGSB=−1/4\Delta GSB=-1/4ΔGSB=−1/4, 不能上线.

















 6855
6855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









