







 本文详细介绍了语谱图的生成过程,包括信号预处理、频谱映射和时间拼接。重点讲解了梅尔滤波器组的概念,它模拟人耳对不同频率的感知,尤其在语音识别和处理中起到关键作用。梅尔滤波器组由等高的三角滤波器构成,通过线性间隔出梅尔频率点并映射回Hz频率,再将这些频率映射到DFT频率,形成滤波器中心频率。最后,梅尔滤波器组用于功率谱,生成梅尔谱图,该图谱在人声识别等领域广泛应用。
本文详细介绍了语谱图的生成过程,包括信号预处理、频谱映射和时间拼接。重点讲解了梅尔滤波器组的概念,它模拟人耳对不同频率的感知,尤其在语音识别和处理中起到关键作用。梅尔滤波器组由等高的三角滤波器构成,通过线性间隔出梅尔频率点并映射回Hz频率,再将这些频率映射到DFT频率,形成滤波器中心频率。最后,梅尔滤波器组用于功率谱,生成梅尔谱图,该图谱在人声识别等领域广泛应用。
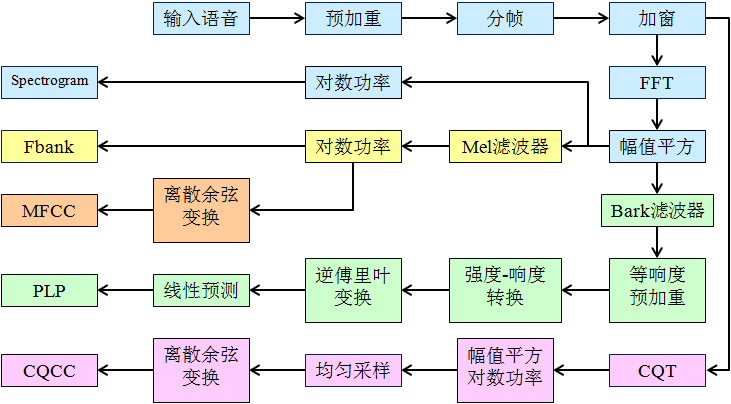
1. 语谱图的产生
这里在简单小结如下,
- 信号预处理,预加重, 分帧,
- 加窗, 进行STFT 变换, 生成频谱图;
- 对单帧信号的频谱进行映射, (2,3 步骤如下图)
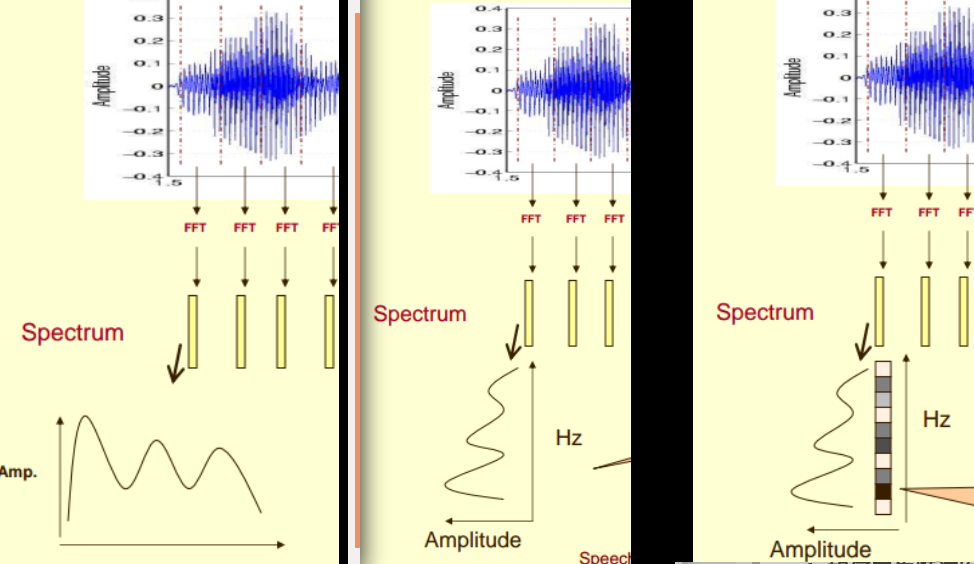
- 将映射后的多帧频谱, 在时间维度上进行拼接, 从而形成整个语谱图(如下图所示);
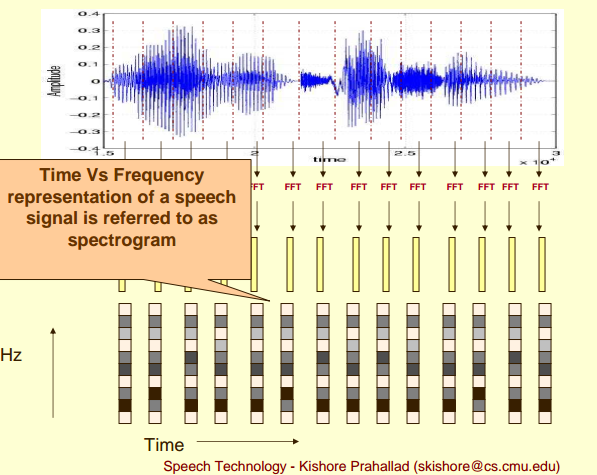
2. 频谱图的类型
这里需要说明的是,在实际使用中, 根据需求不同, 频谱图有三种类型
- 线性振幅谱
- 对数振幅谱 (对数振幅谱中各谱线的振幅都作了对数计算,所以其纵坐标的单位是dB分贝))
- 功率谱
而这里要介绍Mel_ spectrogram 语谱图, 其中的频谱类型使用的便是功率谱;
3. Mel 语谱图
- 在上述语谱图的形成过程中,其中频谱采用的功率谱,而后使用多帧的功率谱形成最终的语谱图;
Mel 语谱图便是将, 功率谱构成的语谱图, 经过Mel 滤波器组后,得到的语谱图, 称之为Mel 语谱图。
4. Mel 滤波器组的概念:
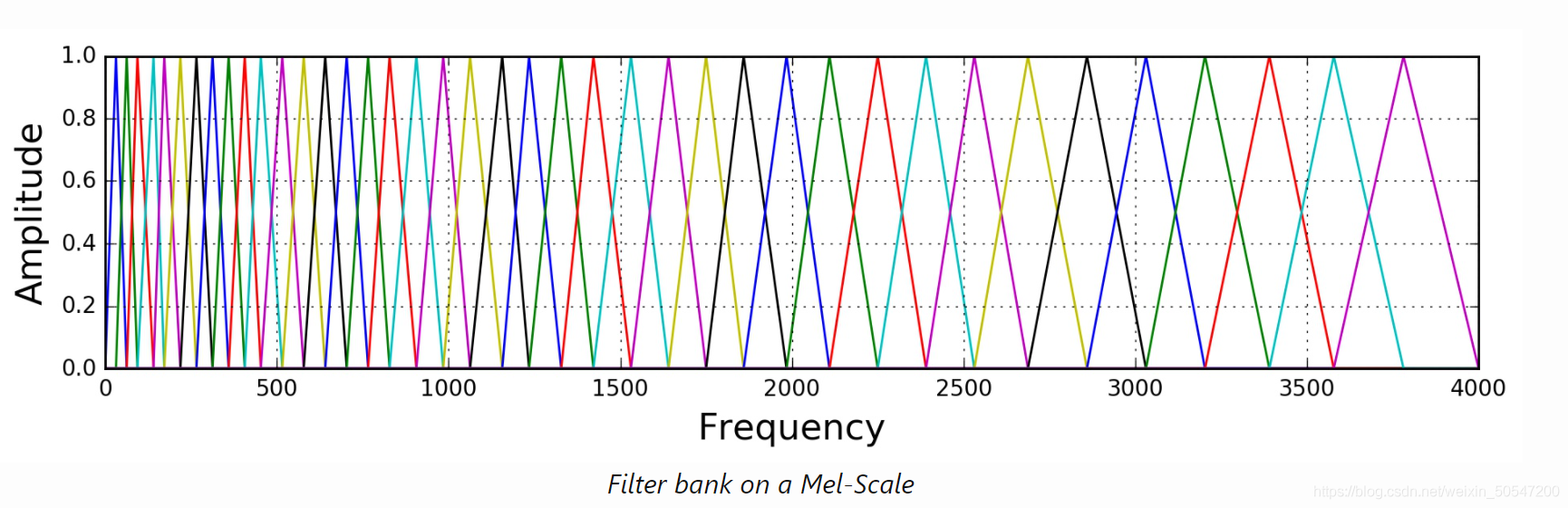
所谓梅尔滤波器组是一个等高的三角滤波器组,每个滤波器的起始点在上一个滤波器的中点处。其对应的频率在梅尔尺度上是线性的,因此称之为梅尔滤波器组。
每个滤波器对应的频率可以将最大频率(下图中是4000,我们这里是22.05k)用上文中提到的公式转换成梅尔频率,在梅尔尺度上线性分成若干个频段,再转换回实际频率尺度即可。
实际操作时,将每个滤波器分别和功率谱pow_frames进行点乘,获得的结果即为该频带上的能量(energy)。
4.1 Mel 滤波器的个数与 N f f t N_{fft} Nfft 点数之间的关系
梅尔滤波器fbank是一个(mel_N, 513)的矩阵,其中, N f f t N_{fft} Nfft 点数这里取得513, mel_N代表对应的梅尔滤波器个数,这个值不能太大,因为这里我们一共只有513个点,
如果mel_N取得太大,会导致前面几个滤波器的长度都是0 (因为低频的梅尔滤波器特别窄)。
梅尔滤波器的数量越多,因为低频的梅尔滤波器特别窄, 所以低频滤波器分到的频率点数越少,相应的就需要 N F F T N_{FFT} NFFT
提高,否则低频滤波器对应的点数太少甚至为0.
5. Mel 滤波器组产生
主要有分为三步:
- 将信号的最高频率和最低频率 映射到Mel 频率上, 根据Mel 滤波器的个数K, 在Mel低频率和Mel 高频率之间 线性间隔出 K 个附加 点, 共 (K + 2) 个 Mel频率点 m ( i ) m(i) m(i)。
映射到Mel 尺度上的原因,该Mel尺度的频率是拟合了人耳的线性变换,
-
将上述步骤一中, (K + 2) 个Mel 频率点 映射到(K + 2) 普通频率HZ上 h ( i ) h(i) h(i)
-
将步骤二中, (K + 2) 个普通频率取整到最接近的 frequency bin 频率上 f ( i ) f(i) f(i); 此时得到的 f ( i ) f(i) f(i) 即是各个滤波器的中心频率, 生成三角滤波器;
以下,依次介绍上面的三个步骤
5.1 Mel 滤波器中等间隔的Mel 频率:
求出 Mel 滤波器中,对应的等间隔的Mel频率:
假如有10个Mel滤波器
(在实际应用中通常一组Mel滤波器组有26个滤波器。)
首先要选择一个最高频率和最低频率,通常最高频率为8000Hz,最低频率为300Hz。
使用从频率转换为Mel频率的公式将300Hz转换为401.25Mels,8000Hz转换为2834.99Mels,
由于有10个滤波器,每个滤波器针对两个频率的样点,样点之间会进行重叠处理,因此需要12个点,意味着需要在401.25和2834.99之间再线性间隔出10个附加点,如:
m(i)=401.25,622.50,843.75,1065.00,1286.25,1507.50,1728.74,1949.99,2171.24,2392.49,2613.74,2834.99
5.2 Mel 频率转换为 HZ:
现在使用从Mel频率转换为频率的公式将它们转换回赫兹:
def hz2mel(hz):
'''把频率hz转化为梅尔频率'''
return 2595 * numpy.log10(1 + hz / 700.0)
def mel2hz(mel):
'''把梅尔频率转化为hz'''
return 700 * (10 ** (mel / 2595.0) - 1)
h(i)=300,517.33,781.90,1103.97,1496.04,1973.32,2554.33,3261.62,4122.63,5170.76,6446.70,8000
5.3 Mel 滤波器中心频率
将频率映射到最接近的DFT频率
其中 257 = N , N取值为 DFT 长度中的有效保留值,
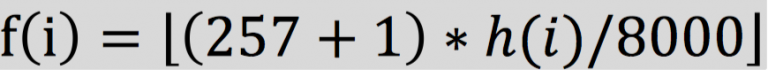
此时得到的 f(i), 便是 Mel 滤波器组中 各个滤波器的中心频率;
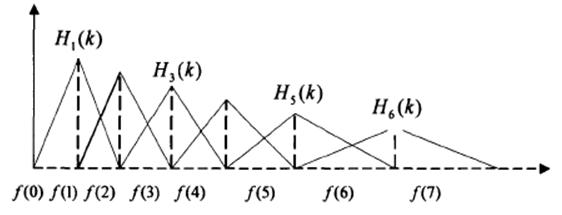
- Mel 滤波器的频率响应
在得到各个滤波器的中心频率后, 便可知 各个滤波器对应的频率响应;
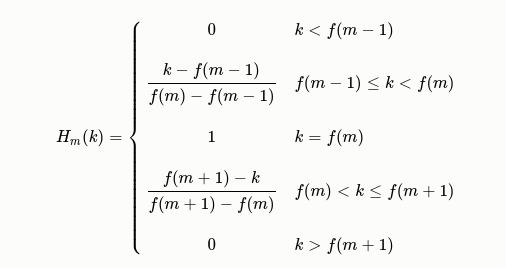
将功率谱形成的语谱图通过 Mel 滤波器组,便得到 Mel Spectrogram;
6. 简介 梅尔刻度
- 为什么需要 Mel 刻度:
MEL刻度模拟人耳对不同频率语音的感知:
研究表明,人类对频率的感知并不是线性的,并且对低频信号的感知要比高频信号敏感。对1kHz以下,与频率成线性关系,对1kHz以上,与频率成对数关系。频率越高,感知能力就越差。
例如,人们可以比较容易地发现500和1000Hz的区别,但很难发现7500和8000Hz的区别。
- Mel (melody)刻度定义:
这时,梅尔标度(the Mel Scale)被提出,它是Hz的非线性变换,对于以mel scale为单位的信号,可以做到人们对于相同频率差别的信号的感知能力几乎相同。
M = 2595 * log10 (1 + f / 700 ) ; M 被称作 Mel 频率;
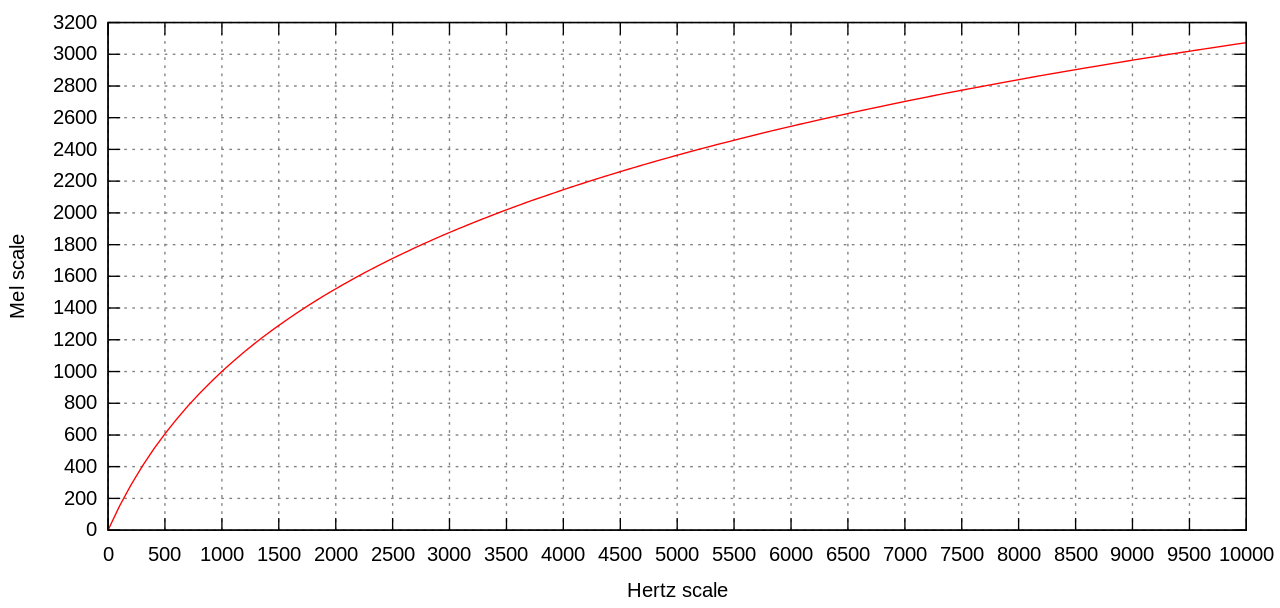
观察上图: 从Hz到mel的映射图,由于它们是log的关系,当频率较小时,mel随Hz变化较快;当频率很大时,mel的上升很缓慢,曲线的斜率很小。
这说明了人耳对低频音调的感知较灵敏,在高频时人耳是很迟钝的,梅尔标度滤波器组启发于此, 从而 梅尔滤波器 的 分布情况 受启发于此。
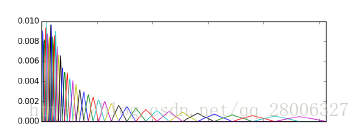
如上图所示,40个三角滤波器组成滤波器组,低频处滤波器密集,门限值大,高频处滤波器稀疏,门限值低。恰好对应了频率越高人耳越迟钝这一客观规律。上图所示的滤波器形式叫做等面积梅尔滤波器(Mel-filter bank with same bank area),在人声领域(语音识别,说话人辨认)等领域应用广泛,但是如果用到非人声领域,就会丢掉很多高频信息。

如上图所示,如果用到非人声领域,这时常用的是等高梅尔滤波器Mel-filter bank with same bank height;

















 1260
1260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









