






1. 信号的预处理部分
预处理部分中 包括 1. 预加重 2. 分帧 3. 加窗 ;
1.0 读取音频数据
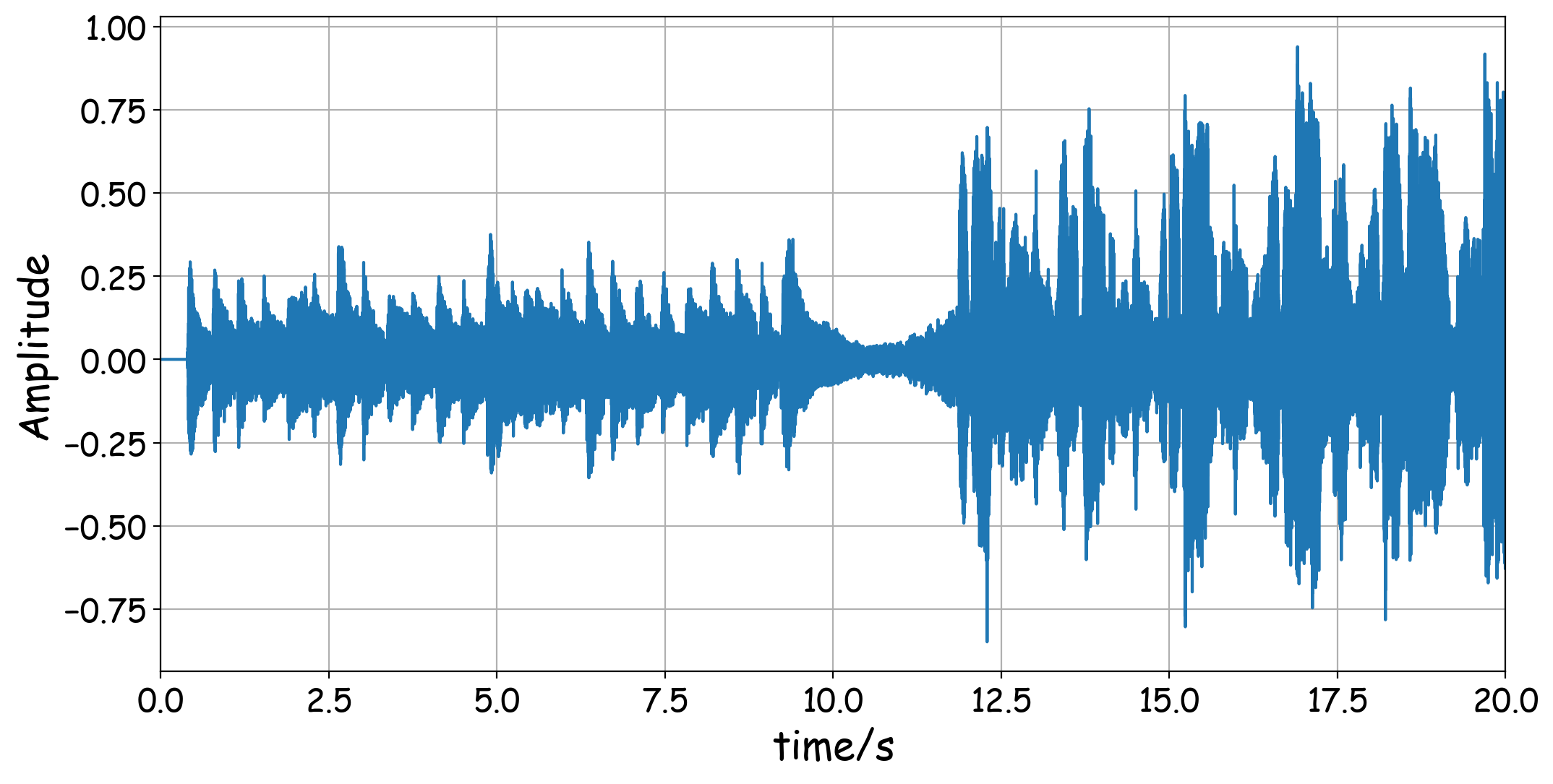
python可以用librosa库来读取音频文件,但是对于MP3文件,它会自动调用audio_read函数,所以如果是MP3文件,务必保证将ffmpeg.exe的路径添加到系统环境变量中,不然audio_read函数会出错。这里我们首先读取音频文件,并作出0-20秒的波形。现在的音乐文件采样率通常是44.1kHz。用y和sr分别表示信号和采样率。代码和图形如下:
import librosa
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rcParams
import matplotlib.ticker as ticker
#这是一个画图函数,方便后续作图
def personal_plot(x,y):
plt.figure(dpi=200,figsize=(12,6))
rcParams['font.family']='Comic Sans MS'
plt.plot(x,y)
plt.xlim(x[0],x[-1])
plt.xlabel('time/s',fontsize=20)
plt.ylabel('Amplitude',fontsize=20)
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
plt.grid()
#注意如果文件名不加路径,则文件必须存在于python的工作目录中
y,sr = librosa.load('笑颜.mp3',sr=None)
#这里只获取0-20秒的部分,这里也可以在上一步的load函数中令duration=20来实现
tmax,tmin = 20,0
t = np.linspace(tmin,tmax,(tmax-tmin)*sr)
personal_plot(t,y[tmin*sr:tmax*sr])
2.1 预加重
预加重其实就是将语音信号通过一个高通滤波器,来增强语音信号中的高频部分,并保持在低频到高频的整个频段中,能够使用同样的信噪比求频谱。在本实验中,选取的高通滤波器传递函数为:
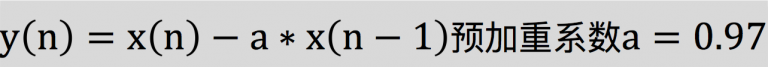
式中a的值介于0.9-1.0之间,我们通常取0.97。同时,预加重也是为了消除发生过程中声带和嘴唇的效应,来补偿语音信号受到发音系统所抑制的高频部分,也为了突出高频的共振峰。
def pre_emphasis(signal, coefficient=0.97):
'''对信号进行预加重'''
return numpy.append(signal[0], signal[1:] - coefficient * signal[:-1])
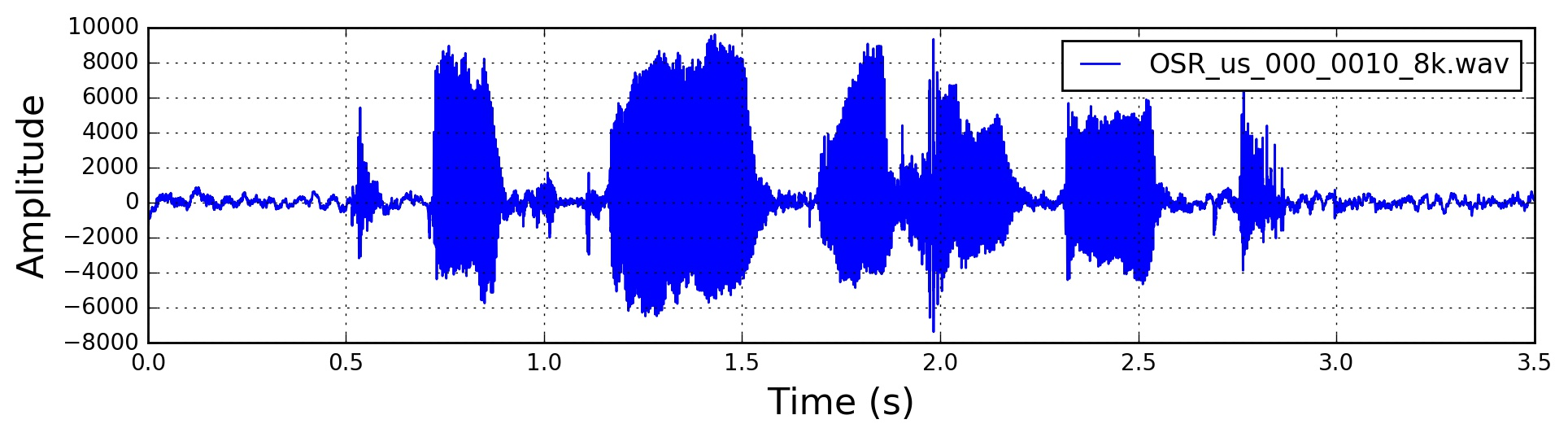
原始的音频时域信号:
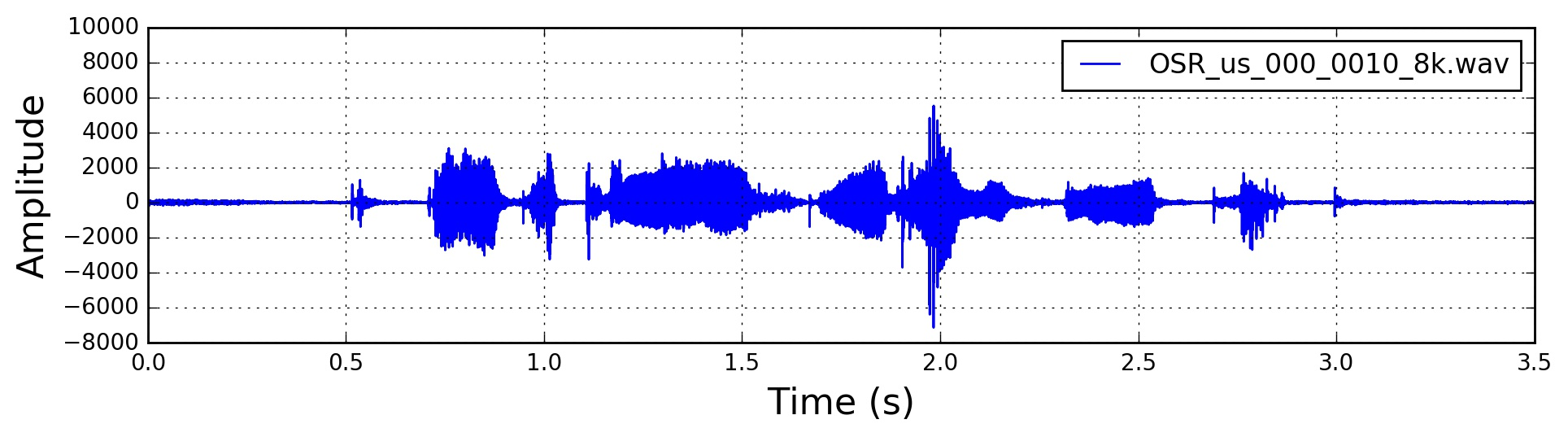
预加重后的时域信号:
2.2 分帧
分帧是指在给定的音频样本文件中,按照某一个固定的时间长度分割,分割后的每一片样本,称之为一帧,分割后的一帧是分析提取MFCC的样本,这里需要区分时域波形中的帧,时域波形中的帧是时域尺度上对音频的采样而取到的样本。
分帧是先将N个采样点集合成一个观测单位,也就是分割后的帧。通常情况下N的取值为512或256,涵盖的时间约为20-30ms。
也可以根据特定的需要进行N值和窗口间隔的调整。
为了避免相邻两帧的变化过大,会让两相邻帧之间有一段重叠区域,此重叠区域包含了M个取样点,一般M的值约为N的1/2或1/3。
语音识别中所采用的信号采样频率一般为8kHz或16kHz。
以8kHz来说,若帧长度为256个采样点,则对应的时间长度是256/8000×1000=32ms。
本次实验中所使用的采样率(Frames Per Second)16kHz,窗长25ms(400个采样点),窗间隔为10ms(160个采样点)。
def audio2frame(signal, frame_length, frame_step, winfunc=lambda x: numpy.ones((x,))):
'''分帧'''
signal_length = len(signal)
frame_length = int(round(frame_length))
frame_step = int(round(frame_step))
if signal_length <= frame_length:
frames_num = 1
else:
frames_num = 1 + int(math.ceil((1.0 * signal_length - frame_length) / frame_step))
pad_length = int((frames_num - 1) * frame_step + frame_length)
zeros = numpy.zeros((pad_length - signal_length,))
pad_signal = numpy.concatenate((signal, zeros))
indices = numpy.tile(numpy.arange(0, frame_length), (frames_num, 1)) + numpy.tile(numpy.arange(0, frames_num * frame_step, frame_step),(frame_length, 1)).T
indices = numpy.array(indices, dtype=numpy.int32)
frames = pad_signal[indices]
win = numpy.tile(winfunc(frame_length), (frames_num, 1))
return frames * win
2.3 加窗
在对音频进行分帧之后,需要对每一帧进行加窗,以增加帧左端和右端的连续性,减少频谱泄漏。在提取MFCC的时候,比较常用的窗口函数为Hamming窗。
假设分帧后的信号为 S(n),n=0,1,2…,N-1,其中N为帧的大小,那么进行加窗的处理则为:
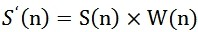
W(n)的形式如下:
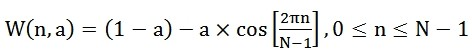
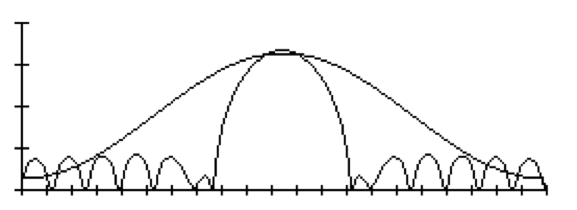
不同的a值会产生不同的汉明窗,一般情况下a取值0.46。进行值替换后,W(n)则为:

对应的汉明窗时域波形类似下图:
def deframesignal(frames, signal_length, frame_length, frame_step, winfunc=lambda x: numpy.ones((x,))):
'''加窗'''
signal_length = round(signal_length)
frame_length = round(frame_length)
frames_num = numpy.shape(frames)[0]
assert numpy.shape(frames)[1] == frame_length, '"frames"矩阵大小不正确,它的列数应该等于一帧长度'
indices = numpy.tile(numpy.arange(0, frame_length), (frames_num, 1)) + numpy.tile(numpy.arange(0, frames_num * frame_step, frame_step),(frame_length, 1)).T
indices = numpy.array(indices, dtype=numpy.int32)
pad_length = (frames_num - 1) * frame_step + frame_length
if signal_length <= 0:
signal_length = pad_length
recalc_signal = numpy.zeros((pad_length,))
window_correction = numpy.zeros((pad_length, 1))
win = winfunc(frame_length)
for i in range(0, frames_num):
window_correction[indices[i, :]] = window_correction[indices[i, :]] + win + 1e-15
recalc_signal[indices[i, :]] = recalc_signal[indices[i, :]] + frames[i, :]
recalc_signal = recalc_signal / window_correction
return recalc_signal[0:signal_length]
2. 求功率谱
2.1 做FFT,求频谱
对各帧信号做FFT变换,求出各帧的频谱;
由于信号在时域上的变换通常很难看出信号的特性,所有通常将它转换为频域上的能量分布来观察,不同的能量分布,代表不同语音的特性。所以在进行了加窗处理后,还需要再经过离散傅里叶变换以得到频谱上的能量分布。对分帧加窗后的各帧信号进行快速傅里叶变换得到各帧的频谱。
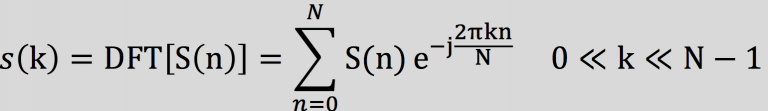
2.2 取频谱模平方, 求功率谱
对语音信号的频谱取模平方得到语音信号的功率谱
能量的分布为
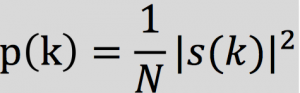
在本次实验中,采用DFT长度 N=512,结果值保留前257个系数。
def deframesignal(frames, signal_length, frame_length, frame_step, winfunc=lambda x: numpy.ones((x,))):
'''加窗'''
signal_length = round(signal_length)
frame_length = round(frame_length)
frames_num = numpy.shape(frames)[0]
assert numpy.shape(frames)[1] == frame_length, '"frames"矩阵大小不正确,它的列数应该等于一帧长度'
indices = numpy.tile(numpy.arange(0, frame_length), (frames_num, 1)) + numpy.tile(numpy.arange(0, frames_num * frame_step, frame_step),(frame_length, 1)).T
indices = numpy.array(indices, dtype=numpy.int32)
pad_length = (frames_num - 1) * frame_step + frame_length
if signal_length <= 0:
signal_length = pad_length
recalc_signal = numpy.zeros((pad_length,))
window_correction = numpy.zeros((pad_length, 1))
win = winfunc(frame_length)
for i in range(0, frames_num):
window_correction[indices[i, :]] = window_correction[indices[i, :]] + win + 1e-15
recalc_signal[indices[i, :]] = recalc_signal[indices[i, :]] + frames[i, :]
recalc_signal = recalc_signal / window_correction
return recalc_signal[0:signal_length]
下图是由 时域的单帧信号 对应到功率谱的转换结果示意图:

3. 功率谱 变换 --> 语谱图
在求出 单帧信号的功率谱后 ,
3.1 单帧功率谱图 映射
对其做 坐标变换, 然后 映射功率谱的幅度值;

3.2 拼接功率谱, 得语谱图
将多帧信号的 功率谱 拼接起来, 得到最终语谱图

参考资料
Mel-frequency cepstrum
Mel Frequency Cepstral Coefficient (MFCC) tutorial
Notes on Music Information Retrieval
机器学习中距离和相似性度量方法
https://robinchao.github.io/2018/07/24/speech-recognation-mfcc.html
https://www.cnblogs.com/LXP-Never/p/11602510.html















 3896
3896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









