






现在我们使用tiktoken来计算对应的tokens,tiktoken是OpenAI开源的一个快速分词工具。它将一个文本字符串(例如“tiktoken很棒!”)和一个编码(例如“cl100k_base”)作为输入,然后将字符串拆分为标记列表(例如["t","ik","token"," is"," great","!"])。
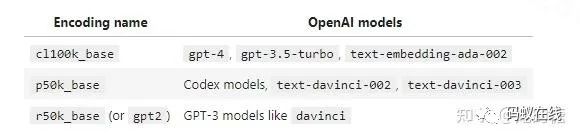
编码
编码指定如何将文本转换为tokens。不同的模型使用不同的编码。
可以使用tiktoken.encoding_for_model()检索模型的编码,如下所示:
encoding = tiktoken.encoding_for_model('gpt-3.5-turbo')请注意,p50k_base与r50k_base重叠很大,在非代码应用中,它们通常会给出相同的tokens。
字符串通常如何进行分词
在英语中,标记的长度通常从一个字符到一个单词不等(例如“t”或“great”),尽管在某些语言中,标记可以比一个字符更短或比一个单词更长。空格通常与单词的开头分组(例如“is”而不是“ is”或“+”“is”)。您可以在OpenAI Tokenizer(https://platform.openai.com/tokenizer)上快速检查字符串的分词方式。
0. 安装 tiktoken
%pip install --upgrade tiktoken1.引用 tiktoken
import tiktoken2. 加载编码
使用tiktoken.get_encoding()方法按名称加载一种编码。
第一次运行此方法时,需要连接互联网下载,之后的运行将不需要网络连接。
encoding = tiktoken.get_encoding("cl100k_base")使用tiktoken.encoding_for_model()方法,自动加载给定模型名称对应的正确编码。
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")3. 放入文本
.encode()方法将文本字符串转换为标记整数列表。
encoding.encode("tiktoken is great!")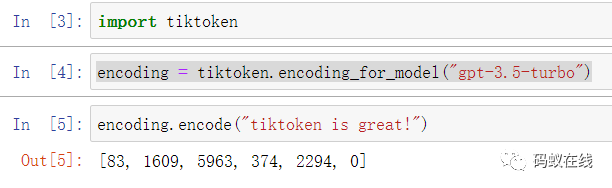
4.计算调用的token消耗
通过计算.encode()方法返回的列表长度来计算tokens。
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
num_tokens_from_string("tiktoken is great!", "cl100k_base")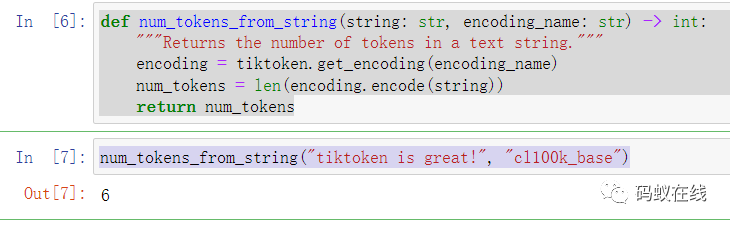
这里”tiktoken is great!“ 使用了6个tokens
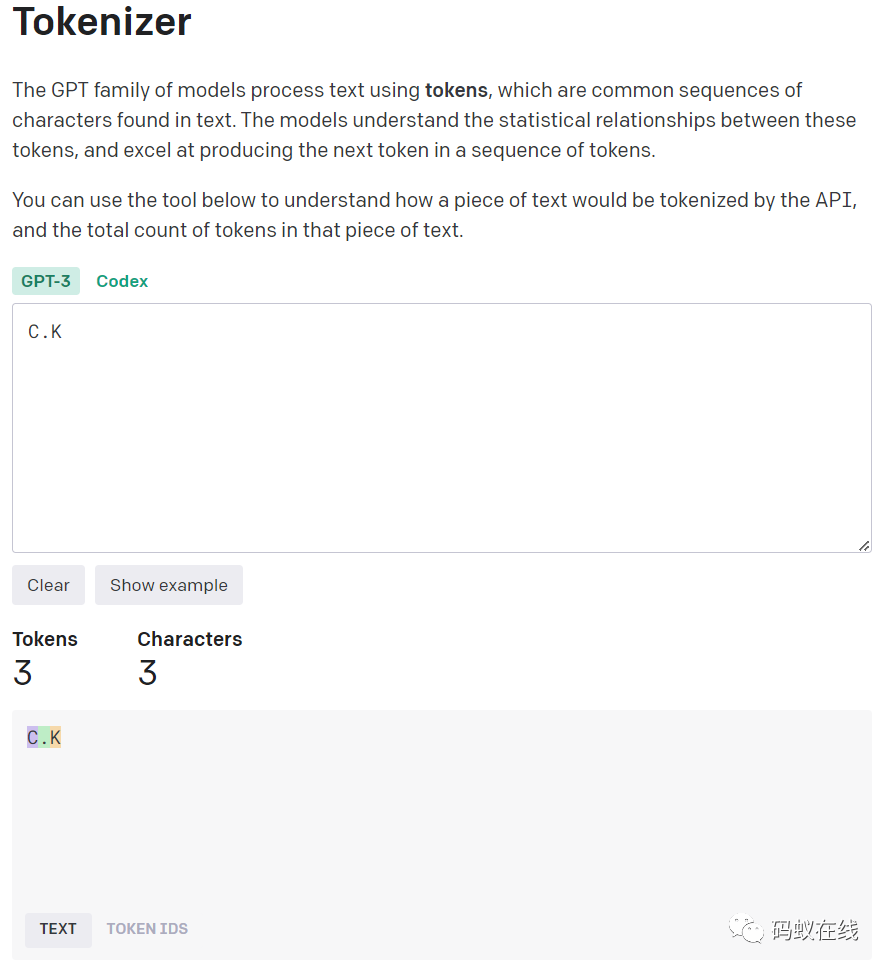
与openAI的Tokenizer对比:
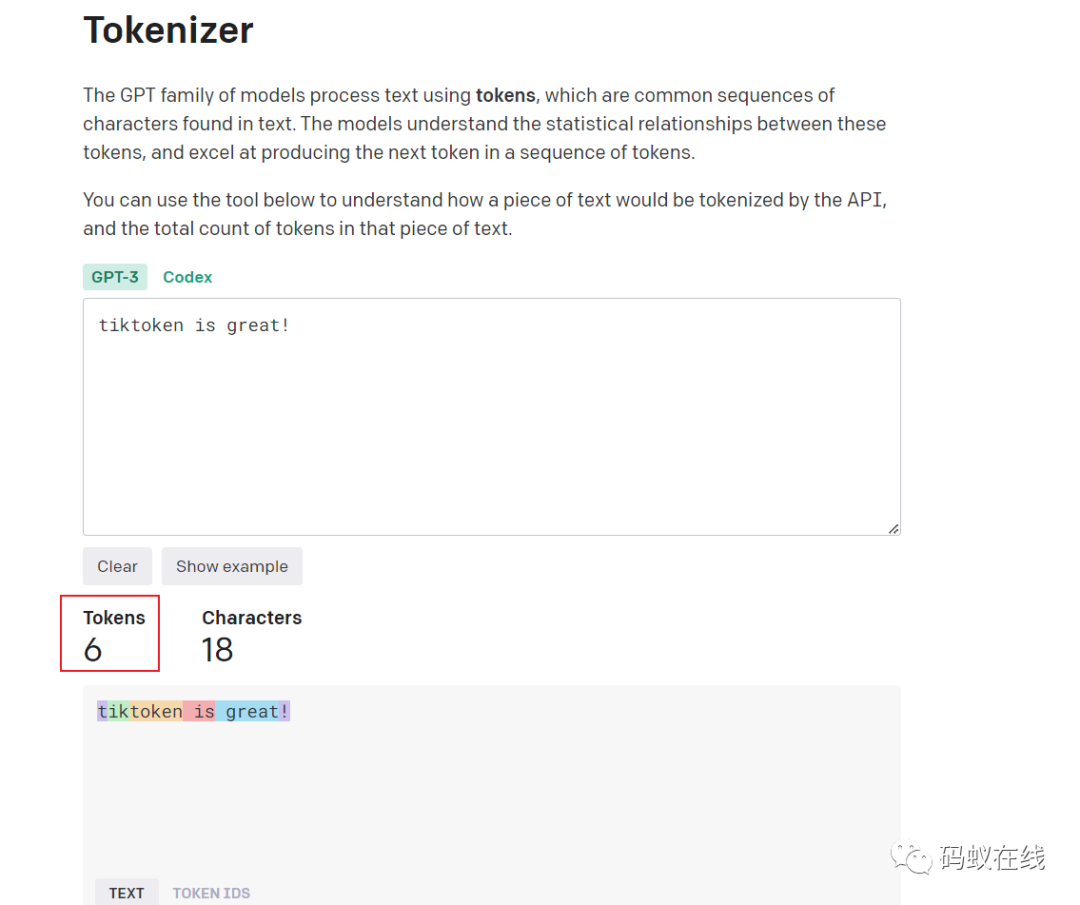
发现18个字符,使用了6个Tokens。
总结:
官网已经有了Tokenizer,可以计算出使用Tokens,而为什么还要写这篇文章来自己计算tokens呢?
将文本字符串拆分成tokens是有价值的,因为GPT模型使用tokens表示文本。了解文本字符串中有多少tokens可以告诉我们:
该字符串是否太长以至于文本模型无法处理;
OpenAI API调用的费用(因为使用费用按token计算)。
最后,想入群ChatGPT嗨玩俱乐部一起抱团学习的欢迎添加我的微信,备注入群ChatGPT。

创作不易,您的关注转发点赞在看是我坚持下来的动力

















 265
265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









